 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuaranteed Guess: A Language Modeling Approach for CISC-to-RISC Transpilation with Testing Guarantees
Jun 17, 2025The hardware ecosystem is rapidly evolving, with increasing interest in translating low-level programs across different instruction set architectures (ISAs) in a quick, flexible, and correct way to enhance the portability and longevity of existing code. A particularly challenging class of this transpilation problem is translating between complex- (CISC) and reduced- (RISC) hardware architectures, due to fundamental differences in instruction complexity, memory models, and execution paradigms. In this work, we introduce GG (Guaranteed Guess), an ISA-centric transpilation pipeline that combines the translation power of pre-trained large language models (LLMs) with the rigor of established software testing constructs. Our method generates candidate translations using an LLM from one ISA to another, and embeds such translations within a software-testing framework to build quantifiable confidence in the translation. We evaluate our GG approach over two diverse datasets, enforce high code coverage (>98%) across unit tests, and achieve functional/semantic correctness of 99% on HumanEval programs and 49% on BringupBench programs, respectively. Further, we compare our approach to the state-of-the-art Rosetta 2 framework on Apple Silicon, showcasing 1.73x faster runtime performance, 1.47x better energy efficiency, and 2.41x better memory usage for our transpiled code, demonstrating the effectiveness of GG for real-world CISC-to-RISC translation tasks. We will open-source our codes, data, models, and benchmarks to establish a common foundation for ISA-level code translation research.
Critical Thinking: Which Kinds of Complexity Govern Optimal Reasoning Length?
Apr 02, 2025Large language models (LLMs) often benefit from verbalized reasoning at inference time, but it remains unclear which aspects of task difficulty these extra reasoning tokens address. To investigate this question, we formalize a framework using deterministic finite automata (DFAs). DFAs offer a formalism through which we can characterize task complexity through measurable properties such as run length (number of reasoning steps required) and state-space size (decision complexity). We first show that across different tasks and models of different sizes and training paradigms, there exists an optimal amount of reasoning tokens such that the probability of producing a correct solution is maximized. We then investigate which properties of complexity govern this critical length: we find that task instances with longer corresponding underlying DFA runs (i.e. demand greater latent state-tracking requirements) correlate with longer reasoning lengths, but, surprisingly, that DFA size (i.e. state-space complexity) does not. We then demonstrate an implication of these findings: being able to predict the optimal number of reasoning tokens for new problems and filtering out non-optimal length answers results in consistent accuracy improvements.
Commit0: Library Generation from Scratch
Dec 02, 2024With the goal of benchmarking generative systems beyond expert software development ability, we introduce Commit0, a benchmark that challenges AI agents to write libraries from scratch. Agents are provided with a specification document outlining the library's API as well as a suite of interactive unit tests, with the goal of producing an implementation of this API accordingly. The implementation is validated through running these unit tests. As a benchmark, Commit0 is designed to move beyond static one-shot code generation towards agents that must process long-form natural language specifications, adapt to multi-stage feedback, and generate code with complex dependencies. Commit0 also offers an interactive environment where models receive static analysis and execution feedback on the code they generate. Our experiments demonstrate that while current agents can pass some unit tests, none can yet fully reproduce full libraries. Results also show that interactive feedback is quite useful for models to generate code that passes more unit tests, validating the benchmarks that facilitate its use.
The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?
Feb 29, 2024While language models are increasingly more proficient at code generation, they still frequently generate incorrect programs. Many of these programs are obviously wrong, but others are more subtle and pass weaker correctness checks such as being able to compile. In this work, we focus on these counterfeit samples: programs sampled from a language model that 1) have a high enough log-probability to be generated at a moderate temperature and 2) pass weak correctness checks. Overall, we discover that most models have a very shallow understanding of counterfeits through three clear failure modes. First, models mistakenly classify them as correct. Second, models are worse at reasoning about the execution behaviour of counterfeits and often predict their execution results as if they were correct. Third, when asking models to fix counterfeits, the likelihood of a model successfully repairing a counterfeit is often even lower than that of sampling a correct program from scratch. Counterfeits also have very unexpected properties: first, counterfeit programs for problems that are easier for a model to solve are not necessarily easier to detect and only slightly easier to execute and repair. Second, counterfeits from a given model are just as confusing to the model itself as they are to other models. Finally, both strong and weak models are able to generate counterfeit samples that equally challenge all models. In light of our findings, we recommend that care and caution be taken when relying on models to understand their own samples, especially when no external feedback is incorporated.
Guess & Sketch: Language Model Guided Transpilation
Sep 25, 2023



Maintaining legacy software requires many software and systems engineering hours. Assembly code programs, which demand low-level control over the computer machine state and have no variable names, are particularly difficult for humans to analyze. Existing conventional program translators guarantee correctness, but are hand-engineered for the source and target programming languages in question. Learned transpilation, i.e. automatic translation of code, offers an alternative to manual re-writing and engineering efforts. Automated symbolic program translation approaches guarantee correctness but struggle to scale to longer programs due to the exponentially large search space. Their rigid rule-based systems also limit their expressivity, so they can only reason about a reduced space of programs. Probabilistic neural language models (LMs) produce plausible outputs for every input, but do so at the cost of guaranteed correctness. In this work, we leverage the strengths of LMs and symbolic solvers in a neurosymbolic approach to learned transpilation for assembly code. Assembly code is an appropriate setting for a neurosymbolic approach, since assembly code can be divided into shorter non-branching basic blocks amenable to the use of symbolic methods. Guess & Sketch extracts alignment and confidence information from features of the LM then passes it to a symbolic solver to resolve semantic equivalence of the transpilation input and output. We test Guess & Sketch on three different test sets of assembly transpilation tasks, varying in difficulty, and show that it successfully transpiles 57.6% more examples than GPT-4 and 39.6% more examples than an engineered transpiler. We also share a training and evaluation dataset for this task.
Mixture of Soft Prompts for Controllable Data Generation
Mar 02, 2023



Large language models (LLMs) effectively generate fluent text when the target output follows natural language patterns. However, structured prediction tasks confine the output format to a limited ontology, causing even very large models to struggle since they were never trained with such restrictions in mind. The difficulty of using LLMs for direct prediction is exacerbated in few-shot learning scenarios, which commonly arise due to domain shift and resource limitations. We flip the problem on its head by leveraging the LLM as a tool for data augmentation rather than direct prediction. Our proposed Mixture of Soft Prompts (MSP) serves as a parameter-efficient procedure for generating data in a controlled manner. Denoising mechanisms are further applied to improve the quality of synthesized data. Automatic metrics show our method is capable of producing diverse and natural text, while preserving label semantics. Moreover, MSP achieves state-of-the-art results on three benchmarks when compared against strong baselines. Our method offers an alternate data-centric approach for applying LLMs to complex prediction tasks.
Toward Code Generation: A Survey and Lessons from Semantic Parsing
Apr 26, 2021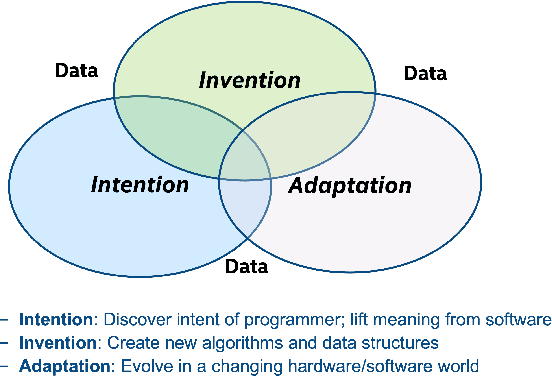

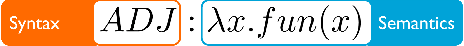
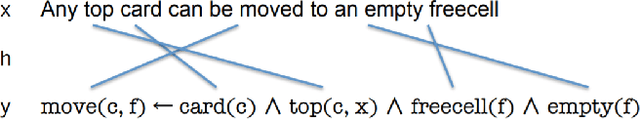
With the growth of natural language processing techniques and demand for improved software engineering efficiency, there is an emerging interest in translating intention from human languages to programming languages. In this survey paper, we attempt to provide an overview of the growing body of research in this space. We begin by reviewing natural language semantic parsing techniques and draw parallels with program synthesis efforts. We then consider semantic parsing works from an evolutionary perspective, with specific analyses on neuro-symbolic methods, architecture, and supervision. We then analyze advancements in frameworks for semantic parsing for code generation. In closing, we present what we believe are some of the emerging open challenges in this domain.