 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Programs with Continuous Optimization
Nov 02, 2022



Automatic software generation based on some specification is known as program synthesis. Most existing approaches formulate program synthesis as a search problem with discrete parameters. In this paper, we present a novel formulation of program synthesis as a continuous optimization problem and use a state-of-the-art evolutionary approach, known as Covariance Matrix Adaptation Evolution Strategy to solve the problem. We then propose a mapping scheme to convert the continuous formulation into actual programs. We compare our system, called GENESYS, with several recent program synthesis techniques (in both discrete and continuous domains) and show that GENESYS synthesizes more programs within a fixed time budget than those existing schemes. For example, for programs of length 10, GENESYS synthesizes 28% more programs than those existing schemes within the same time budget.
Simulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021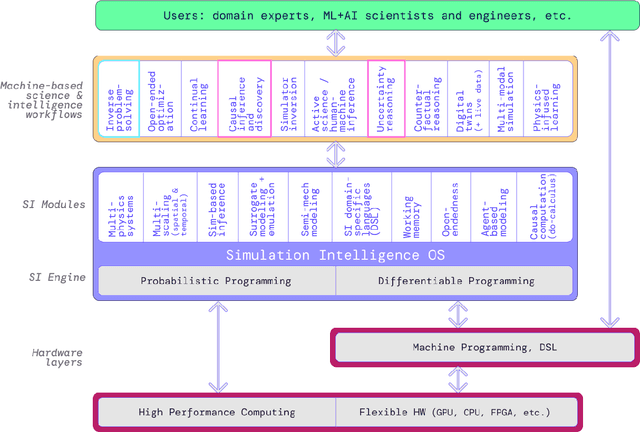
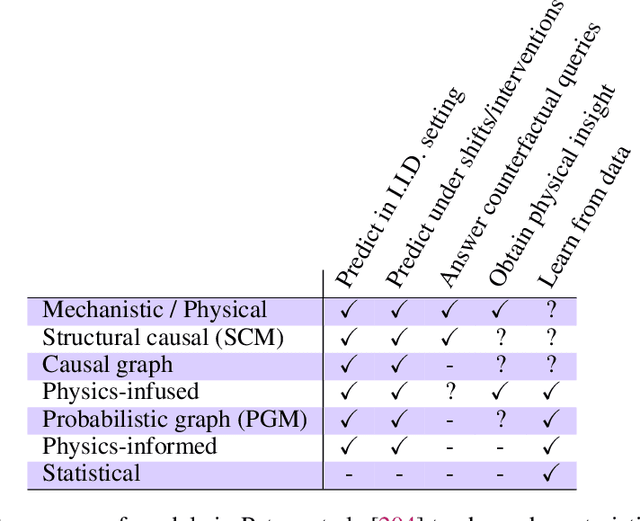
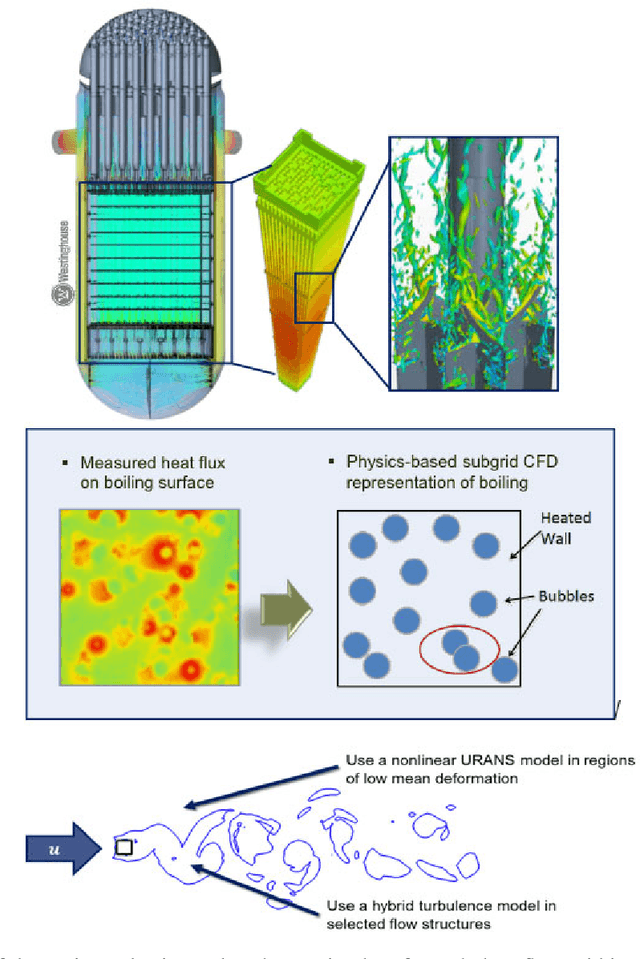
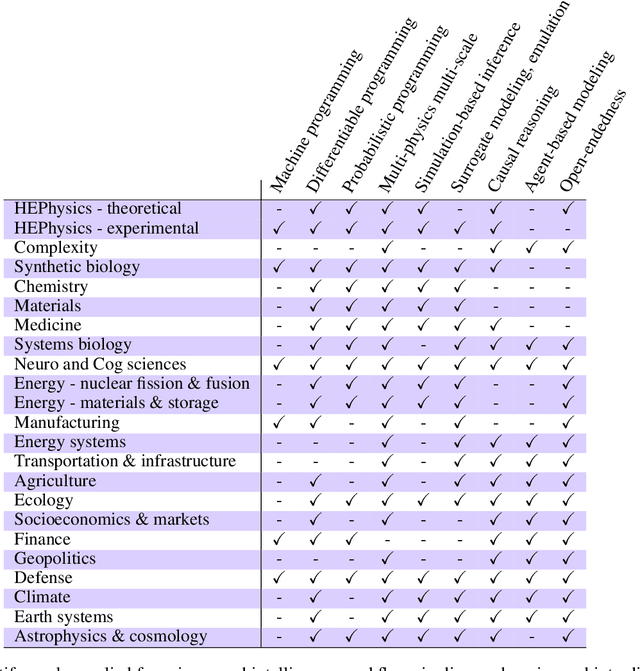
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
Toward Code Generation: A Survey and Lessons from Semantic Parsing
Apr 26, 2021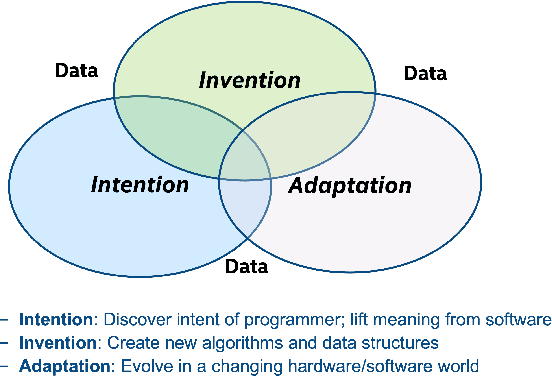

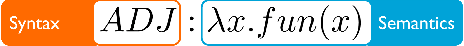
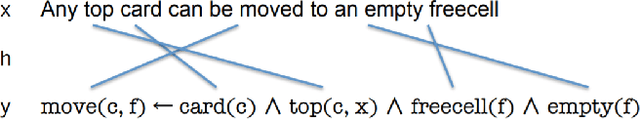
With the growth of natural language processing techniques and demand for improved software engineering efficiency, there is an emerging interest in translating intention from human languages to programming languages. In this survey paper, we attempt to provide an overview of the growing body of research in this space. We begin by reviewing natural language semantic parsing techniques and draw parallels with program synthesis efforts. We then consider semantic parsing works from an evolutionary perspective, with specific analyses on neuro-symbolic methods, architecture, and supervision. We then analyze advancements in frameworks for semantic parsing for code generation. In closing, we present what we believe are some of the emerging open challenges in this domain.
ControlFlag: A Self-supervised Idiosyncratic Pattern Detection System for Software Control Structures
Nov 06, 2020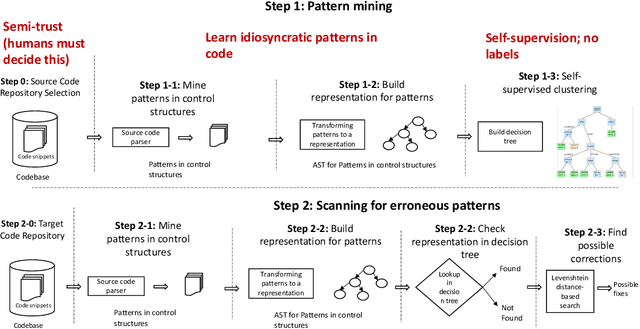

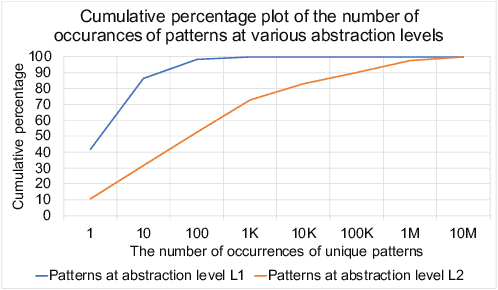

Software debugging has been shown to utilize upwards of 50% of developers' time. Machine programming, the field concerned with the automation of software (and hardware) development, has recently made progress in both research and production-quality automated debugging systems. In this paper, we present ControlFlag, a system that detects possible idiosyncratic violations in software control structures. ControlFlag also suggests possible corrections in the event a true error is detected. A novelty of ControlFlag is that it is entirely self-supervised; that is, it requires no labels to learn about the potential idiosyncratic programming pattern violations. In addition to presenting ControlFlag's design, we also provide an abbreviated experimental evaluation.
Class-Weighted Evaluation Metrics for Imbalanced Data Classification
Oct 12, 2020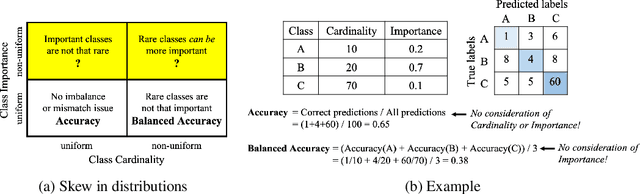
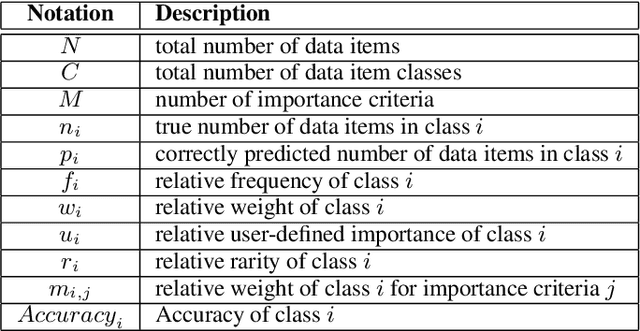
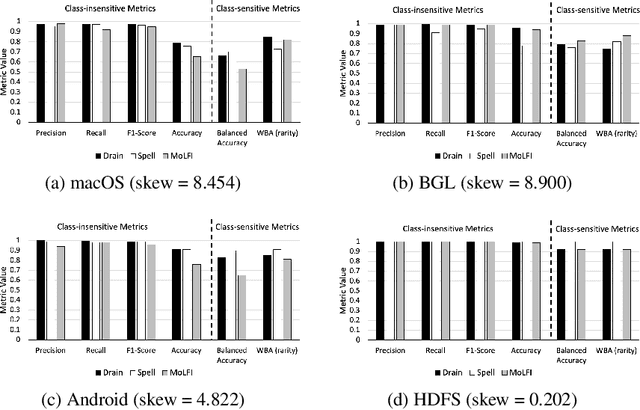
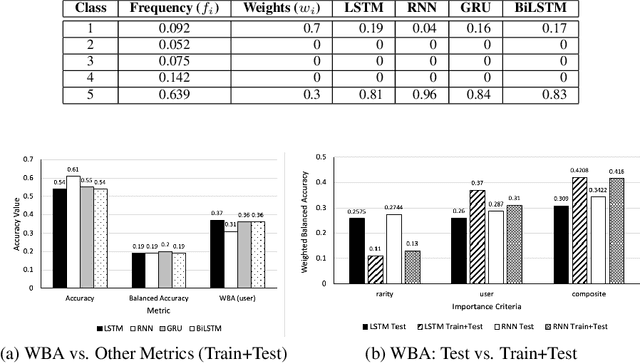
Class distribution skews in imbalanced datasets may lead to models with prediction bias towards majority classes, making fair assessment of classifiers a challenging task. Balanced Accuracy is a popular metric used to evaluate a classifier's prediction performance under such scenarios. However, this metric falls short when classes vary in importance, especially when class importance is skewed differently from class cardinality distributions. In this paper, we propose a simple and general-purpose evaluation framework for imbalanced data classification that is sensitive to arbitrary skews in class cardinalities and importances. Experiments with several state-of-the-art classifiers tested on real-world datasets and benchmarks from two different domains show that our new framework is more effective than Balanced Accuracy -- not only in evaluating and ranking model predictions, but also in training the models themselves.
MISIM: An End-to-End Neural Code Similarity System
Jun 15, 2020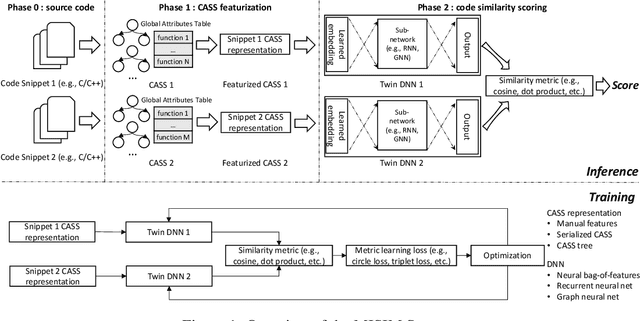
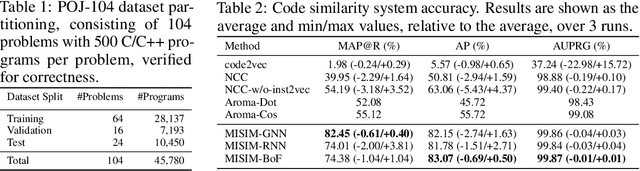
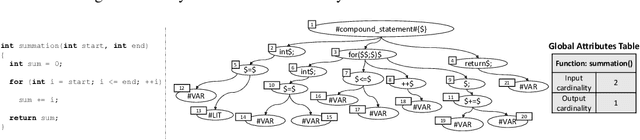
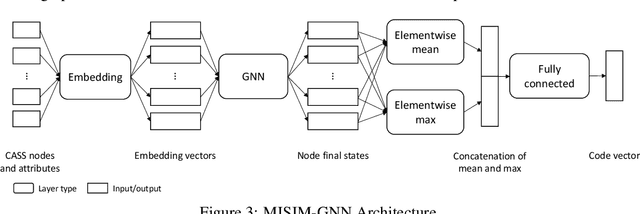
Code similarity systems are integral to a range of applications from code recommendation to automated construction of software tests and defect mitigation. In this paper, we present Machine Inferred Code Similarity (MISIM), a novel end-to-end code similarity system that consists of two core components. First, MISIM uses a novel context-aware similarity structure, which is designed to aid in lifting semantic meaning from code syntax. Second, MISIM provides a neural-based code similarity scoring system, which can be implemented with various neural network algorithms and topologies with learned parameters. We compare MISIM to three other state-of-the-art code similarity systems: (i) code2vec, (ii) Neural Code Comprehension, and (iii) Aroma. In our experimental evaluation across 45,780 programs, MISIM consistently outperformed all three systems, often by a large factor (upwards of 40.6x).
Software Language Comprehension using a Program-Derived Semantic Graph
Apr 03, 2020

Traditional code transformation structures, such as an abstract syntax tree, may have limitations in their ability to extract semantic meaning from code. Others have begun to work on this issue, such as the state-of-the-art Aroma system and its simplified parse tree (SPT). Continuing this research direction, we present a new graphical structure to capture semantics from code using what we refer to as a program-derived semantic graph (PSG). The principle behind the PSG is to provide a single structure that can capture program semantics at many levels of granularity. Thus, the PSG is hierarchical in nature. Moreover, because the PSG may have cycles due to dependencies in semantic layers, it is a graph, not a tree. In this paper, we describe the PSG and its fundamental structural differences to the Aroma's SPT. Although our work in the PSG is in its infancy, our early results indicate it is a promising new research direction to explore to automatically extract program semantics.
Context-Aware Parse Trees
Mar 24, 2020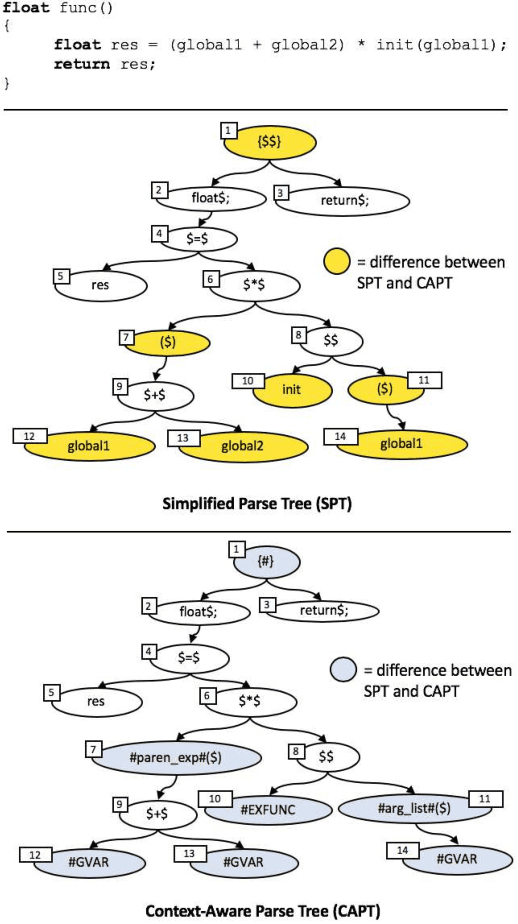
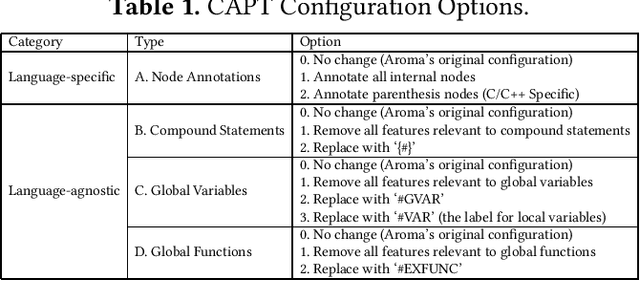
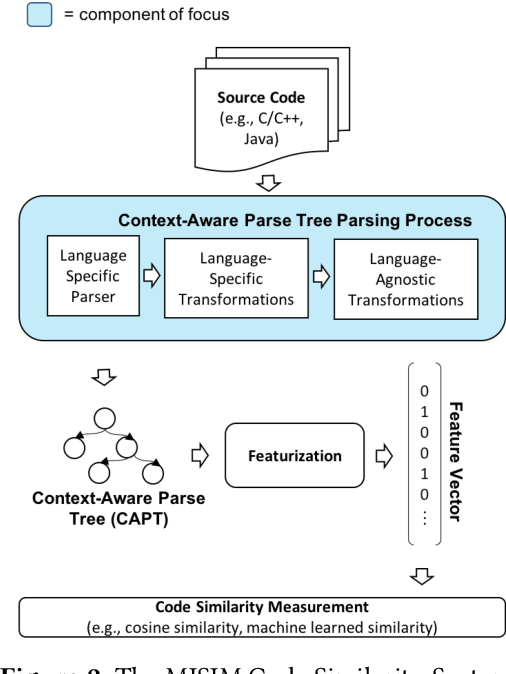
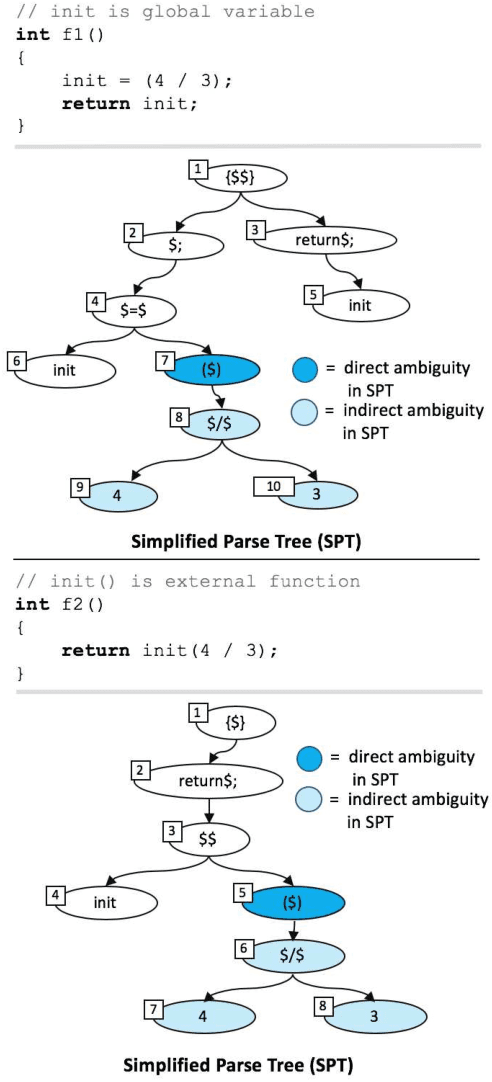
The simplified parse tree (SPT) presented in Aroma, a state-of-the-art code recommendation system, is a tree-structured representation used to infer code semantics by capturing program \emph{structure} rather than program \emph{syntax}. This is a departure from the classical abstract syntax tree, which is principally driven by programming language syntax. While we believe a semantics-driven representation is desirable, the specifics of an SPT's construction can impact its performance. We analyze these nuances and present a new tree structure, heavily influenced by Aroma's SPT, called a \emph{context-aware parse tree} (CAPT). CAPT enhances SPT by providing a richer level of semantic representation. Specifically, CAPT provides additional binding support for language-specific techniques for adding semantically-salient features, and language-agnostic techniques for removing syntactically-present but semantically-irrelevant features. Our research quantitatively demonstrates the value of our proposed semantically-salient features, enabling a specific CAPT configuration to be 39\% more accurate than SPT across the 48,610 programs we analyzed.
An Abstraction-Based Framework for Neural Network Verification
Oct 31, 2019
Deep neural networks are increasingly being used as controllers for safety-critical systems. Because neural networks are opaque, certifying their correctness is a significant challenge. To address this issue, several approaches have recently been proposed to formally verify them. However, network size is often a bottleneck for such approaches and it can be difficult to apply them to large networks. In this paper, we propose a framework that can enhance neural network verification techniques by using over-approximation to reduce the size of the network - thus making it more amenable to verification. We perform the approximation such that if the property holds for the smaller (abstract) network, it holds for the original as well. The over-approximation may be too coarse, in which case the underlying verification tool might return a spurious counterexample. Under such conditions, we perform counterexample-guided refinement to adjust the approximation, and then repeat the process. Our approach is orthogonal to, and can be integrated with, many existing verification techniques. For evaluation purposes, we integrate it with the recently proposed Marabou framework, and observe a significant improvement in Marabou's performance. Our experiments demonstrate the great potential of our approach for verifying larger neural networks.
Learning Fitness Functions for Genetic Algorithms
Sep 10, 2019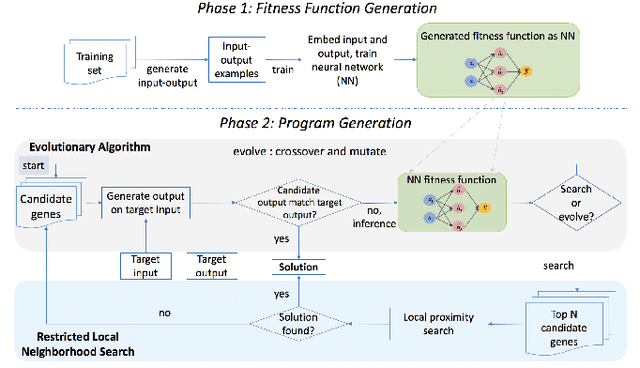
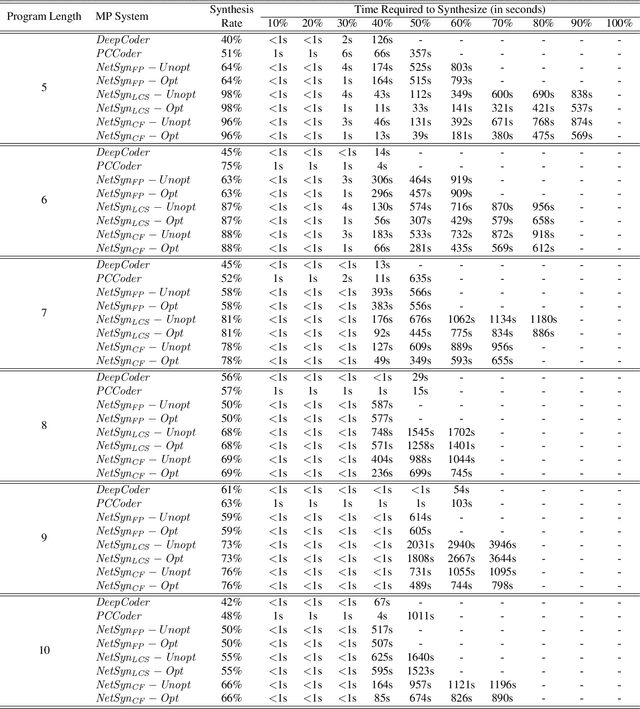
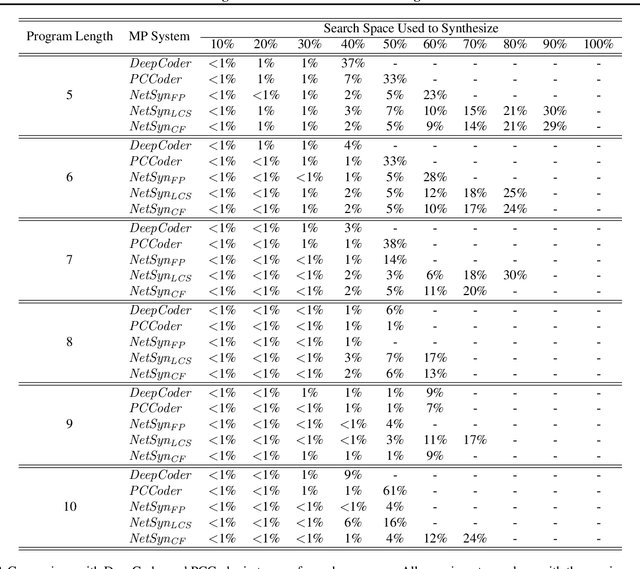
A genetic algorithm (GA) attempts to solve a problem using a pool of potential solutions that are iteratively refined using various selection techniques. Although GAs have been used successfully for many problems, one criticism is that hand-crafting a GA's fitness function, the test that aims to effectively guide its evolution, can be notably challenging. Moreover, the complexity of a GA's fitness function tends to grow proportionally with the complexity of the problem being solved. In this work, we present a novel approach to learn a GA's fitness function. For the purpose of simplicity, we limit the demonstration of this technique to automatic software program generation. However, our system has no specific restrictions that prevent it from being applied to other domains. We also augment the GA evolutionary process with a minimally intrusive search heuristic. This heuristic improves the GA's ability to discover correct programs from ones that are approximately correct and does so with negligible computational overhead. We compare our approach to two state-of-the-art program generation systems and demonstrate that it finds more correct programs with fewer candidate program generations.