 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Gradient Prediction for DNN Training
May 22, 2023



Neural network training is inherently sequential where the layers finish the forward propagation in succession, followed by the calculation and back-propagation of gradients (based on a loss function) starting from the last layer. The sequential computations significantly slow down neural network training, especially the deeper ones. Prediction has been successfully used in many areas of computer architecture to speed up sequential processing. Therefore, we propose ADA-GP, that uses gradient prediction adaptively to speed up deep neural network (DNN) training while maintaining accuracy. ADA-GP works by incorporating a small neural network to predict gradients for different layers of a DNN model. ADA-GP uses a novel tensor reorganization to make it feasible to predict a large number of gradients. ADA-GP alternates between DNN training using backpropagated gradients and DNN training using predicted gradients. ADA-GP adaptively adjusts when and for how long gradient prediction is used to strike a balance between accuracy and performance. Last but not least, we provide a detailed hardware extension in a typical DNN accelerator to realize the speed up potential from gradient prediction. Our extensive experiments with fourteen DNN models show that ADA-GP can achieve an average speed up of 1.47x with similar or even higher accuracy than the baseline models. Moreover, it consumes, on average, 34% less energy due to reduced off-chip memory accesses compared to the baseline hardware accelerator.
Large Language Models Based Automatic Synthesis of Software Specifications
Apr 18, 2023Software configurations play a crucial role in determining the behavior of software systems. In order to ensure safe and error-free operation, it is necessary to identify the correct configuration, along with their valid bounds and rules, which are commonly referred to as software specifications. As software systems grow in complexity and scale, the number of configurations and associated specifications required to ensure the correct operation can become large and prohibitively difficult to manipulate manually. Due to the fast pace of software development, it is often the case that correct software specifications are not thoroughly checked or validated within the software itself. Rather, they are frequently discussed and documented in a variety of external sources, including software manuals, code comments, and online discussion forums. Therefore, it is hard for the system administrator to know the correct specifications of configurations due to the lack of clarity, organization, and a centralized unified source to look at. To address this challenge, we propose SpecSyn a framework that leverages a state-of-the-art large language model to automatically synthesize software specifications from natural language sources. Our approach formulates software specification synthesis as a sequence-to-sequence learning problem and investigates the extraction of specifications from large contextual texts. This is the first work that uses a large language model for end-to-end specification synthesis from natural language texts. Empirical results demonstrate that our system outperforms prior the state-of-the-art specification synthesis tool by 21% in terms of F1 score and can find specifications from single as well as multiple sentences.
Synthesizing Programs with Continuous Optimization
Nov 02, 2022



Automatic software generation based on some specification is known as program synthesis. Most existing approaches formulate program synthesis as a search problem with discrete parameters. In this paper, we present a novel formulation of program synthesis as a continuous optimization problem and use a state-of-the-art evolutionary approach, known as Covariance Matrix Adaptation Evolution Strategy to solve the problem. We then propose a mapping scheme to convert the continuous formulation into actual programs. We compare our system, called GENESYS, with several recent program synthesis techniques (in both discrete and continuous domains) and show that GENESYS synthesizes more programs within a fixed time budget than those existing schemes. For example, for programs of length 10, GENESYS synthesizes 28% more programs than those existing schemes within the same time budget.
SIMCNN -- Exploiting Computational Similarity to Accelerate CNN Training in Hardware
Oct 28, 2021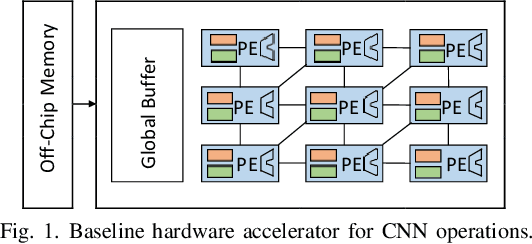


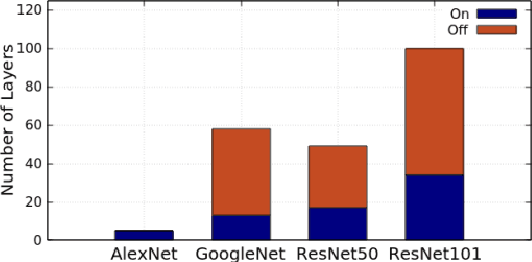
Convolution neural networks (CNN) are computation intensive to train. It consists of a substantial number of multidimensional dot products between many kernels and inputs. We observe that there are notable similarities among the vectors extracted from inputs (i.e., input vectors). If one input vector is similar to another one, its computations with the kernels are also similar to those of the other and therefore, can be skipped by reusing the already-computed results. Based on this insight, we propose a novel scheme based on locality sensitive hashing (LSH) to exploit the similarity of computations during CNN training in a hardware accelerator. The proposed scheme, called SIMCNN, uses a cache (SIMCACHE) to store LSH signatures of recent input vectors along with the computed results. If the LSH signature of a new input vector matches with that of an already existing vector in the SIMCACHE, the already-computed result is reused for the new vector. SIMCNN is the first work that exploits computational similarity for accelerating CNN training in hardware. The paper presents a detailed design, workflow, and implementation of SIMCNN. Our experimental evaluation with four different deep learning models shows that SIMCNN saves a significant number of computations and therefore, improves training time up to 43%.
Continual Learning Approach for Improving the Data and Computation Mapping in Near-Memory Processing System
Apr 28, 2021
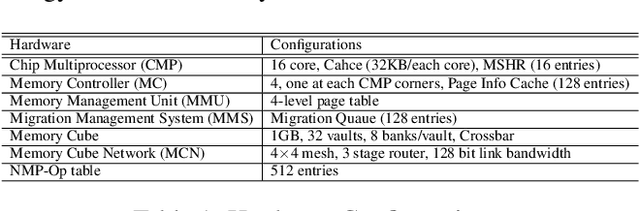
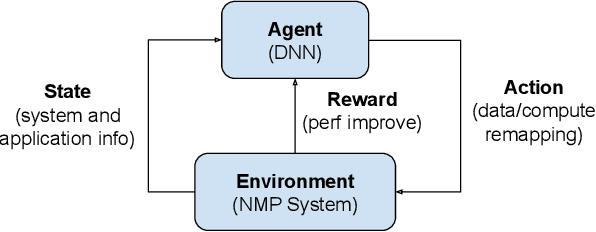
The resurgence of near-memory processing (NMP) with the advent of big data has shifted the computation paradigm from processor-centric to memory-centric computing. To meet the bandwidth and capacity demands of memory-centric computing, 3D memory has been adopted to form a scalable memory-cube network. Along with NMP and memory system development, the mapping for placing data and guiding computation in the memory-cube network has become crucial in driving the performance improvement in NMP. However, it is very challenging to design a universal optimal mapping for all applications due to unique application behavior and intractable decision space. In this paper, we propose an artificially intelligent memory mapping scheme, AIMM, that optimizes data placement and resource utilization through page and computation remapping. Our proposed technique involves continuously evaluating and learning the impact of mapping decisions on system performance for any application. AIMM uses a neural network to achieve a near-optimal mapping during execution, trained using a reinforcement learning algorithm that is known to be effective for exploring a vast design space. We also provide a detailed AIMM hardware design that can be adopted as a plugin module for various NMP systems. Our experimental evaluation shows that AIMM improves the baseline NMP performance in single and multiple program scenario by up to 70% and 50%, respectively.
FORECASTER: A Continual Lifelong Learning Approach to Improve Hardware Efficiency
Apr 27, 2020
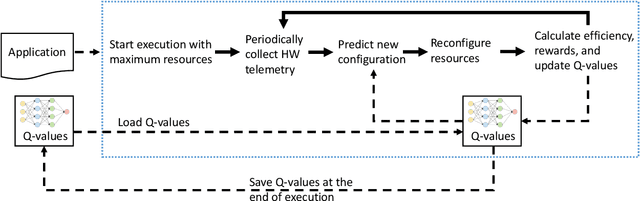
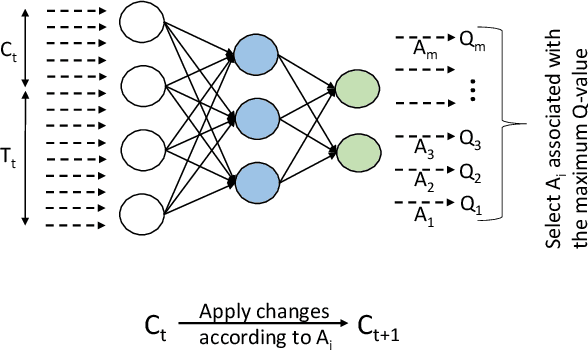
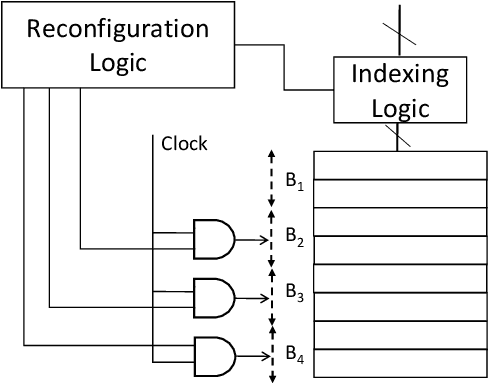
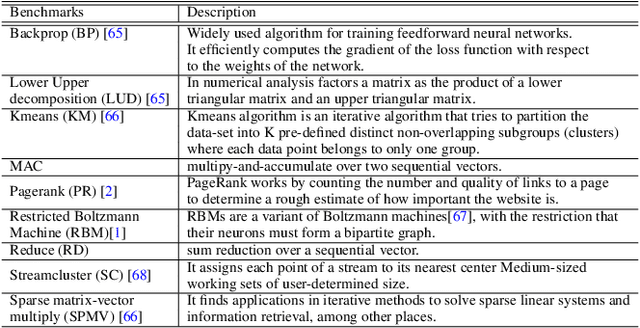
Computer applications are continuously evolving. However, significant knowledge can be harvested from older applications or versions and applied in the context of newer applications or versions. Such a vision can be realized with Continual Lifelong Learning. Therefore, we propose to employ continual lifelong learning to dynamically tune hardware configurations based on application behavior. The goal of such tuning is to maximize hardware efficiency (i.e., maximize an application performance while minimizing the hardware energy consumption). Our proposed approach, FORECASTER, uses deep reinforcement learning to continually learn during the execution of an application as well as propagate and utilize the accumulated knowledge during subsequent executions of the same or new application. We propose a novel hardware and ISA support to implement deep reinforcement learning. We implement FORECASTER and compare its performance against prior learning-based hardware reconfiguration approaches. Our results show that FORECASTER can save an average 16% of system power over the baseline setup with full usage of hardware while sacrificing an average of 4.7% of execution time.
Learning Fitness Functions for Genetic Algorithms
Sep 10, 2019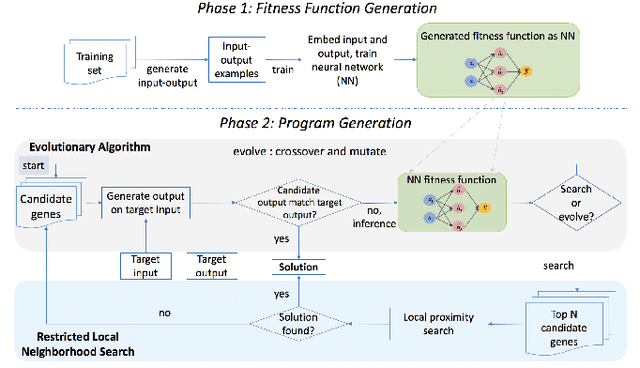
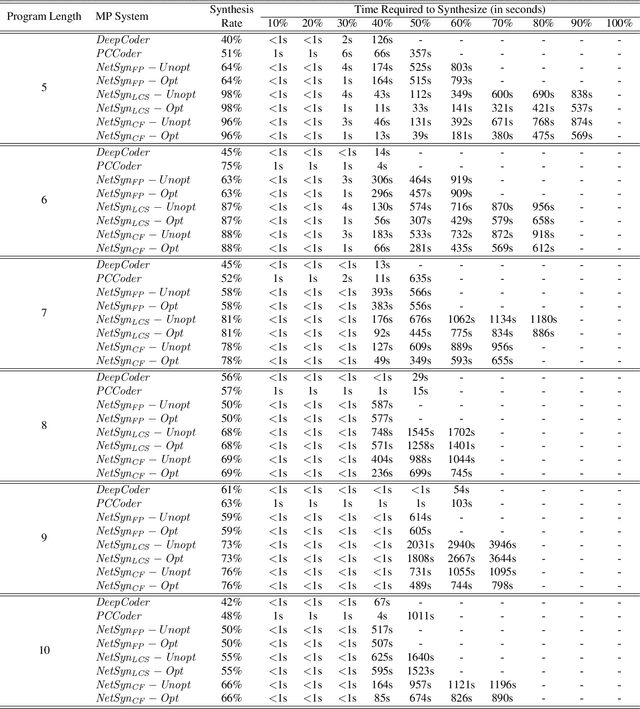
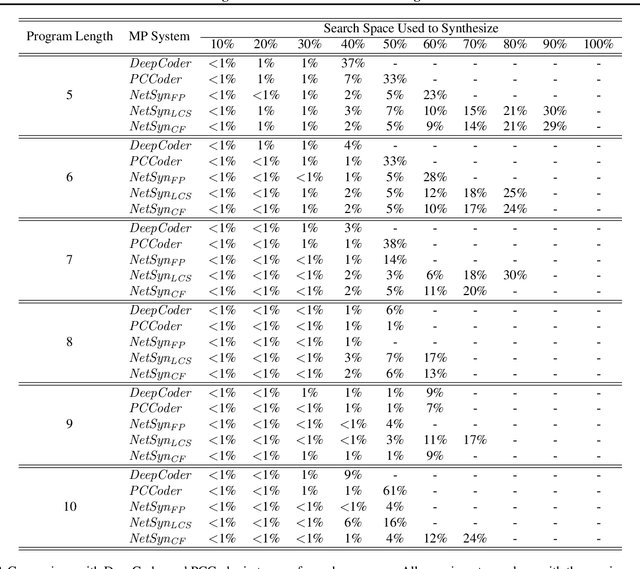
A genetic algorithm (GA) attempts to solve a problem using a pool of potential solutions that are iteratively refined using various selection techniques. Although GAs have been used successfully for many problems, one criticism is that hand-crafting a GA's fitness function, the test that aims to effectively guide its evolution, can be notably challenging. Moreover, the complexity of a GA's fitness function tends to grow proportionally with the complexity of the problem being solved. In this work, we present a novel approach to learn a GA's fitness function. For the purpose of simplicity, we limit the demonstration of this technique to automatic software program generation. However, our system has no specific restrictions that prevent it from being applied to other domains. We also augment the GA evolutionary process with a minimally intrusive search heuristic. This heuristic improves the GA's ability to discover correct programs from ones that are approximately correct and does so with negligible computational overhead. We compare our approach to two state-of-the-art program generation systems and demonstrate that it finds more correct programs with fewer candidate program generations.
AutoPerf: A Generalized Zero-Positive Learning System to Detect Software Performance Anomalies
Nov 19, 2017
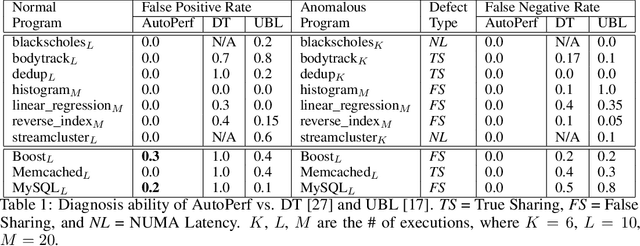
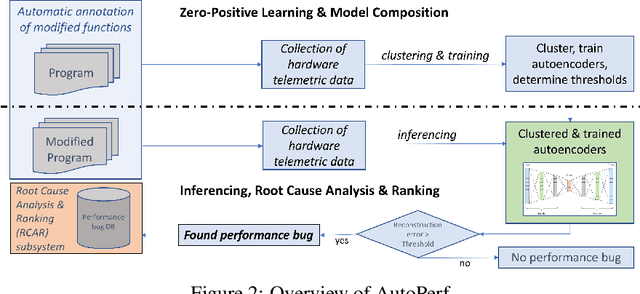

In this paper, we present AutoPerf, a generalized software performance anomaly detection system. AutoPerf uses autoencoders, an unsupervised learning technique, and hardware performance counters to learn the performance signatures of parallel programs. It then uses this knowledge to identify when newer versions of the program suffer performance penalties, while simultaneously providing root cause analysis to help programmers debug the program's performance. AutoPerf is the first zero-positive learning performance anomaly detector, a system that trains entirely in the negative (non-anomalous) space to learn positive (anomalous) behaviors. We demonstrate AutoPerf's generality against three different types of performance anomalies: (i) true sharing cache contention, (ii) false sharing cache contention, and (iii) NUMA latencies across 15 real world performance anomalies and 7 open source programs. AutoPerf has only 3.7% profiling overhead (on average) and detects more anomalies than the prior state-of-the-art approach.