 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Episodic Memory is the Missing Piece for Long-Term LLM Agents
Feb 10, 2025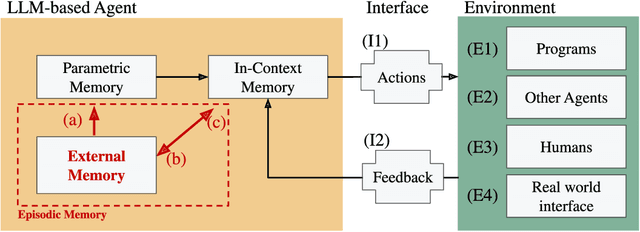

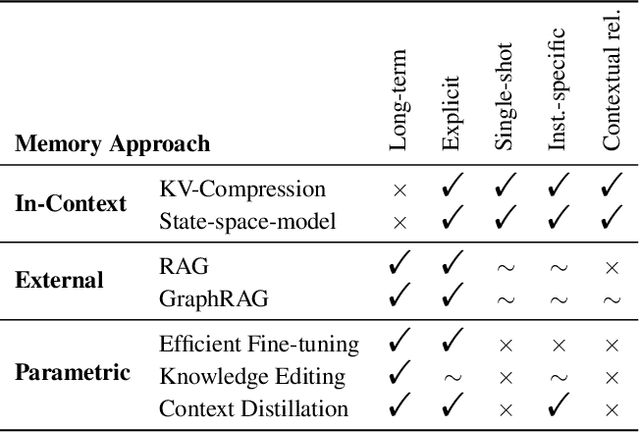
As Large Language Models (LLMs) evolve from text-completion tools into fully fledged agents operating in dynamic environments, they must address the challenge of continually learning and retaining long-term knowledge. Many biological systems solve these challenges with episodic memory, which supports single-shot learning of instance-specific contexts. Inspired by this, we present an episodic memory framework for LLM agents, centered around five key properties of episodic memory that underlie adaptive and context-sensitive behavior. With various research efforts already partially covering these properties, this position paper argues that now is the right time for an explicit, integrated focus on episodic memory to catalyze the development of long-term agents. To this end, we outline a roadmap that unites several research directions under the goal to support all five properties of episodic memory for more efficient long-term LLM agents.
On the Challenges of Creating Datasets for Analyzing Commercial Sex Advertisements to Assess Human Trafficking Risk and Organized Activity
May 22, 2024



Our study addresses the challenges of building datasets to understand the risks associated with organized activities and human trafficking through commercial sex advertisements. These challenges include data scarcity, rapid obsolescence, and privacy concerns. Traditional approaches, which are not automated and are difficult to reproduce, fall short in addressing these issues. We have developed a reproducible and automated methodology to analyze five million advertisements. In the process, we identified further challenges in dataset creation within this sensitive domain. This paper presents a streamlined methodology to assist researchers in constructing effective datasets for combating organized crime, allowing them to focus on advancing detection technologies.
Humans and language models diverge when predicting repeating text
Oct 23, 2023Language models that are trained on the next-word prediction task have been shown to accurately model human behavior in word prediction and reading speed. In contrast with these findings, we present a scenario in which the performance of humans and LMs diverges. We collected a dataset of human next-word predictions for five stimuli that are formed by repeating spans of text. Human and GPT-2 LM predictions are strongly aligned in the first presentation of a text span, but their performance quickly diverges when memory (or in-context learning) begins to play a role. We traced the cause of this divergence to specific attention heads in a middle layer. Adding a power-law recency bias to these attention heads yielded a model that performs much more similarly to humans. We hope that this scenario will spur future work in bringing LMs closer to human behavior.
Large Language Models Based Automatic Synthesis of Software Specifications
Apr 18, 2023Software configurations play a crucial role in determining the behavior of software systems. In order to ensure safe and error-free operation, it is necessary to identify the correct configuration, along with their valid bounds and rules, which are commonly referred to as software specifications. As software systems grow in complexity and scale, the number of configurations and associated specifications required to ensure the correct operation can become large and prohibitively difficult to manipulate manually. Due to the fast pace of software development, it is often the case that correct software specifications are not thoroughly checked or validated within the software itself. Rather, they are frequently discussed and documented in a variety of external sources, including software manuals, code comments, and online discussion forums. Therefore, it is hard for the system administrator to know the correct specifications of configurations due to the lack of clarity, organization, and a centralized unified source to look at. To address this challenge, we propose SpecSyn a framework that leverages a state-of-the-art large language model to automatically synthesize software specifications from natural language sources. Our approach formulates software specification synthesis as a sequence-to-sequence learning problem and investigates the extraction of specifications from large contextual texts. This is the first work that uses a large language model for end-to-end specification synthesis from natural language texts. Empirical results demonstrate that our system outperforms prior the state-of-the-art specification synthesis tool by 21% in terms of F1 score and can find specifications from single as well as multiple sentences.
Synthesizing Programs with Continuous Optimization
Nov 02, 2022



Automatic software generation based on some specification is known as program synthesis. Most existing approaches formulate program synthesis as a search problem with discrete parameters. In this paper, we present a novel formulation of program synthesis as a continuous optimization problem and use a state-of-the-art evolutionary approach, known as Covariance Matrix Adaptation Evolution Strategy to solve the problem. We then propose a mapping scheme to convert the continuous formulation into actual programs. We compare our system, called GENESYS, with several recent program synthesis techniques (in both discrete and continuous domains) and show that GENESYS synthesizes more programs within a fixed time budget than those existing schemes. For example, for programs of length 10, GENESYS synthesizes 28% more programs than those existing schemes within the same time budget.
Low-Dimensional Structure in the Space of Language Representations is Reflected in Brain Responses
Jun 15, 2021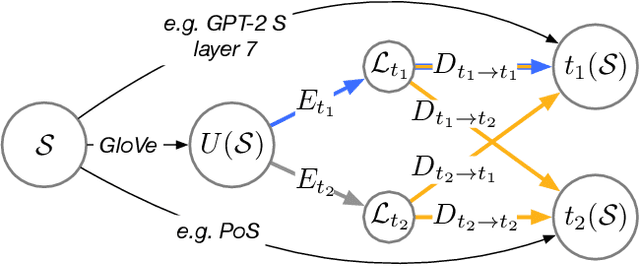
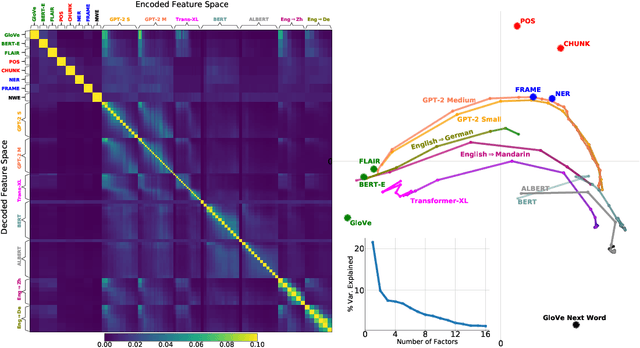
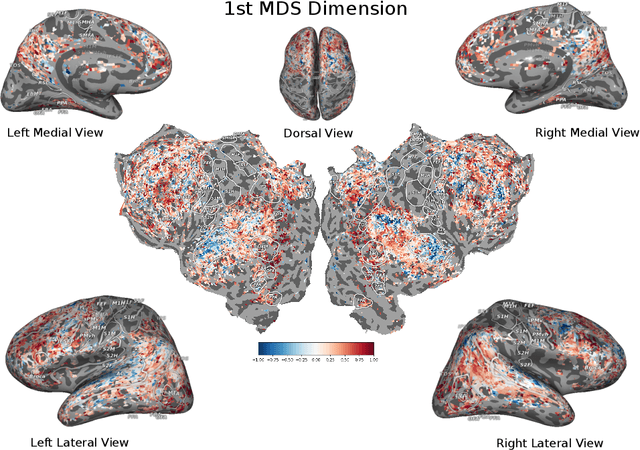
How related are the representations learned by neural language models, translation models, and language tagging tasks? We answer this question by adapting an encoder-decoder transfer learning method from computer vision to investigate the structure among 100 different feature spaces extracted from hidden representations of various networks trained on language tasks. This method reveals a low-dimensional structure where language models and translation models smoothly interpolate between word embeddings, syntactic and semantic tasks, and future word embeddings. We call this low-dimensional structure a language representation embedding because it encodes the relationships between representations needed to process language for a variety of NLP tasks. We find that this representation embedding can predict how well each individual feature space maps to human brain responses to natural language stimuli recorded using fMRI. Additionally, we find that the principal dimension of this structure can be used to create a metric which highlights the brain's natural language processing hierarchy. This suggests that the embedding captures some part of the brain's natural language representation structure.
Selecting Informative Contexts Improves Language Model Finetuning
May 01, 2020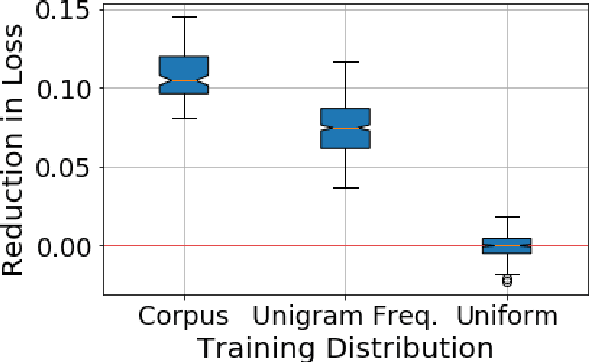
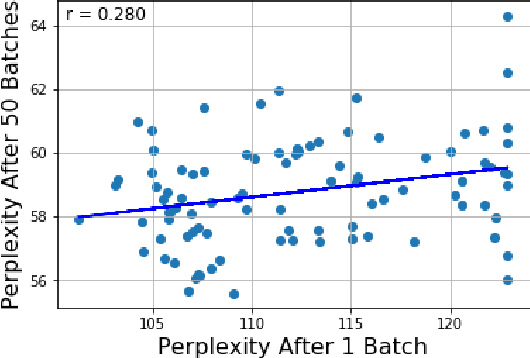
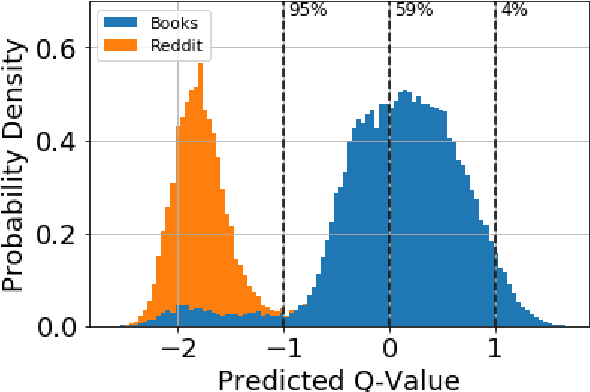
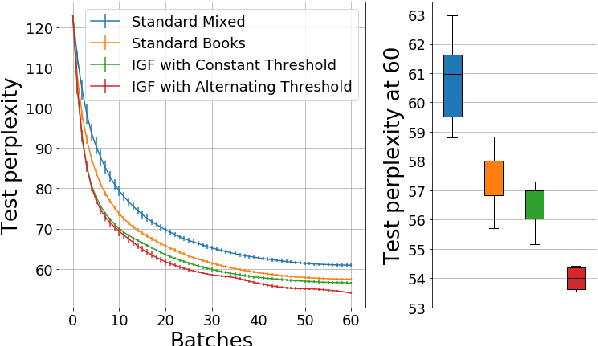
We present a general finetuning meta-method that we call information gain filtration for improving the overall training efficiency and final performance of language model finetuning. This method uses a secondary learner which attempts to quantify the benefit of finetuning the language model on each given example. During the finetuning process, we use this learner to decide whether or not each given example should be trained on or skipped. We show that it suffices for this learner to be simple and that the finetuning process itself is dominated by the relatively trivial relearning of a new unigram frequency distribution over the modelled language domain, a process which the learner aids. Our method trains to convergence using 40% fewer batches than normal finetuning, and achieves a median perplexity of 54.0 on a books dataset compared to a median perplexity of 57.3 for standard finetuning using the same neural architecture.
On MMSE and MAP Denoising Under Sparse Representation Modeling Over a Unitary Dictionary
Mar 21, 2010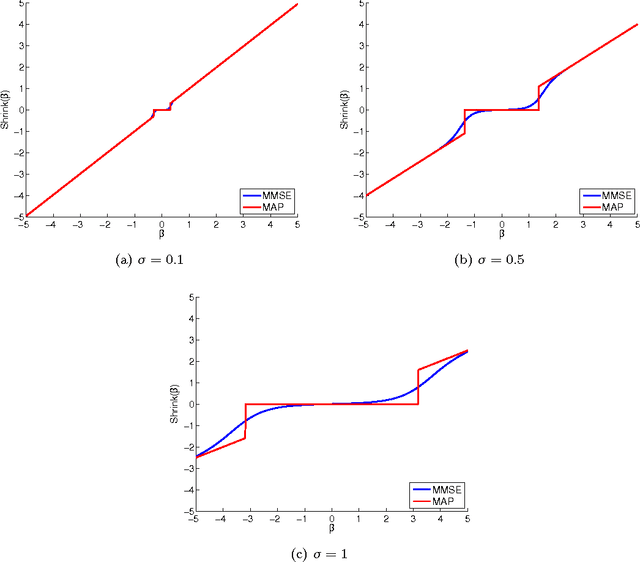
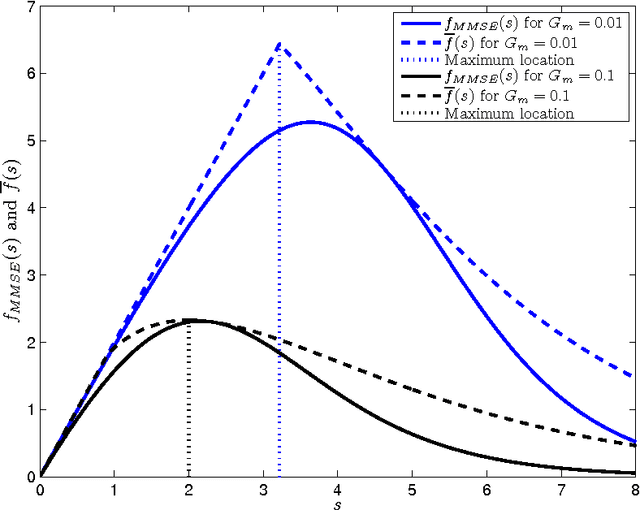
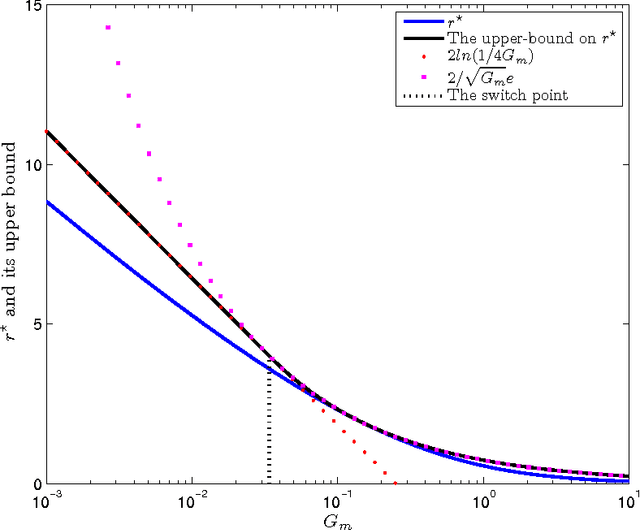
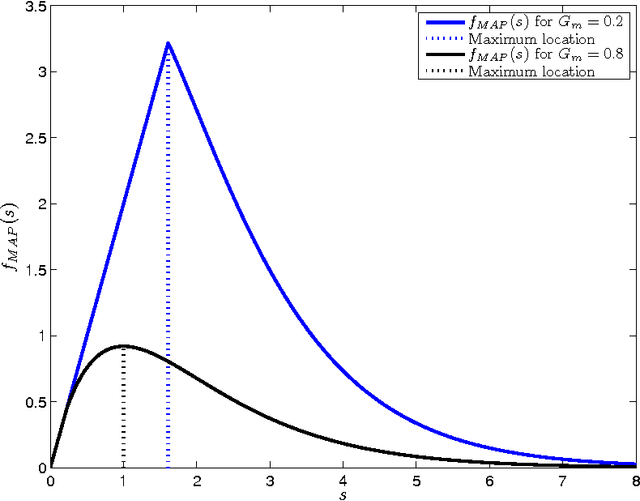
Among the many ways to model signals, a recent approach that draws considerable attention is sparse representation modeling. In this model, the signal is assumed to be generated as a random linear combination of a few atoms from a pre-specified dictionary. In this work we analyze two Bayesian denoising algorithms -- the Maximum-Aposteriori Probability (MAP) and the Minimum-Mean-Squared-Error (MMSE) estimators, under the assumption that the dictionary is unitary. It is well known that both these estimators lead to a scalar shrinkage on the transformed coefficients, albeit with a different response curve. In this work we start by deriving closed-form expressions for these shrinkage curves and then analyze their performance. Upper bounds on the MAP and the MMSE estimation errors are derived. We tie these to the error obtained by a so-called oracle estimator, where the support is given, establishing a worst-case gain-factor between the MAP/MMSE estimation errors and the oracle's performance. These denoising algorithms are demonstrated on synthetic signals and on true data (images).