 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstraction Induces the Brain Alignment of Language and Speech Models
Feb 03, 2026Research has repeatedly demonstrated that intermediate hidden states extracted from large language models and speech audio models predict measured brain response to natural language stimuli. Yet, very little is known about the representation properties that enable this high prediction performance. Why is it the intermediate layers, and not the output layers, that are most effective for this unique and highly general transfer task? We give evidence that the correspondence between speech and language models and the brain derives from shared meaning abstraction and not their next-word prediction properties. In particular, models construct higher-order linguistic features in their middle layers, cued by a peak in the layerwise intrinsic dimension, a measure of feature complexity. We show that a layer's intrinsic dimension strongly predicts how well it explains fMRI and ECoG signals; that the relation between intrinsic dimension and brain predictivity arises over model pre-training; and finetuning models to better predict the brain causally increases both representations' intrinsic dimension and their semantic content. Results suggest that semantic richness, high intrinsic dimension, and brain predictivity mirror each other, and that the key driver of model-brain similarity is rich meaning abstraction of the inputs, where language modeling is a task sufficiently complex (but perhaps not the only) to require it.
BrainWavLM: Fine-tuning Speech Representations with Brain Responses to Language
Feb 13, 2025



Speech encoding models use auditory representations to predict how the human brain responds to spoken language stimuli. Most performant encoding models linearly map the hidden states of artificial neural networks to brain data, but this linear restriction may limit their effectiveness. In this work, we use low-rank adaptation (LoRA) to fine-tune a WavLM-based encoding model end-to-end on a brain encoding objective, producing a model we name BrainWavLM. We show that fine-tuning across all of cortex improves average encoding performance with greater stability than without LoRA. This improvement comes at the expense of low-level regions like auditory cortex (AC), but selectively fine-tuning on these areas improves performance in AC, while largely retaining gains made in the rest of cortex. Fine-tuned models generalized across subjects, indicating that they learned robust brain-like representations of the speech stimuli. Finally, by training linear probes, we showed that the brain data strengthened semantic representations in the speech model without any explicit annotations. Our results demonstrate that brain fine-tuning produces best-in-class speech encoding models, and that non-linear methods have the potential to bridge the gap between artificial and biological representations of semantics.
Humans and language models diverge when predicting repeating text
Oct 23, 2023Language models that are trained on the next-word prediction task have been shown to accurately model human behavior in word prediction and reading speed. In contrast with these findings, we present a scenario in which the performance of humans and LMs diverges. We collected a dataset of human next-word predictions for five stimuli that are formed by repeating spans of text. Human and GPT-2 LM predictions are strongly aligned in the first presentation of a text span, but their performance quickly diverges when memory (or in-context learning) begins to play a role. We traced the cause of this divergence to specific attention heads in a middle layer. Adding a power-law recency bias to these attention heads yielded a model that performs much more similarly to humans. We hope that this scenario will spur future work in bringing LMs closer to human behavior.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

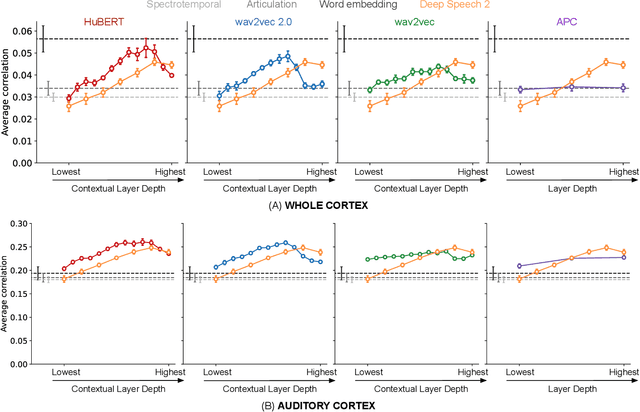
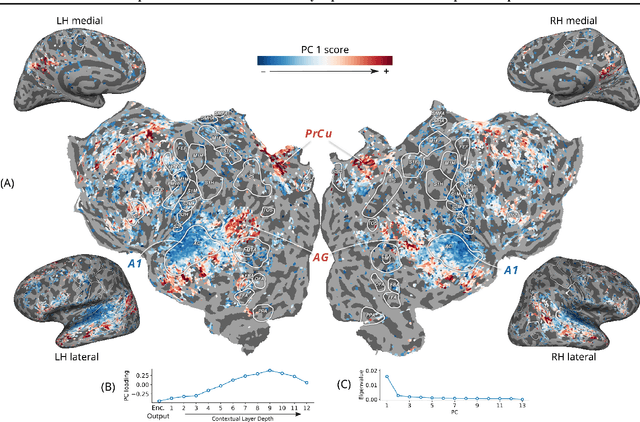
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
Physically Plausible Pose Refinement using Fully Differentiable Forces
May 17, 2021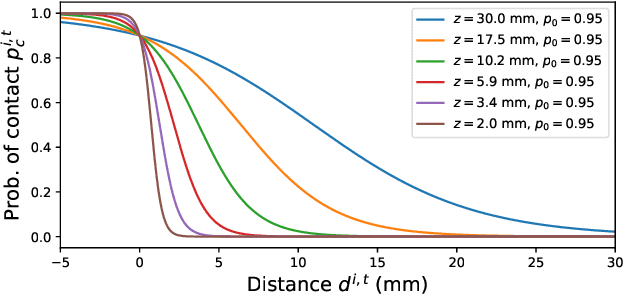
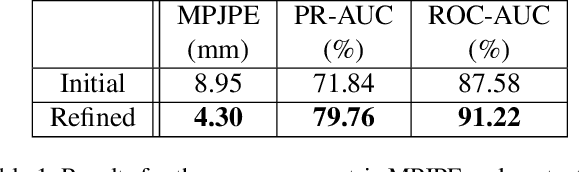
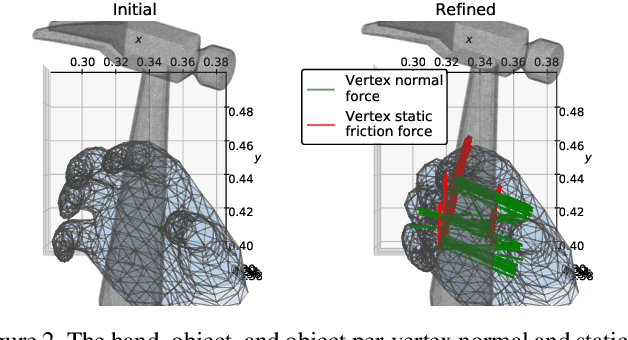
All hand-object interaction is controlled by forces that the two bodies exert on each other, but little work has been done in modeling these underlying forces when doing pose and contact estimation from RGB/RGB-D data. Given the pose of the hand and object from any pose estimation system, we propose an end-to-end differentiable model that refines pose estimates by learning the forces experienced by the object at each vertex in its mesh. By matching the learned net force to an estimate of net force based on finite differences of position, this model is able to find forces that accurately describe the movement of the object, while resolving issues like mesh interpenetration and lack of contact. Evaluating on the ContactPose dataset, we show this model successfully corrects poses and finds contact maps that better match the ground truth, despite not using any RGB or depth image data.