 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generative framework to bridge data-driven models and scientific theories in language neuroscience
Oct 01, 2024


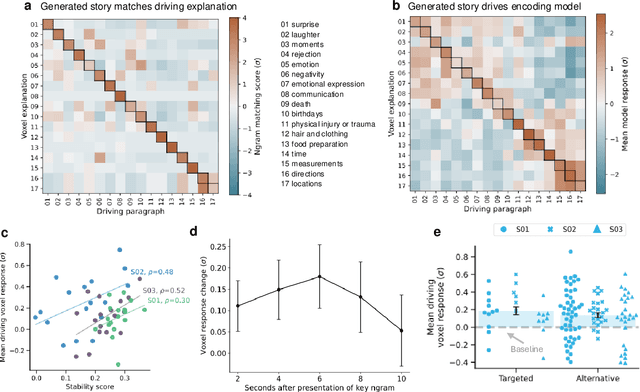
Representations from large language models are highly effective at predicting BOLD fMRI responses to language stimuli. However, these representations are largely opaque: it is unclear what features of the language stimulus drive the response in each brain area. We present generative explanation-mediated validation, a framework for generating concise explanations of language selectivity in the brain and then validating those explanations in follow-up experiments that use synthetic stimuli. This approach is successful at explaining selectivity both in individual voxels and cortical regions of interest (ROIs).We show that explanatory accuracy is closely related to the predictive power and stability of the underlying statistical models. These results demonstrate that LLMs can be used to bridge the widening gap between data-driven models and formal scientific theories.
Explaining black box text modules in natural language with language models
May 17, 2023



Large language models (LLMs) have demonstrated remarkable prediction performance for a growing array of tasks. However, their rapid proliferation and increasing opaqueness have created a growing need for interpretability. Here, we ask whether we can automatically obtain natural language explanations for black box text modules. A "text module" is any function that maps text to a scalar continuous value, such as a submodule within an LLM or a fitted model of a brain region. "Black box" indicates that we only have access to the module's inputs/outputs. We introduce Summarize and Score (SASC), a method that takes in a text module and returns a natural language explanation of the module's selectivity along with a score for how reliable the explanation is. We study SASC in 3 contexts. First, we evaluate SASC on synthetic modules and find that it often recovers ground truth explanations. Second, we use SASC to explain modules found within a pre-trained BERT model, enabling inspection of the model's internals. Finally, we show that SASC can generate explanations for the response of individual fMRI voxels to language stimuli, with potential applications to fine-grained brain mapping. All code for using SASC and reproducing results is made available on Github.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

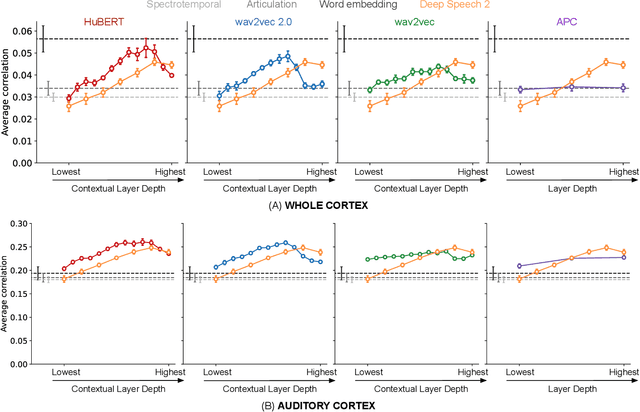
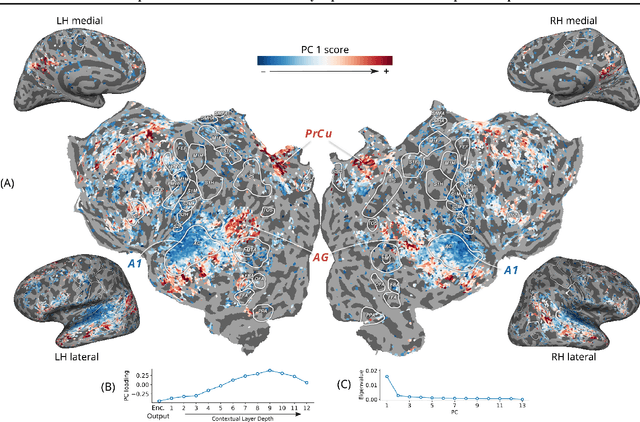
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
Spatial Language Representation with Multi-Level Geocoding
Aug 21, 2020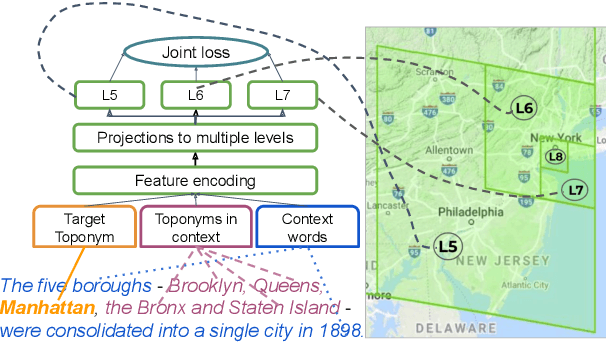

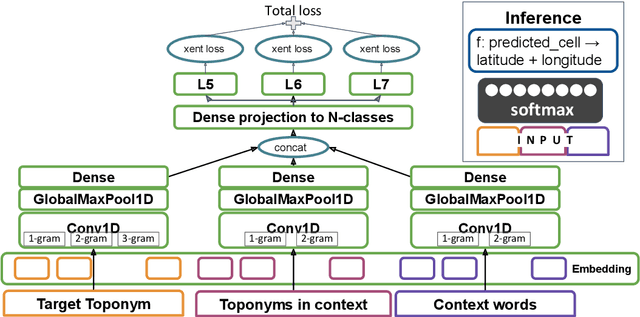

We present a multi-level geocoding model (MLG) that learns to associate texts to geographic locations. The Earth's surface is represented using space-filling curves that decompose the sphere into a hierarchy of similarly sized, non-overlapping cells. MLG balances generalization and accuracy by combining losses across multiple levels and predicting cells at each level simultaneously. Without using any dataset-specific tuning, we show that MLG obtains state-of-the-art results for toponym resolution on three English datasets. Furthermore, it obtains large gains without any knowledge base metadata, demonstrating that it can effectively learn the connection between text spans and coordinates - and thus can be extended to toponymns not present in knowledge bases.
A single-layer RNN can approximate stacked and bidirectional RNNs, and topologies in between
Aug 30, 2019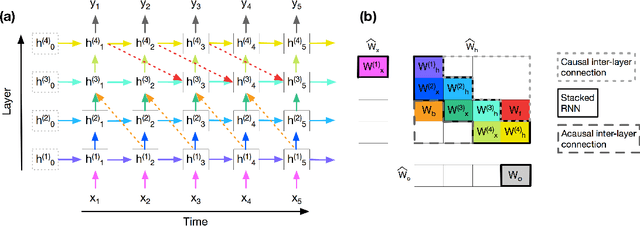
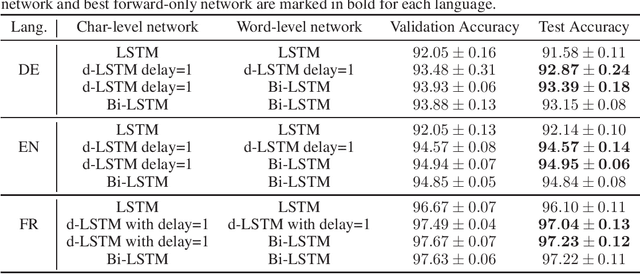
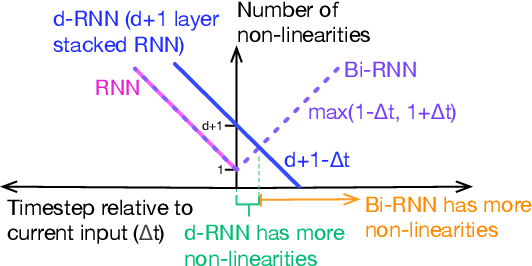
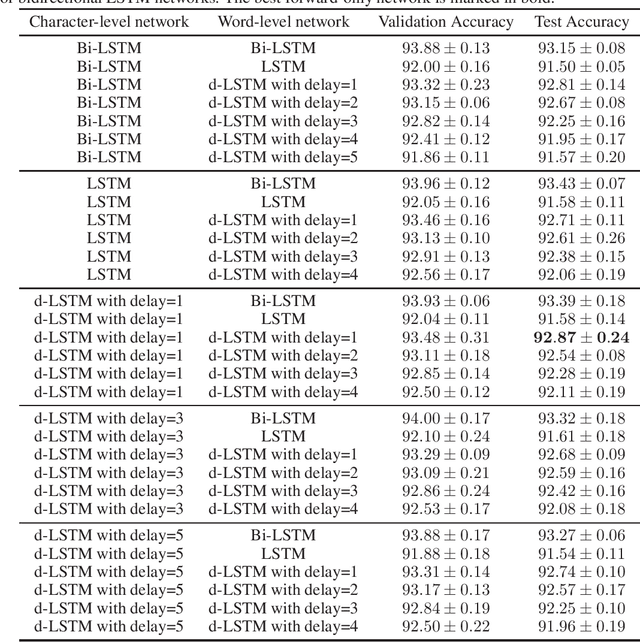
To enhance the expressiveness and representational capacity of recurrent neural networks (RNN), a large body of work has emerged exploring stacked architectures with additional topological modifications like shortcut connections or bidirectionality. However, choosing the best network for a particular problem requires a combinatorial search over architectures and their hyperparameters. In this work, we show that a single-layer RNN can perfectly mimic an arbitrarily deep stacked RNN under specific constraints on its weight matrix and a delay between input and output. This obviates the need to manually select hyperparameters like the number of layers. Additionally, we show that weakening weight constraints while keeping the delay gives rise to partial acausality in the single-layer RNN, much like a bidirectional network. Synthetic experiments confirm that the delayed RNN can mimic bidirectional networks in perfectly solving some acausal tasks, outperforming them in others. Finally, we show that in a challenging language processing task, the delayed RNN performs within 0.3\% of the accuracy of the bidirectional network while reducing computational costs.