 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024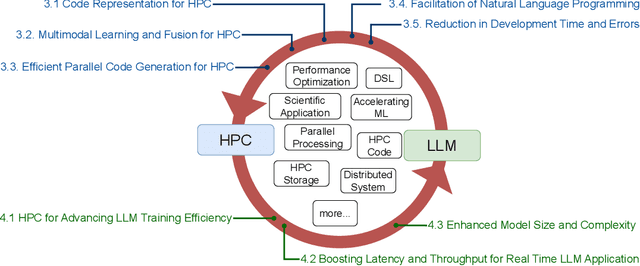

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
A Vertex Cut based Framework for Load Balancing and Parallelism Optimization in Multi-core Systems
Oct 09, 2020

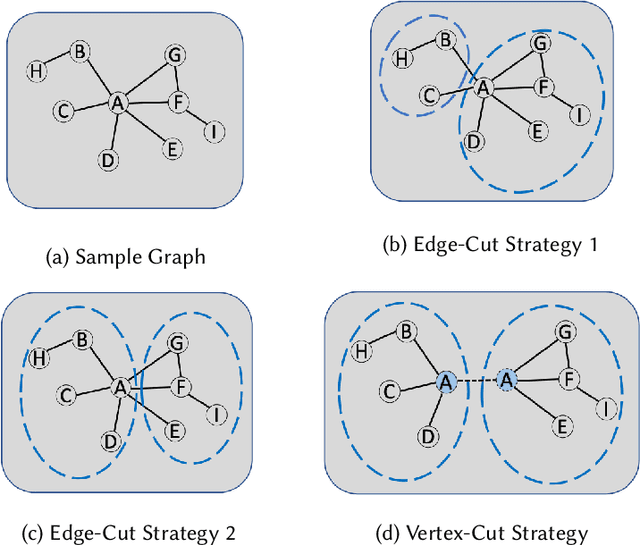
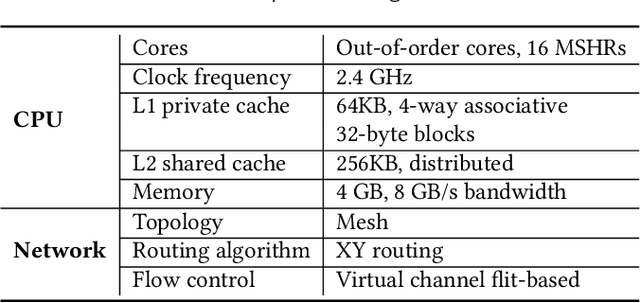
High-level applications, such as machine learning, are evolving from simple models based on multilayer perceptrons for simple image recognition to much deeper and more complex neural networks for self-driving vehicle control systems.The rapid increase in the consumption of memory and computational resources by these models demands the use of multi-core parallel systems to scale the execution of the complex emerging applications that depend on them. However, parallel programs running on high-performance computers often suffer from data communication bottlenecks, limited memory bandwidth, and synchronization overhead due to irregular critical sections. In this paper, we propose a framework to reduce the data communication and improve the scalability and performance of these applications in multi-core systems. We design a vertex cut framework for partitioning LLVM IR graphs into clusters while taking into consideration the data communication and workload balance among clusters. First, we construct LLVM graphs by compiling high-level programs into LLVM IR, instrumenting code to obtain the execution order of basic blocks and the execution time for each memory operation, and analyze data dependencies in dynamic LLVM traces. Next, we formulate the problem as Weight Balanced $p$-way Vertex Cut, and propose a generic and flexible framework, wherein four different greedy algorithms are proposed for solving this problem. Lastly, we propose a memory-centric run-time mapping of the linear time complexity to map clusters generated from the vertex cut algorithms onto a multi-core platform. We conclude that our best algorithm, WB-Libra, provides performance improvements of 1.56x and 1.86x over existing state-of-the-art approaches for 8 and 1024 clusters running on a multi-core platform, respectively.
Navigating the Trade-Off between Multi-Task Learning and Learning to Multitask in Deep Neural Networks
Jul 20, 2020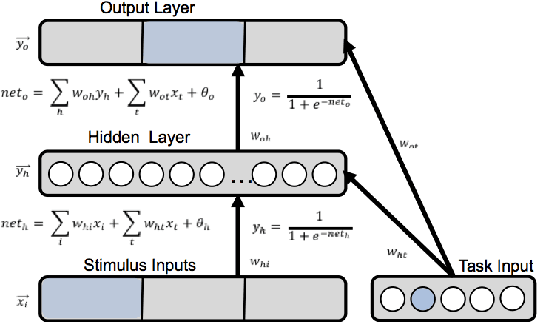
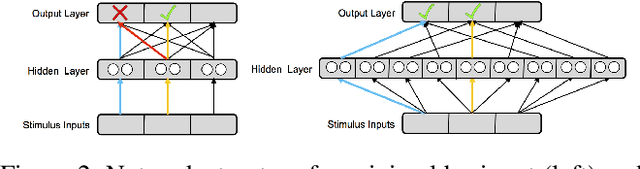
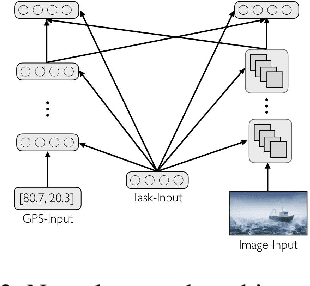
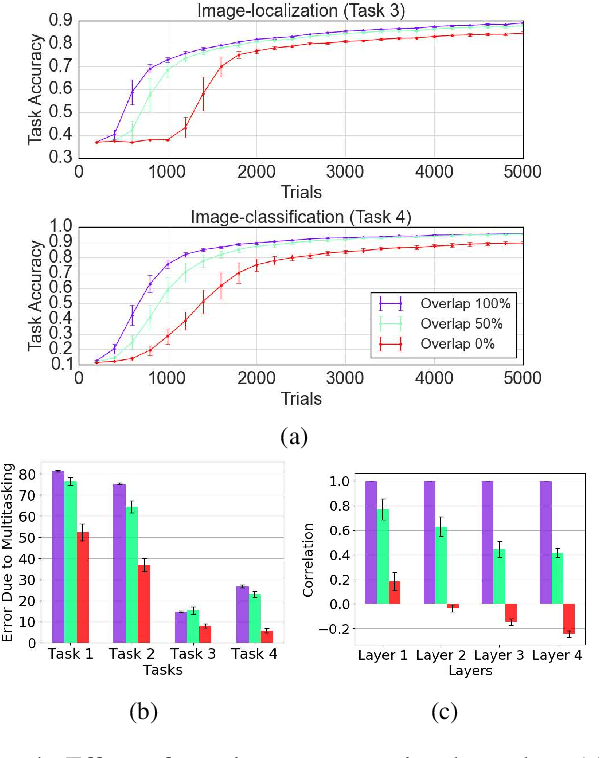
The terms multi-task learning and multitasking are easily confused. Multi-task learning refers to a paradigm in machine learning in which a network is trained on various related tasks to facilitate the acquisition of tasks. In contrast, multitasking is used to indicate, especially in the cognitive science literature, the ability to execute multiple tasks simultaneously. While multi-task learning exploits the discovery of common structure between tasks in the form of shared representations, multitasking is promoted by separating representations between tasks to avoid processing interference. Here, we build on previous work involving shallow networks and simple task settings suggesting that there is a trade-off between multi-task learning and multitasking, mediated by the use of shared versus separated representations. We show that the same tension arises in deep networks and discuss a meta-learning algorithm for an agent to manage this trade-off in an unfamiliar environment. We display through different experiments that the agent is able to successfully optimize its training strategy as a function of the environment.
Deep Graph Similarity Learning: A Survey
Dec 25, 2019
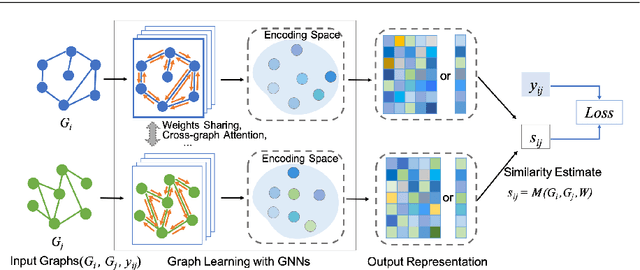
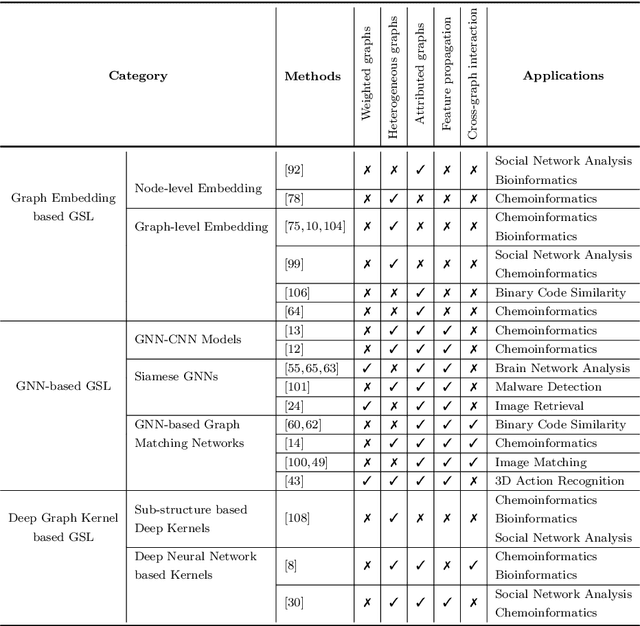
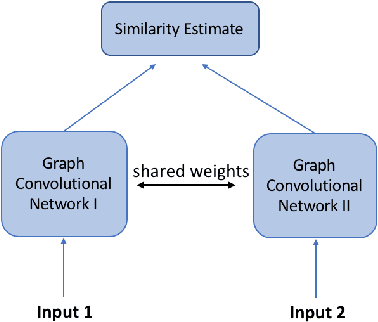
In many domains where data are represented as graphs, learning a similarity metric among graphs is considered a key problem, which can further facilitate various learning tasks, such as classification, clustering, and similarity search. Recently, there has been an increasing interest in deep graph similarity learning, where the key idea is to learn a deep learning model that maps input graphs to a target space such that the distance in the target space approximates the structural distance in the input space. Here, we provide a comprehensive review of the existing literature of deep graph similarity learning. We propose a systematic taxonomy for the methods and applications. Finally, we discuss the challenges and future directions for this problem.
A single-layer RNN can approximate stacked and bidirectional RNNs, and topologies in between
Aug 30, 2019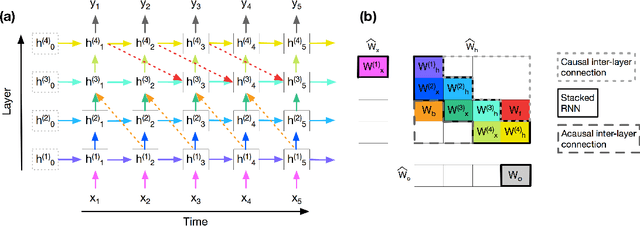
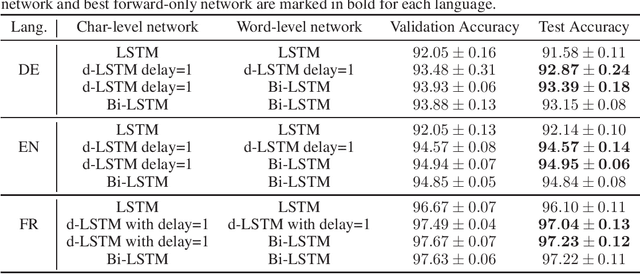
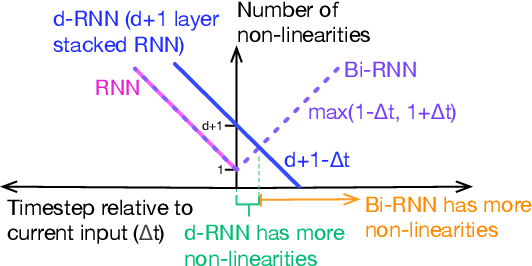
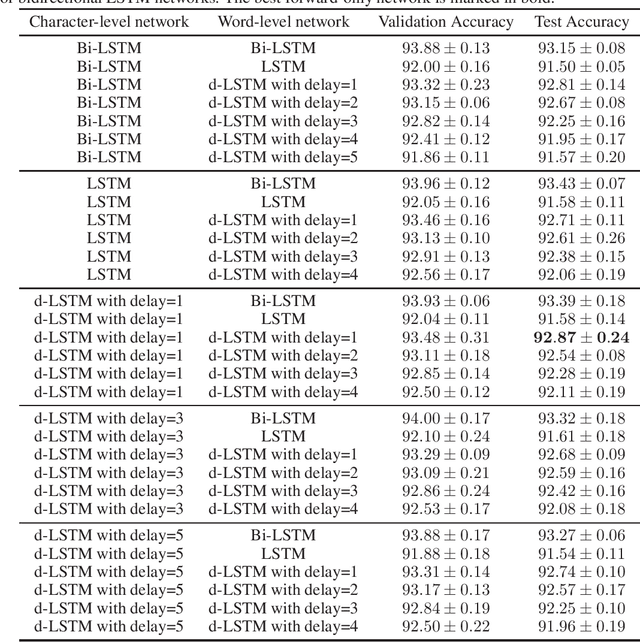
To enhance the expressiveness and representational capacity of recurrent neural networks (RNN), a large body of work has emerged exploring stacked architectures with additional topological modifications like shortcut connections or bidirectionality. However, choosing the best network for a particular problem requires a combinatorial search over architectures and their hyperparameters. In this work, we show that a single-layer RNN can perfectly mimic an arbitrarily deep stacked RNN under specific constraints on its weight matrix and a delay between input and output. This obviates the need to manually select hyperparameters like the number of layers. Additionally, we show that weakening weight constraints while keeping the delay gives rise to partial acausality in the single-layer RNN, much like a bidirectional network. Synthetic experiments confirm that the delayed RNN can mimic bidirectional networks in perfectly solving some acausal tasks, outperforming them in others. Finally, we show that in a challenging language processing task, the delayed RNN performs within 0.3\% of the accuracy of the bidirectional network while reducing computational costs.
Clinically Deployed Distributed Magnetic Resonance Imaging Reconstruction: Application to Pediatric Knee Imaging
Sep 11, 2018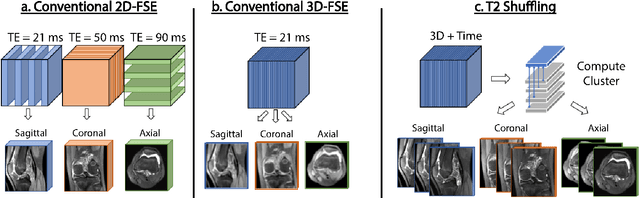
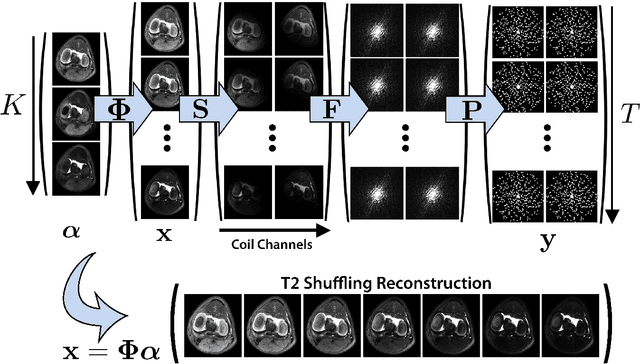
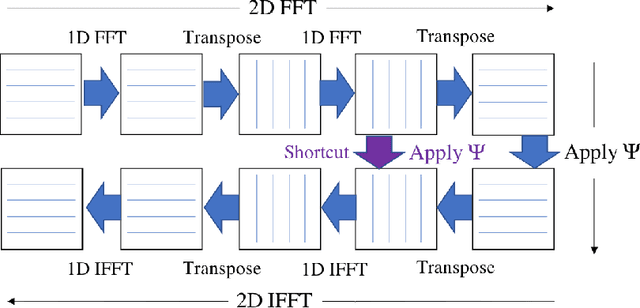
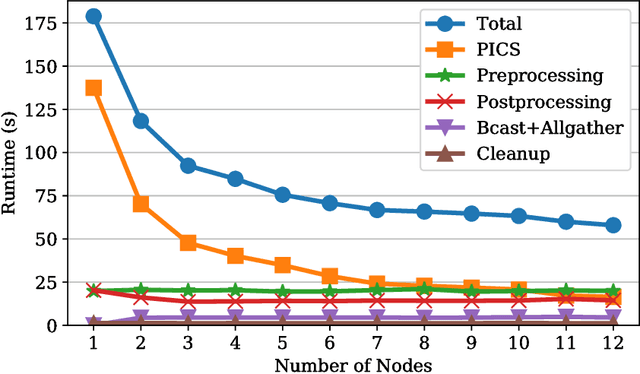
Magnetic resonance imaging is capable of producing volumetric images without ionizing radiation. Nonetheless, long acquisitions lead to prohibitively long exams. Compressed sensing (CS) can enable faster scanning via sub-sampling with reduced artifacts. However, CS requires significantly higher reconstruction computation, limiting current clinical applications to 2D/3D or limited-resolution dynamic imaging. Here we analyze the practical limitations to T2 Shuffling, a four-dimensional CS-based acquisition, which provides sharp 3D-isotropic-resolution and multi-contrast images in a single scan. Our improvements to the pipeline on a single machine provide a 3x overall reconstruction speedup, which allowed us to add algorithmic changes improving image quality. Using four machines, we achieved additional 2.1x improvement through distributed parallelization. Our solution reduced the reconstruction time in the hospital to 90 seconds on a 4-node cluster, enabling its use clinically. To understand the implications of scaling this application, we simulated running our reconstructions with a multiple scanner setup typical in hospitals.
Out-of-Distribution Detection Using an Ensemble of Self Supervised Leave-out Classifiers
Sep 04, 2018
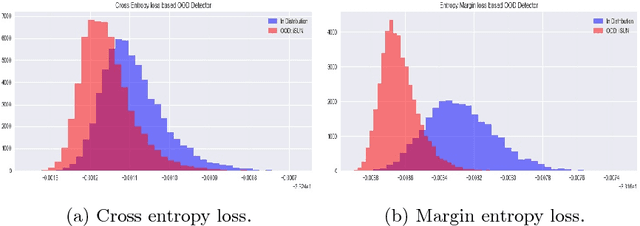
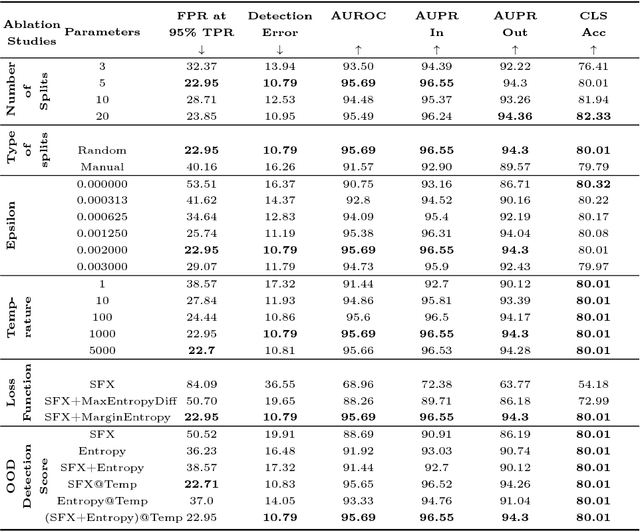
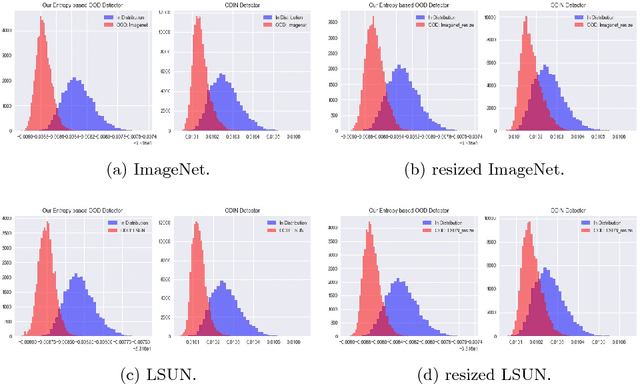
As deep learning methods form a critical part in commercially important applications such as autonomous driving and medical diagnostics, it is important to reliably detect out-of-distribution (OOD) inputs while employing these algorithms. In this work, we propose an OOD detection algorithm which comprises of an ensemble of classifiers. We train each classifier in a self-supervised manner by leaving out a random subset of training data as OOD data and the rest as in-distribution (ID) data. We propose a novel margin-based loss over the softmax output which seeks to maintain at least a margin $m$ between the average entropy of the OOD and in-distribution samples. In conjunction with the standard cross-entropy loss, we minimize the novel loss to train an ensemble of classifiers. We also propose a novel method to combine the outputs of the ensemble of classifiers to obtain OOD detection score and class prediction. Overall, our method convincingly outperforms Hendrycks et al.[7] and the current state-of-the-art ODIN[13] on several OOD detection benchmarks.
Learning Role-based Graph Embeddings
Jul 02, 2018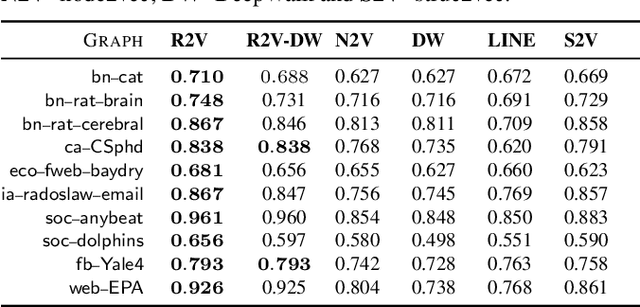
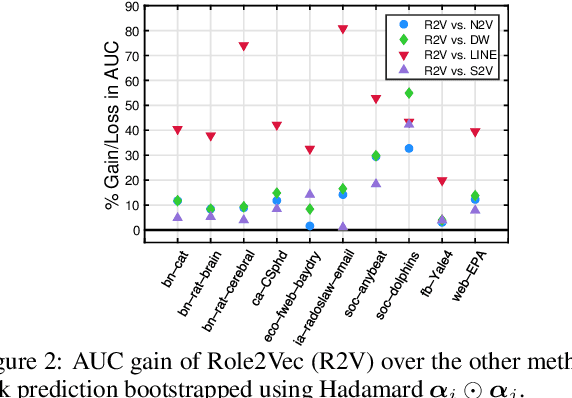
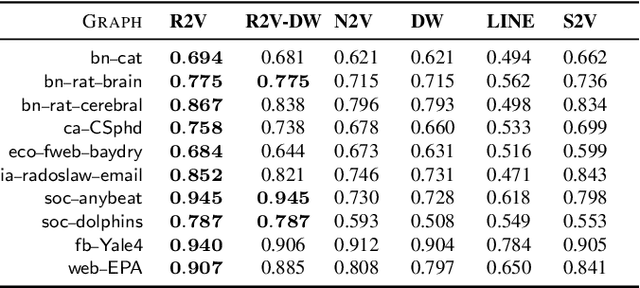
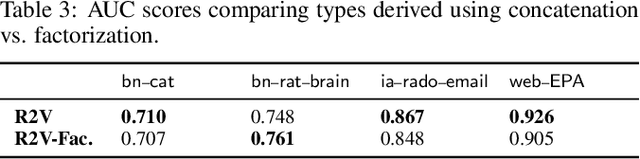
Random walks are at the heart of many existing network embedding methods. However, such algorithms have many limitations that arise from the use of random walks, e.g., the features resulting from these methods are unable to transfer to new nodes and graphs as they are tied to vertex identity. In this work, we introduce the Role2Vec framework which uses the flexible notion of attributed random walks, and serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many others that leverage random walks. Our proposed framework enables these methods to be more widely applicable for both transductive and inductive learning as well as for use on graphs with attributes (if available). This is achieved by learning functions that generalize to new nodes and graphs. We show that our proposed framework is effective with an average AUC improvement of 16.55% while requiring on average 853x less space than existing methods on a variety of graphs.