 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Community to Role-based Graph Embeddings
Aug 22, 2019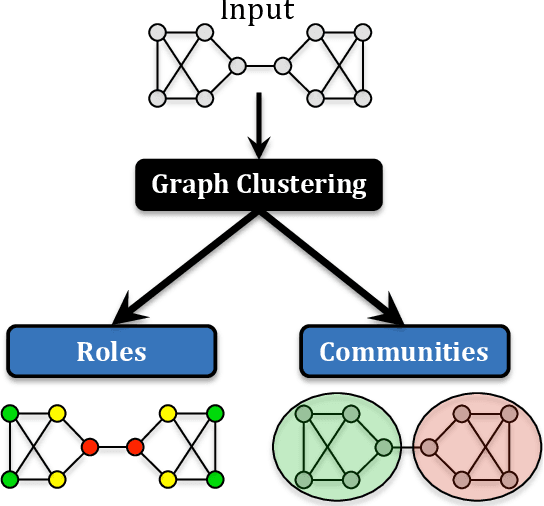

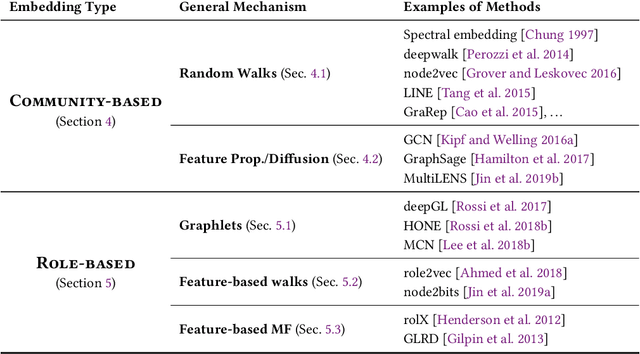
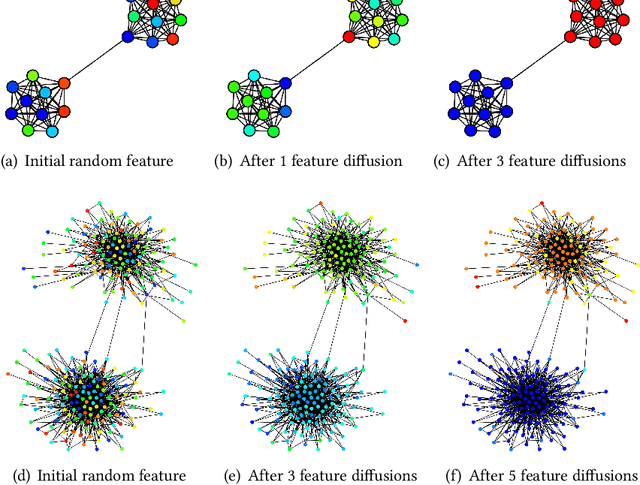
Roles are sets of structurally similar nodes that are more similar to nodes inside the set than outside, whereas communities are sets of nodes with more connections inside the set than outside (based on proximity/closeness, density). Roles and communities are fundamentally different but important complementary notions. Recently, the notion of roles has become increasingly important and has gained a lot of attention due to the proliferation of work on learning representations (node/edge embeddings) from graphs that preserve the notion of roles. Unfortunately, recent work has sometimes confused the notion of roles and communities leading to misleading or incorrect claims about the capabilities of network embedding methods. As such, this manuscript seeks to clarify the differences between roles and communities, and formalize the general mechanisms (e.g., random walks, feature diffusion) that give rise to community or role-based embeddings. We show mathematically why embedding methods based on these identified mechanisms are either community or role-based. These mechanisms are typically easy to identify and can help researchers quickly determine whether a method is more prone to learn community or role-based embeddings. Furthermore, they also serve as a basis for developing new and better methods for community or role-based embeddings. Finally, we analyze and discuss the applications and data characteristics where community or role-based embeddings are most appropriate.
Temporal Network Representation Learning
Apr 12, 2019


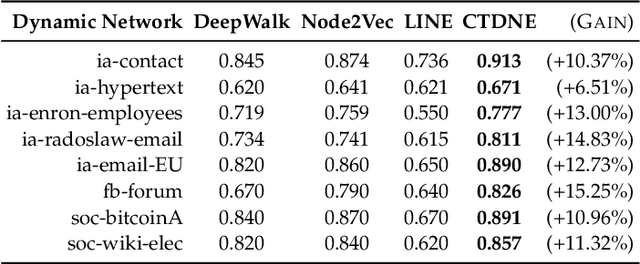
Networks evolve continuously over time with the addition, deletion, and changing of links and nodes. Such temporal networks (or edge streams) consist of a sequence of timestamped edges and are seemingly ubiquitous. Despite the importance of accurately modeling the temporal information, most embedding methods ignore it entirely or approximate the temporal network using a sequence of static snapshot graphs. In this work, we introduce the notion of \emph{temporal walks} for learning dynamic embeddings from temporal networks. Temporal walks capture the temporally valid interactions (\eg, flow of information, spread of disease) in the dynamic network in a lossless fashion. Based on the notion of temporal walks, we describe a general class of embeddings called continuous-time dynamic network embeddings (CTDNEs) that completely avoid the issues and problems that arise when approximating the temporal network as a sequence of static snapshot graphs. Unlike previous work, CTDNEs learn dynamic node embeddings directly from the temporal network at the finest temporal granularity and thus use only temporally valid information. As such CTDNEs naturally support online learning of the node embeddings in a streaming real-time fashion. The experiments demonstrate the effectiveness of this class of embedding methods for prediction in temporal networks.
Higher-order Graph Convolutional Networks
Sep 12, 2018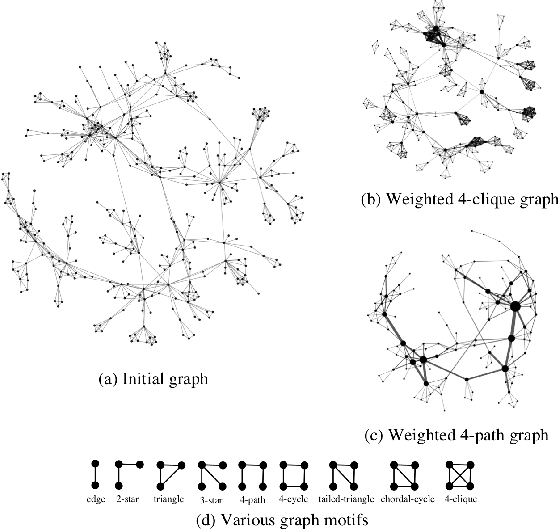

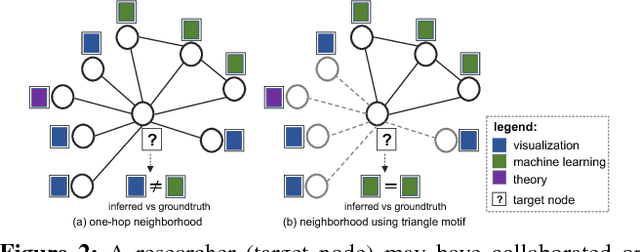
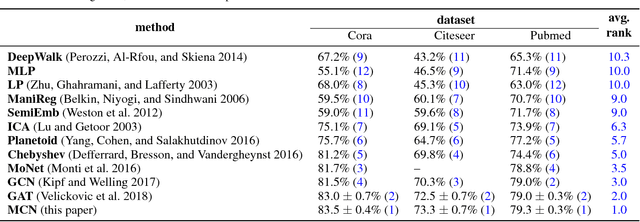
Following the success of deep convolutional networks in various vision and speech related tasks, researchers have started investigating generalizations of the well-known technique for graph-structured data. A recently-proposed method called Graph Convolutional Networks has been able to achieve state-of-the-art results in the task of node classification. However, since the proposed method relies on localized first-order approximations of spectral graph convolutions, it is unable to capture higher-order interactions between nodes in the graph. In this work, we propose a motif-based graph attention model, called Motif Convolutional Networks (MCNs), which generalizes past approaches by using weighted multi-hop motif adjacency matrices to capture higher-order neighborhoods. A novel attention mechanism is used to allow each individual node to select the most relevant neighborhood to apply its filter. Experiments show that our proposed method is able to achieve state-of-the-art results on the semi-supervised node classification task.
Attention Models in Graphs: A Survey
Jul 20, 2018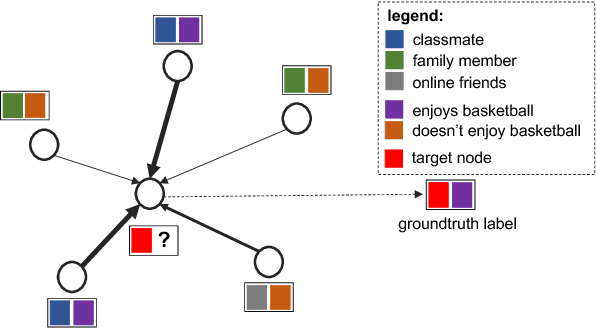

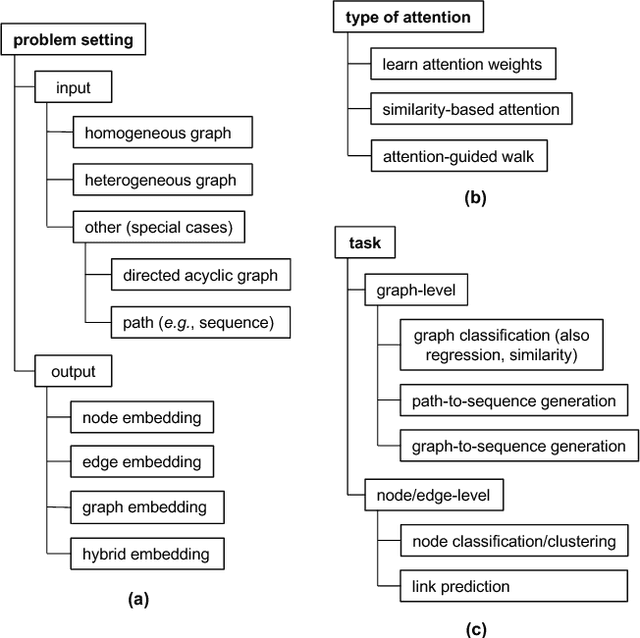

Graph-structured data arise naturally in many different application domains. By representing data as graphs, we can capture entities (i.e., nodes) as well as their relationships (i.e., edges) with each other. Many useful insights can be derived from graph-structured data as demonstrated by an ever-growing body of work focused on graph mining. However, in the real-world, graphs can be both large - with many complex patterns - and noisy which can pose a problem for effective graph mining. An effective way to deal with this issue is to incorporate "attention" into graph mining solutions. An attention mechanism allows a method to focus on task-relevant parts of the graph, helping it to make better decisions. In this work, we conduct a comprehensive and focused survey of the literature on the emerging field of graph attention models. We introduce three intuitive taxonomies to group existing work. These are based on problem setting (type of input and output), the type of attention mechanism used, and the task (e.g., graph classification, link prediction, etc.). We motivate our taxonomies through detailed examples and use each to survey competing approaches from a unique standpoint. Finally, we highlight several challenges in the area and discuss promising directions for future work.
Learning Role-based Graph Embeddings
Jul 02, 2018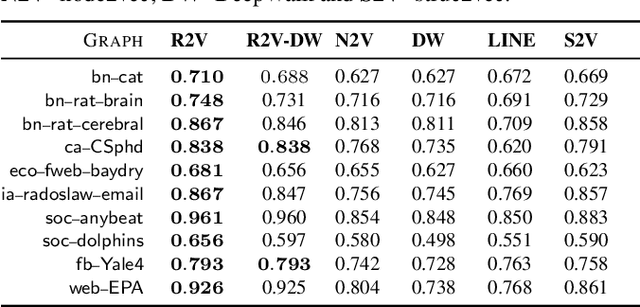
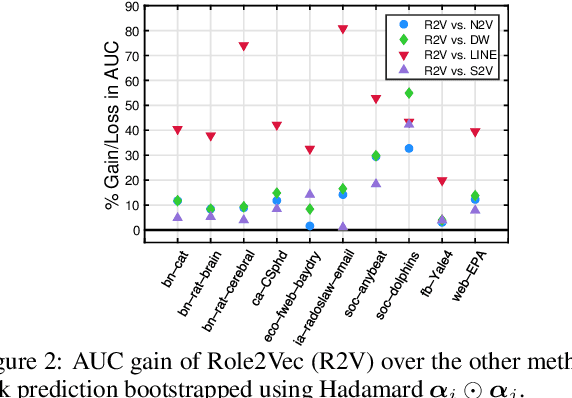
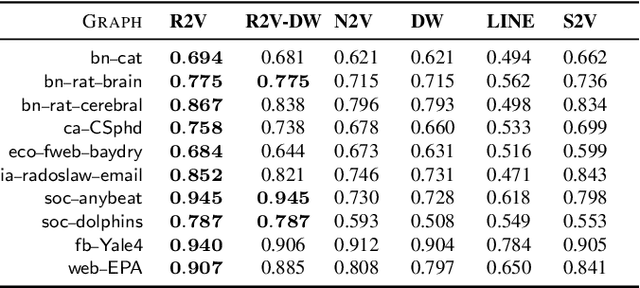
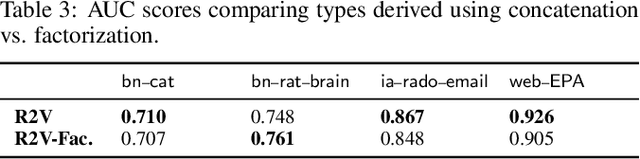
Random walks are at the heart of many existing network embedding methods. However, such algorithms have many limitations that arise from the use of random walks, e.g., the features resulting from these methods are unable to transfer to new nodes and graphs as they are tied to vertex identity. In this work, we introduce the Role2Vec framework which uses the flexible notion of attributed random walks, and serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many others that leverage random walks. Our proposed framework enables these methods to be more widely applicable for both transductive and inductive learning as well as for use on graphs with attributes (if available). This is achieved by learning functions that generalize to new nodes and graphs. We show that our proposed framework is effective with an average AUC improvement of 16.55% while requiring on average 853x less space than existing methods on a variety of graphs.
Inductive Representation Learning in Large Attributed Graphs
Nov 22, 2017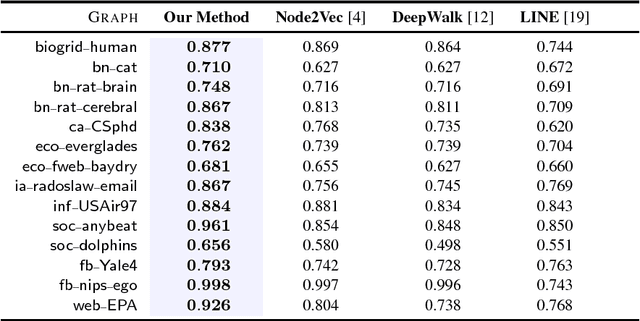
Graphs (networks) are ubiquitous and allow us to model entities (nodes) and the dependencies (edges) between them. Learning a useful feature representation from graph data lies at the heart and success of many machine learning tasks such as classification, anomaly detection, link prediction, among many others. Many existing techniques use random walks as a basis for learning features or estimating the parameters of a graph model for a downstream prediction task. Examples include recent node embedding methods such as DeepWalk, node2vec, as well as graph-based deep learning algorithms. However, the simple random walk used by these methods is fundamentally tied to the identity of the node. This has three main disadvantages. First, these approaches are inherently transductive and do not generalize to unseen nodes and other graphs. Second, they are not space-efficient as a feature vector is learned for each node which is impractical for large graphs. Third, most of these approaches lack support for attributed graphs. To make these methods more generally applicable, we propose a framework for inductive network representation learning based on the notion of attributed random walk that is not tied to node identity and is instead based on learning a function $\Phi : \mathrm{\rm \bf x} \rightarrow w$ that maps a node attribute vector $\mathrm{\rm \bf x}$ to a type $w$. This framework serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many other previous methods that leverage traditional random walks.
Deep Graph Attention Model
Sep 15, 2017
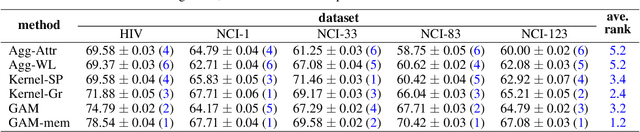


Graph classification is a problem with practical applications in many different domains. Most of the existing methods take the entire graph into account when calculating graph features. In a graphlet-based approach, for instance, the entire graph is processed to get the total count of different graphlets or sub-graphs. In the real-world, however, graphs can be both large and noisy with discriminative patterns confined to certain regions in the graph only. In this work, we study the problem of attentional processing for graph classification. The use of attention allows us to focus on small but informative parts of the graph, avoiding noise in the rest of the graph. We present a novel RNN model, called the Graph Attention Model (GAM), that processes only a portion of the graph by adaptively selecting a sequence of "interesting" nodes. The model is equipped with an external memory component which allows it to integrate information gathered from different parts of the graph. We demonstrate the effectiveness of the model through various experiments.
A Framework for Generalizing Graph-based Representation Learning Methods
Sep 14, 2017
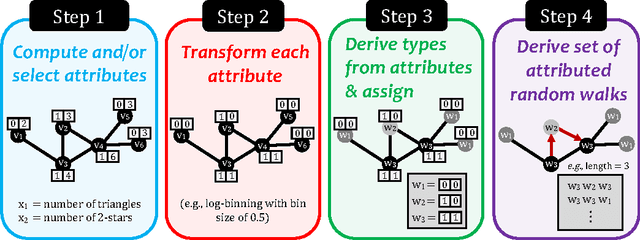

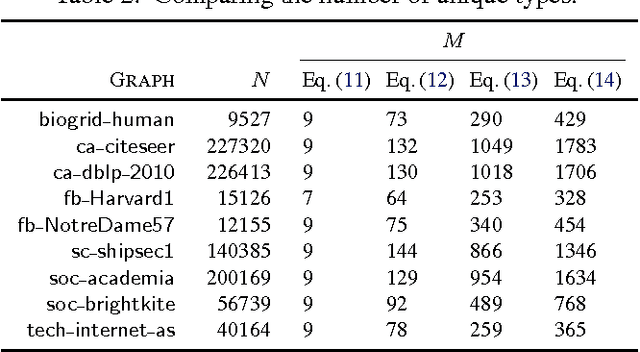
Random walks are at the heart of many existing deep learning algorithms for graph data. However, such algorithms have many limitations that arise from the use of random walks, e.g., the features resulting from these methods are unable to transfer to new nodes and graphs as they are tied to node identity. In this work, we introduce the notion of attributed random walks which serves as a basis for generalizing existing methods such as DeepWalk, node2vec, and many others that leverage random walks. Our proposed framework enables these methods to be more widely applicable for both transductive and inductive learning as well as for use on graphs with attributes (if available). This is achieved by learning functions that generalize to new nodes and graphs. We show that our proposed framework is effective with an average AUC improvement of 16.1% while requiring on average 853 times less space than existing methods on a variety of graphs from several domains.
Comparison of several short-term traffic speed forecasting models
Sep 06, 2016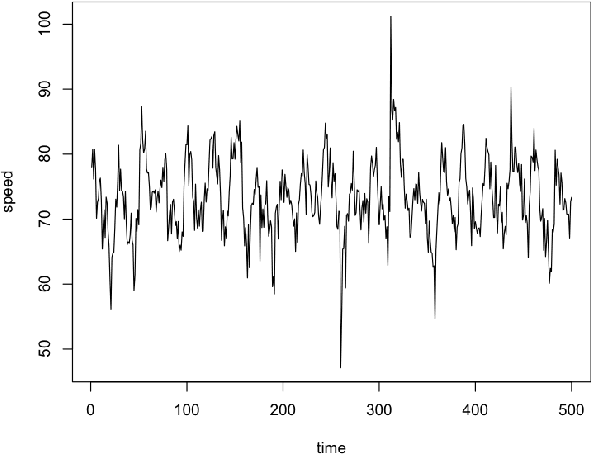

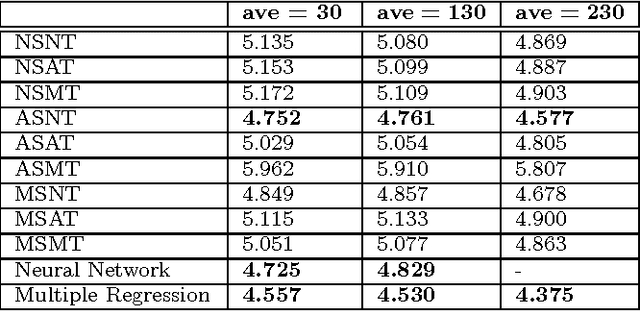
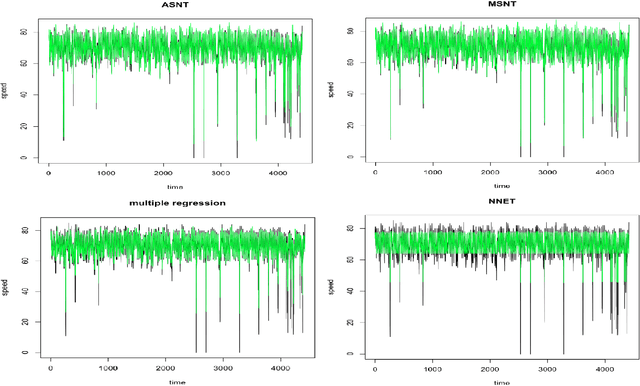
The widespread adoption of smartphones in recent years has made it possible for us to collect large amounts of traffic data. Special software installed on the phones of drivers allow us to gather GPS trajectories of their vehicles on the road network. In this paper, we simulate the trajectories of multiple agents on a road network and use various models to forecast the short-term traffic speed of various links. Our results show that traditional techniques like multiple regression and artificial neural networks work well but simpler adaptive models that do not require prior training also perform comparatively well.