 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Trajectory Reasoning through Adaptive Cross-Step Evidence Aggregation for LLM Agents
Jun 05, 2026Autonomous LLM agents can pursue hidden malicious objectives through sequences of individually benign actions, making sabotage difficult to detect using standard trajectory-level monitoring. Existing approaches either evaluate complete trajectories in a single pass or partition them into independently scored windows, limiting their ability to connect evidence across temporally distant actions. We propose TRACE, a monitoring framework for long-horizon LLM agent trajectories. TRACE operates through a TIJ (Triage-Inspect-Judge) loop that identifies high-signal regions, performs targeted inspection while maintaining accumulated evidence across reasoning steps, and synthesizes a trajectory-level verdict. We evaluate TRACE on ten task domains from SHADE-Arena against state-of-the-art baselines. TRACE achieves an aggregate F1 of 0.713 and recall of 0.844, with the largest gains on tasks requiring long-range evidence linking.
Agent-ToM: Learning to Monitor Autonomous LLM Agents via Theory-of-Mind Reasoning
May 22, 2026Monitoring autonomous large language model (LLM) agents for covert malicious behavior is challenging due to delayed, context-dependent, and long-horizon attack patterns. Agents may pursue hidden objectives while maintaining superficially benign behavior, making detection difficult even with full trajectory access. Prior monitoring approaches improve scaffolding or ensemble aggregation, but treat each trajectory independently and do not learn from prior monitoring experience. Moreover, standard reasoning methods explain observed behavior without explicitly reasoning about agent beliefs, intentions, and goal alignment required to distinguish benign task execution from covert deviation. We propose \textbf{Agent-ToM}, a learning-to-monitor framework grounded in Theory-of-Mind (ToM) reasoning for security analysis of autonomous agents. Agent-ToM performs structured full-trajectory analysis by inferring beliefs, intent hypotheses with calibrated confidence, expected actions, and deviations from task-consistent behavioral baselines. At inference time, it employs a \textit{Reason-Verify-Refine} pipeline to construct and validate monitoring decisions. At training time, Agent-ToM distills critique signals into a persistent \textit{semantic guardrail memory}, enabling reusable belief- and intent-conditioned constraints across episodes. We evaluate Agent-ToM on adversarial agent monitoring benchmarks (SHADE-Arena and CUA-SHADE-Arena). Agent-ToM achieves strong precision-recall balance and outperforms state-of-the-art monitoring baselines, including ensemble methods, while using a coherent two-call reasoning pipeline. These results demonstrate that learning at the monitoring layer, combined with structured ToM reasoning and verification, provides an effective and deployable foundation for securing autonomous LLM agents.
Sparse Personalized Text Generation with Multi-Trajectory Reasoning
Apr 27, 2026As Large Language Models (LLMs) advance, personalization has become a key mechanism for tailoring outputs to individual user needs. However, most existing methods rely heavily on dense interaction histories, making them ineffective in cold-start scenarios where such data is sparse or unavailable. While external signals (e.g., content of similar users) can offer a potential remedy, leveraging them effectively remains challenging: raw context is often noisy, and existing methods struggle to reason over heterogeneous data sources. To address these issues, we introduce PAT (Personalization with Aligned Trajectories), a reasoning framework for cold-start LLM personalization. PAT first retrieves information along two complementary trajectories: writing-style cues from stylistically similar users and topic-specific context from preference-aligned users. It then employs a reinforcement learning-based, iterative dual-reasoning mechanism that enables the LLM to jointly refine and integrate these signals. Experimental results across real-world personalization benchmarks show that PAT consistently improves generation quality and alignment under sparse-data conditions, establishing a strong solution to the cold-start personalization problem.
Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
Feb 13, 2026Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.
OptiML: An End-to-End Framework for Program Synthesis and CUDA Kernel Optimization
Feb 12, 2026Generating high-performance CUDA kernels remains challenging due to the need to navigate a combinatorial space of low-level transformations under noisy and expensive hardware feedback. Although large language models can synthesize functionally correct CUDA code, achieving competitive performance requires systematic exploration and verification of optimization choices. We present OptiML, an end-to-end framework that maps either natural-language intent or input CUDA code to performance-optimized CUDA kernels by formulating kernel optimization as search under verification. OptiML consists of two decoupled stages. When the input is natural language, a Mixture-of-Thoughts generator (OptiML-G) acts as a proposal policy over kernel implementation strategies, producing an initial executable program. A search-based optimizer (OptiML-X) then refines either synthesized or user-provided kernels using Monte Carlo Tree Search over LLM-driven edits, guided by a hardware-aware reward derived from profiler feedback. Each candidate transformation is compiled, verified, and profiled with Nsight Compute, and evaluated by a composite objective that combines runtime with hardware bottleneck proxies and guardrails against regressions. We evaluate OptiML in both synthesis-and-optimize and optimization-only settings on a diverse suite of CUDA kernels. Results show that OptiML consistently discovers verified performance improvements over strong LLM baselines and produces interpretable optimization trajectories grounded in profiler evidence.
Blind to the Human Touch: Overlap Bias in LLM-Based Summary Evaluation
Feb 07, 2026Large language model (LLM) judges have often been used alongside traditional, algorithm-based metrics for tasks like summarization because they better capture semantic information, are better at reasoning, and are more robust to paraphrasing. However, LLM judges show biases for length and order among others, and are vulnerable to various adversarial input prompts. While recent studies have looked into these biases, few have analyzed them at a more granular level in relation to a well-defined overlap metric. In this work we provide an LLM judge bias analysis as a function of overlap with human-written responses in the domain of summarization. We test 9 recent LLMs with parameter counts ranging from 1 billion to 12 billion, including variants of Gemma 3 and LLaMA 3. We find that LLM judges increasingly prefer summaries generated by other LLMs over those written by humans as the similarities (as measured by ROUGE and BLEU) between the judged summaries decrease, and this pattern extends to all but one model tested, and exists regardless of the models' own position biases. Additionally, we find that models struggle to judge even summaries with limited overlaps, suggesting that LLM-as-a-judge in the summary domain should rely on techniques beyond a simple comparison.
Segment Length Matters: A Study of Segment Lengths on Audio Fingerprinting Performance
Jan 25, 2026Audio fingerprinting provides an identifiable representation of acoustic signals, which can be later used for identification and retrieval systems. To obtain a discriminative representation, the input audio is usually segmented into shorter time intervals, allowing local acoustic features to be extracted and analyzed. Modern neural approaches typically operate on short, fixed-duration audio segments, yet the choice of segment duration is often made heuristically and rarely examined in depth. In this paper, we study how segment length affects audio fingerprinting performance. We extend an existing neural fingerprinting architecture to adopt various segment lengths and evaluate retrieval accuracy across different segment lengths and query durations. Our results show that short segment lengths (0.5-second) generally achieve better performance. Moreover, we evaluate LLM capacity in recommending the best segment length, which shows that GPT-5-mini consistently gives the best suggestions across five considerations among three studied LLMs. Our findings provide practical guidance for selecting segment duration in large-scale neural audio retrieval systems.
Forecasting Time Series with LLMs via Patch-Based Prompting and Decomposition
Jun 15, 2025Recent advances in Large Language Models (LLMs) have demonstrated new possibilities for accurate and efficient time series analysis, but prior work often required heavy fine-tuning and/or ignored inter-series correlations. In this work, we explore simple and flexible prompt-based strategies that enable LLMs to perform time series forecasting without extensive retraining or the use of a complex external architecture. Through the exploration of specialized prompting methods that leverage time series decomposition, patch-based tokenization, and similarity-based neighbor augmentation, we find that it is possible to enhance LLM forecasting quality while maintaining simplicity and requiring minimal preprocessing of data. To this end, we propose our own method, PatchInstruct, which enables LLMs to make precise and effective predictions.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models
May 25, 2025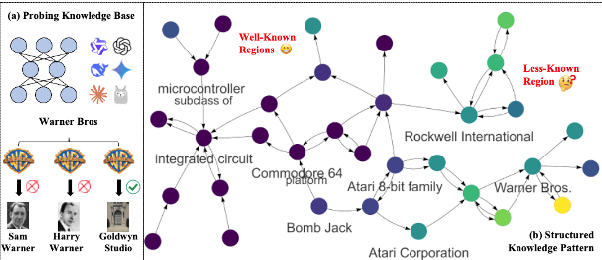
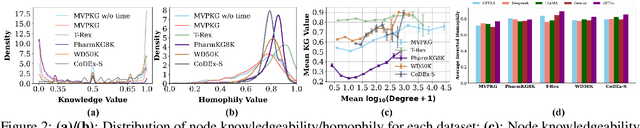
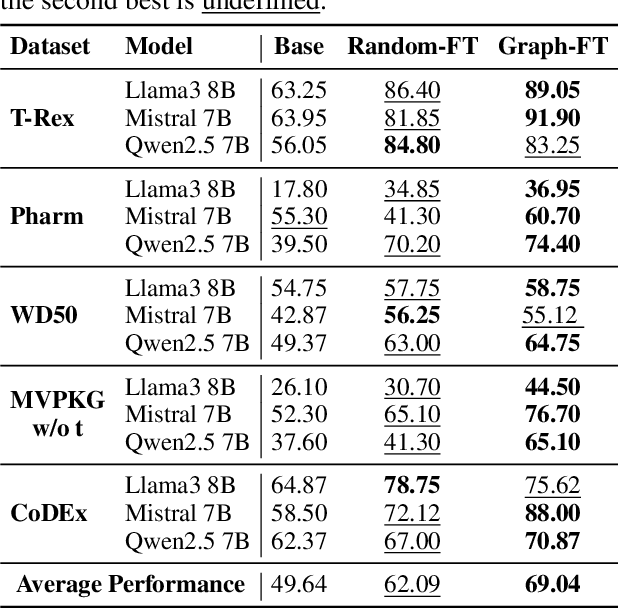
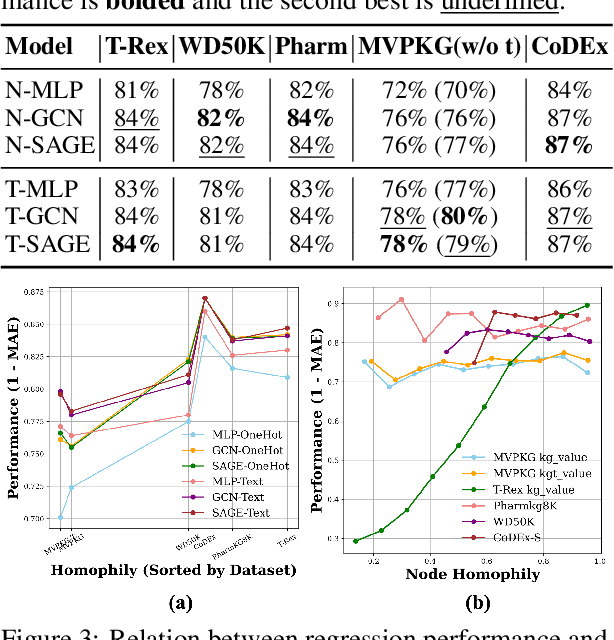
Large language models have been extensively studied as neural knowledge bases for their knowledge access, editability, reasoning, and explainability. However, few works focus on the structural patterns of their knowledge. Motivated by this gap, we investigate these structural patterns from a graph perspective. We quantify the knowledge of LLMs at both the triplet and entity levels, and analyze how it relates to graph structural properties such as node degree. Furthermore, we uncover the knowledge homophily, where topologically close entities exhibit similar levels of knowledgeability, which further motivates us to develop graph machine learning models to estimate entity knowledge based on its local neighbors. This model further enables valuable knowledge checking by selecting triplets less known to LLMs. Empirical results show that using selected triplets for fine-tuning leads to superior performance.