 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025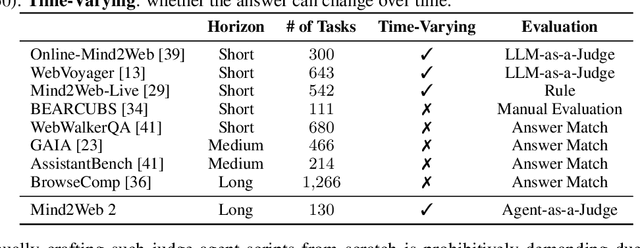
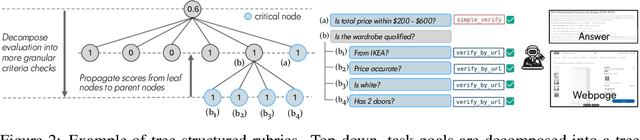

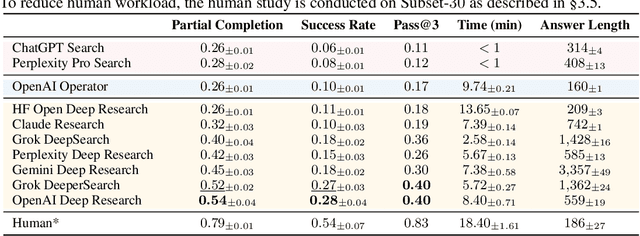
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
Probing Association Biases in LLM Moderation Over-Sensitivity
May 29, 2025Large Language Models are widely used for content moderation but often misclassify benign comments as toxic, leading to over-sensitivity. While previous research attributes this issue primarily to the presence of offensive terms, we reveal a potential cause beyond token level: LLMs exhibit systematic topic biases in their implicit associations. Inspired by cognitive psychology's implicit association tests, we introduce Topic Association Analysis, a semantic-level approach to quantify how LLMs associate certain topics with toxicity. By prompting LLMs to generate free-form scenario imagination for misclassified benign comments and analyzing their topic amplification levels, we find that more advanced models (e.g., GPT-4 Turbo) demonstrate stronger topic stereotype despite lower overall false positive rates. These biases suggest that LLMs do not merely react to explicit, offensive language but rely on learned topic associations, shaping their moderation decisions. Our findings highlight the need for refinement beyond keyword-based filtering, providing insights into the underlying mechanisms driving LLM over-sensitivity.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024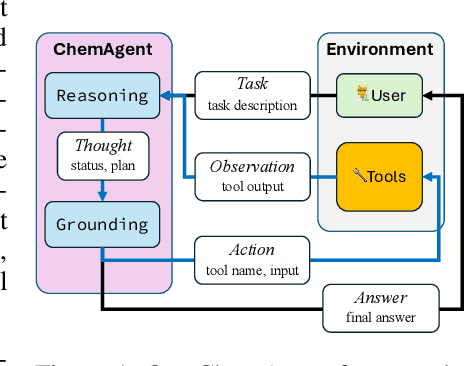
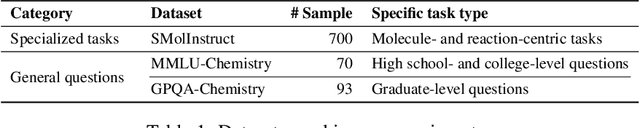

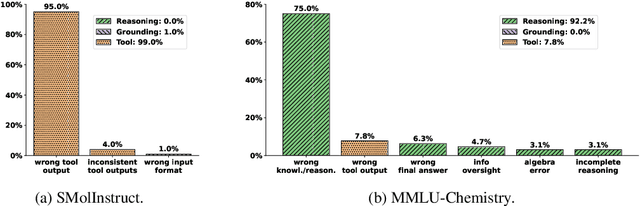
To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Sep 04, 2024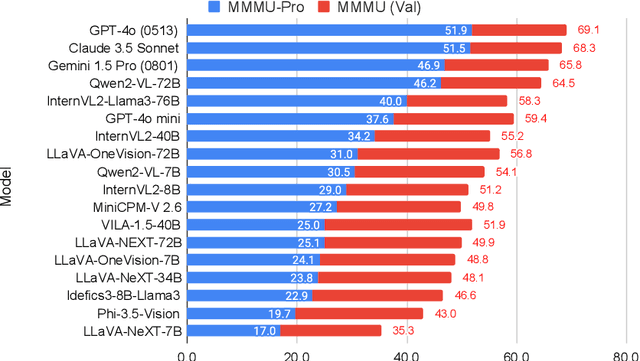
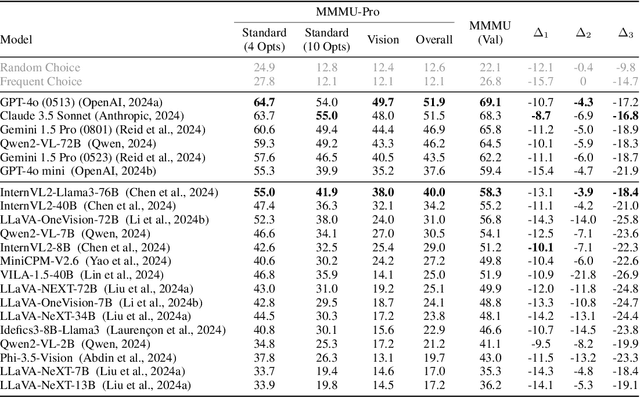


This paper introduces MMMU-Pro, a robust version of the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark. MMMU-Pro rigorously assesses multimodal models' true understanding and reasoning capabilities through a three-step process based on MMMU: (1) filtering out questions answerable by text-only models, (2) augmenting candidate options, and (3) introducing a vision-only input setting where questions are embedded within images. This setting challenges AI to truly "see" and "read" simultaneously, testing a fundamental human cognitive skill of seamlessly integrating visual and textual information. Results show that model performance is substantially lower on MMMU-Pro than on MMMU, ranging from 16.8% to 26.9% across models. We explore the impact of OCR prompts and Chain of Thought (CoT) reasoning, finding that OCR prompts have minimal effect while CoT generally improves performance. MMMU-Pro provides a more rigorous evaluation tool, closely mimicking real-world scenarios and offering valuable directions for future research in multimodal AI.
LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset
Feb 17, 2024



Chemistry plays a crucial role in many domains, such as drug discovery and material science. While large language models (LLMs) such as GPT-4 exhibit remarkable capabilities on natural language processing tasks, existing work shows their performance on chemistry tasks is discouragingly low. In this paper, however, we demonstrate that our developed LLMs can achieve very strong results on a comprehensive set of chemistry tasks, outperforming the most advanced GPT-4 across all the tasks by a substantial margin and approaching the SoTA task-specific models. The key to our success is a large-scale, comprehensive, high-quality dataset for instruction tuning named SMolInstruct. It contains 14 meticulously selected chemistry tasks and over three million high-quality samples, laying a solid foundation for training and evaluating LLMs for chemistry. Based on SMolInstruct, we fine-tune a set of open-source LLMs, among which, we find that Mistral serves as the best base model for chemistry tasks. We further conduct analysis on the impact of trainable parameters, providing insights for future research.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023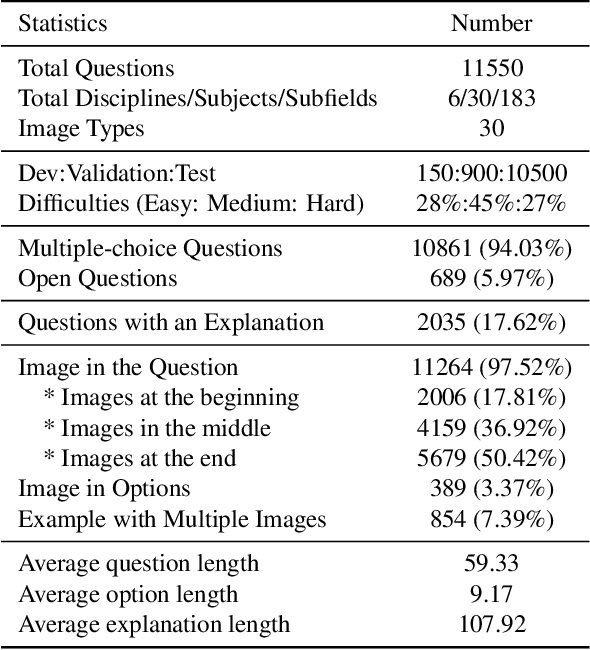

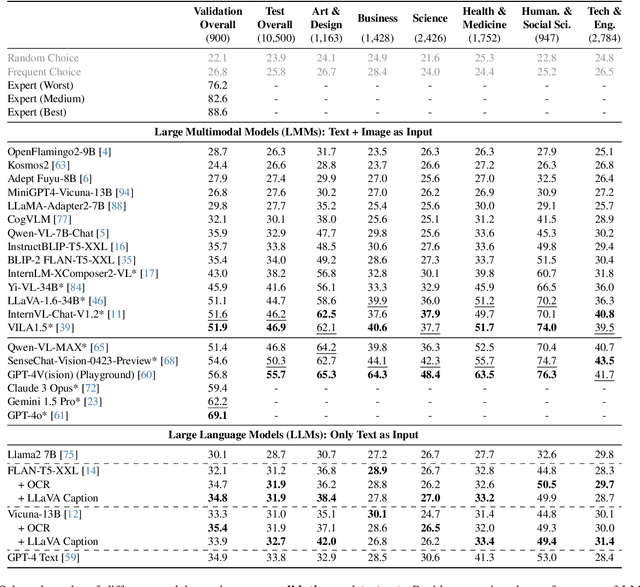
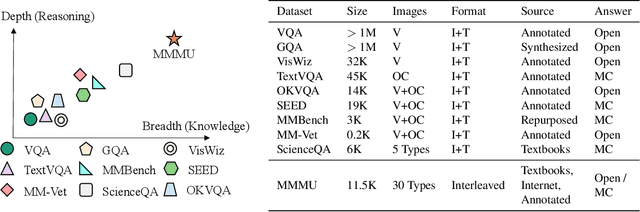
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
EmoGen: Eliminating Subjective Bias in Emotional Music Generation
Jul 03, 2023



Music is used to convey emotions, and thus generating emotional music is important in automatic music generation. Previous work on emotional music generation directly uses annotated emotion labels as control signals, which suffers from subjective bias: different people may annotate different emotions on the same music, and one person may feel different emotions under different situations. Therefore, directly mapping emotion labels to music sequences in an end-to-end way would confuse the learning process and hinder the model from generating music with general emotions. In this paper, we propose EmoGen, an emotional music generation system that leverages a set of emotion-related music attributes as the bridge between emotion and music, and divides the generation into two stages: emotion-to-attribute mapping with supervised clustering, and attribute-to-music generation with self-supervised learning. Both stages are beneficial: in the first stage, the attribute values around the clustering center represent the general emotions of these samples, which help eliminate the impacts of the subjective bias of emotion labels; in the second stage, the generation is completely disentangled from emotion labels and thus free from the subjective bias. Both subjective and objective evaluations show that EmoGen outperforms previous methods on emotion control accuracy and music quality respectively, which demonstrate our superiority in generating emotional music. Music samples generated by EmoGen are available via this link:https://ai-muzic.github.io/emogen/, and the code is available at this link:https://github.com/microsoft/muzic/.
MuseCoco: Generating Symbolic Music from Text
May 31, 2023



Generating music from text descriptions is a user-friendly mode since the text is a relatively easy interface for user engagement. While some approaches utilize texts to control music audio generation, editing musical elements in generated audio is challenging for users. In contrast, symbolic music offers ease of editing, making it more accessible for users to manipulate specific musical elements. In this paper, we propose MuseCoco, which generates symbolic music from text descriptions with musical attributes as the bridge to break down the task into text-to-attribute understanding and attribute-to-music generation stages. MuseCoCo stands for Music Composition Copilot that empowers musicians to generate music directly from given text descriptions, offering a significant improvement in efficiency compared to creating music entirely from scratch. The system has two main advantages: Firstly, it is data efficient. In the attribute-to-music generation stage, the attributes can be directly extracted from music sequences, making the model training self-supervised. In the text-to-attribute understanding stage, the text is synthesized and refined by ChatGPT based on the defined attribute templates. Secondly, the system can achieve precise control with specific attributes in text descriptions and offers multiple control options through attribute-conditioned or text-conditioned approaches. MuseCoco outperforms baseline systems in terms of musicality, controllability, and overall score by at least 1.27, 1.08, and 1.32 respectively. Besides, there is a notable enhancement of about 20% in objective control accuracy. In addition, we have developed a robust large-scale model with 1.2 billion parameters, showcasing exceptional controllability and musicality.