 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
Oct 25, 2023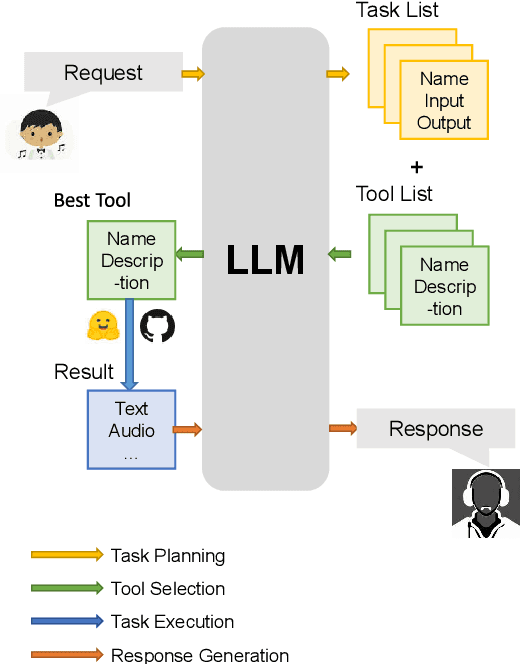
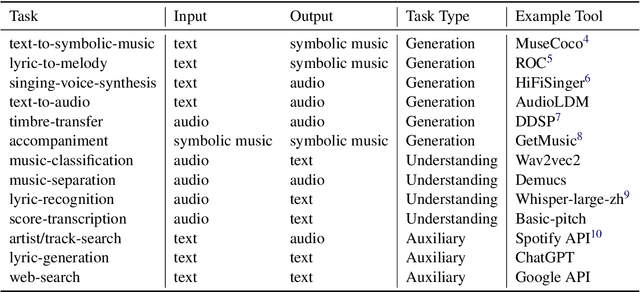
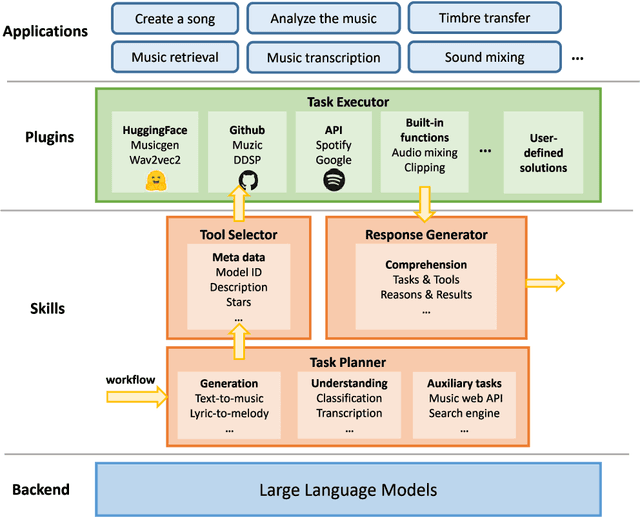
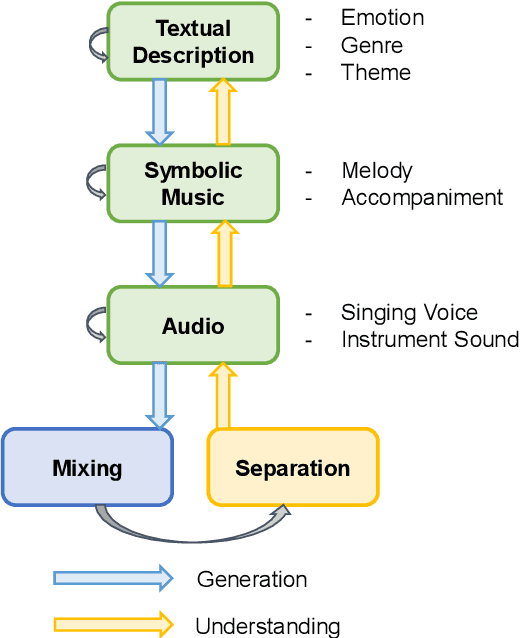
AI-empowered music processing is a diverse field that encompasses dozens of tasks, ranging from generation tasks (e.g., timbre synthesis) to comprehension tasks (e.g., music classification). For developers and amateurs, it is very difficult to grasp all of these task to satisfy their requirements in music processing, especially considering the huge differences in the representations of music data and the model applicability across platforms among various tasks. Consequently, it is necessary to build a system to organize and integrate these tasks, and thus help practitioners to automatically analyze their demand and call suitable tools as solutions to fulfill their requirements. Inspired by the recent success of large language models (LLMs) in task automation, we develop a system, named MusicAgent, which integrates numerous music-related tools and an autonomous workflow to address user requirements. More specifically, we build 1) toolset that collects tools from diverse sources, including Hugging Face, GitHub, and Web API, etc. 2) an autonomous workflow empowered by LLMs (e.g., ChatGPT) to organize these tools and automatically decompose user requests into multiple sub-tasks and invoke corresponding music tools. The primary goal of this system is to free users from the intricacies of AI-music tools, enabling them to concentrate on the creative aspect. By granting users the freedom to effortlessly combine tools, the system offers a seamless and enriching music experience.
EmoGen: Eliminating Subjective Bias in Emotional Music Generation
Jul 03, 2023



Music is used to convey emotions, and thus generating emotional music is important in automatic music generation. Previous work on emotional music generation directly uses annotated emotion labels as control signals, which suffers from subjective bias: different people may annotate different emotions on the same music, and one person may feel different emotions under different situations. Therefore, directly mapping emotion labels to music sequences in an end-to-end way would confuse the learning process and hinder the model from generating music with general emotions. In this paper, we propose EmoGen, an emotional music generation system that leverages a set of emotion-related music attributes as the bridge between emotion and music, and divides the generation into two stages: emotion-to-attribute mapping with supervised clustering, and attribute-to-music generation with self-supervised learning. Both stages are beneficial: in the first stage, the attribute values around the clustering center represent the general emotions of these samples, which help eliminate the impacts of the subjective bias of emotion labels; in the second stage, the generation is completely disentangled from emotion labels and thus free from the subjective bias. Both subjective and objective evaluations show that EmoGen outperforms previous methods on emotion control accuracy and music quality respectively, which demonstrate our superiority in generating emotional music. Music samples generated by EmoGen are available via this link:https://ai-muzic.github.io/emogen/, and the code is available at this link:https://github.com/microsoft/muzic/.
MuseCoco: Generating Symbolic Music from Text
May 31, 2023



Generating music from text descriptions is a user-friendly mode since the text is a relatively easy interface for user engagement. While some approaches utilize texts to control music audio generation, editing musical elements in generated audio is challenging for users. In contrast, symbolic music offers ease of editing, making it more accessible for users to manipulate specific musical elements. In this paper, we propose MuseCoco, which generates symbolic music from text descriptions with musical attributes as the bridge to break down the task into text-to-attribute understanding and attribute-to-music generation stages. MuseCoCo stands for Music Composition Copilot that empowers musicians to generate music directly from given text descriptions, offering a significant improvement in efficiency compared to creating music entirely from scratch. The system has two main advantages: Firstly, it is data efficient. In the attribute-to-music generation stage, the attributes can be directly extracted from music sequences, making the model training self-supervised. In the text-to-attribute understanding stage, the text is synthesized and refined by ChatGPT based on the defined attribute templates. Secondly, the system can achieve precise control with specific attributes in text descriptions and offers multiple control options through attribute-conditioned or text-conditioned approaches. MuseCoco outperforms baseline systems in terms of musicality, controllability, and overall score by at least 1.27, 1.08, and 1.32 respectively. Besides, there is a notable enhancement of about 20% in objective control accuracy. In addition, we have developed a robust large-scale model with 1.2 billion parameters, showcasing exceptional controllability and musicality.
GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework
May 18, 2023Symbolic music generation aims to create musical notes, which can help users compose music, such as generating target instrumental tracks from scratch, or based on user-provided source tracks. Considering the diverse and flexible combination between source and target tracks, a unified model capable of generating any arbitrary tracks is of crucial necessity. Previous works fail to address this need due to inherent constraints in music representations and model architectures. To address this need, we propose a unified representation and diffusion framework named GETMusic (`GET' stands for GEnerate music Tracks), which includes a novel music representation named GETScore, and a diffusion model named GETDiff. GETScore represents notes as tokens and organizes them in a 2D structure, with tracks stacked vertically and progressing horizontally over time. During training, tracks are randomly selected as either the target or source. In the forward process, target tracks are corrupted by masking their tokens, while source tracks remain as ground truth. In the denoising process, GETDiff learns to predict the masked target tokens, conditioning on the source tracks. With separate tracks in GETScore and the non-autoregressive behavior of the model, GETMusic can explicitly control the generation of any target tracks from scratch or conditioning on source tracks. We conduct experiments on music generation involving six instrumental tracks, resulting in a total of 665 combinations. GETMusic provides high-quality results across diverse combinations and surpasses prior works proposed for some specific combinations.
Museformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
Oct 19, 2022
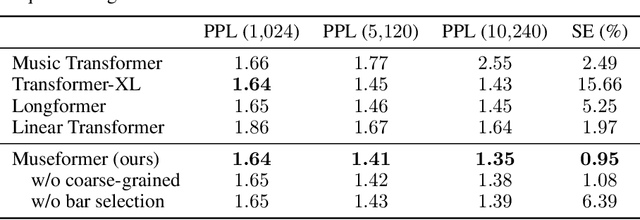
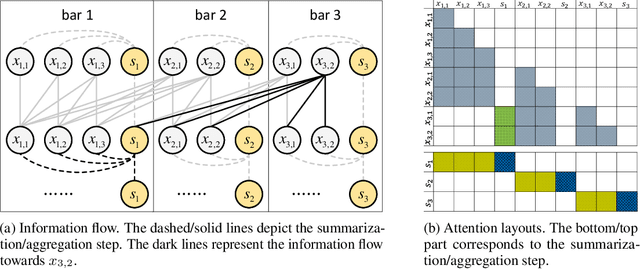
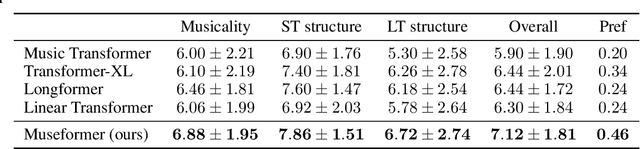
Symbolic music generation aims to generate music scores automatically. A recent trend is to use Transformer or its variants in music generation, which is, however, suboptimal, because the full attention cannot efficiently model the typically long music sequences (e.g., over 10,000 tokens), and the existing models have shortcomings in generating musical repetition structures. In this paper, we propose Museformer, a Transformer with a novel fine- and coarse-grained attention for music generation. Specifically, with the fine-grained attention, a token of a specific bar directly attends to all the tokens of the bars that are most relevant to music structures (e.g., the previous 1st, 2nd, 4th and 8th bars, selected via similarity statistics); with the coarse-grained attention, a token only attends to the summarization of the other bars rather than each token of them so as to reduce the computational cost. The advantages are two-fold. First, it can capture both music structure-related correlations via the fine-grained attention, and other contextual information via the coarse-grained attention. Second, it is efficient and can model over 3X longer music sequences compared to its full-attention counterpart. Both objective and subjective experimental results demonstrate its ability to generate long music sequences with high quality and better structures.
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
Aug 30, 2022
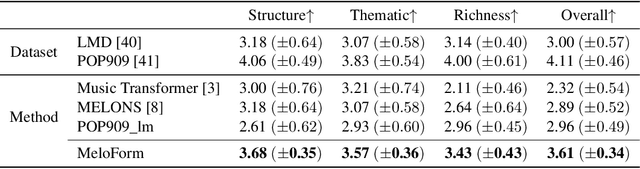
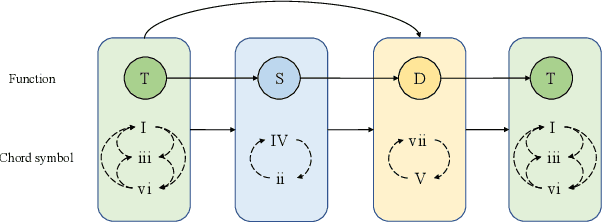
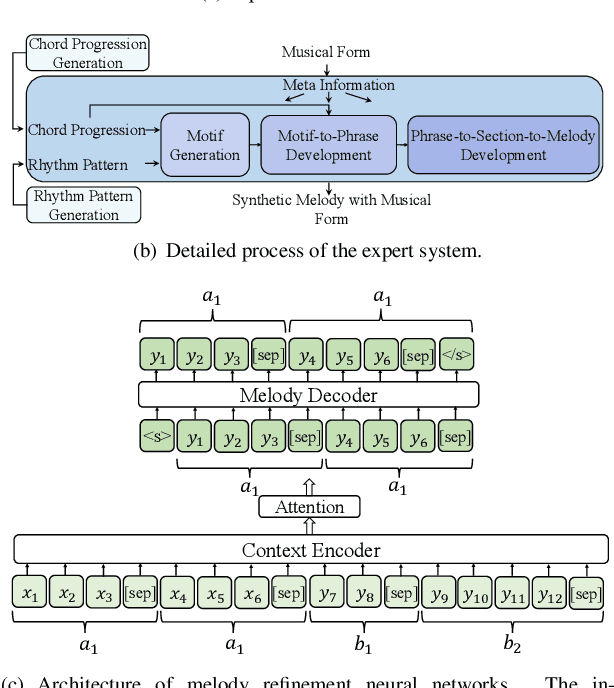
Human usually composes music by organizing elements according to the musical form to express music ideas. However, for neural network-based music generation, it is difficult to do so due to the lack of labelled data on musical form. In this paper, we develop MeloForm, a system that generates melody with musical form using expert systems and neural networks. Specifically, 1) we design an expert system to generate a melody by developing musical elements from motifs to phrases then to sections with repetitions and variations according to pre-given musical form; 2) considering the generated melody is lack of musical richness, we design a Transformer based refinement model to improve the melody without changing its musical form. MeloForm enjoys the advantages of precise musical form control by expert systems and musical richness learning via neural models. Both subjective and objective experimental evaluations demonstrate that MeloForm generates melodies with precise musical form control with 97.79% accuracy, and outperforms baseline systems in terms of subjective evaluation score by 0.75, 0.50, 0.86 and 0.89 in structure, thematic, richness and overall quality, without any labelled musical form data. Besides, MeloForm can support various kinds of forms, such as verse and chorus form, rondo form, variational form, sonata form, etc.
TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method
Sep 20, 2021
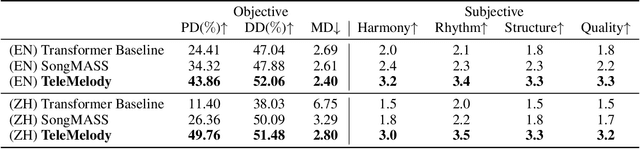
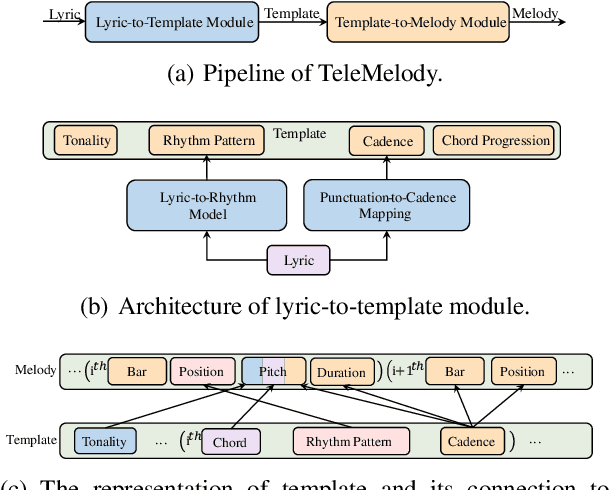
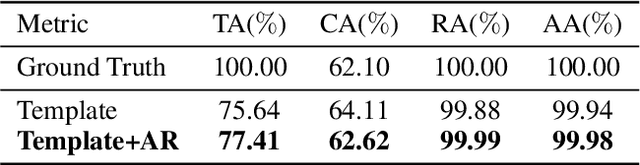
Lyric-to-melody generation is an important task in automatic songwriting. Previous lyric-to-melody generation systems usually adopt end-to-end models that directly generate melodies from lyrics, which suffer from several issues: 1) lack of paired lyric-melody training data; 2) lack of control on generated melodies. In this paper, we develop TeleMelody, a two-stage lyric-to-melody generation system with music template (e.g., tonality, chord progression, rhythm pattern, and cadence) to bridge the gap between lyrics and melodies (i.e., the system consists of a lyric-to-template module and a template-to-melody module). TeleMelody has two advantages. First, it is data efficient. The template-to-melody module is trained in a self-supervised way (i.e., the source template is extracted from the target melody) that does not need any lyric-melody paired data. The lyric-to-template module is made up of some rules and a lyric-to-rhythm model, which is trained with paired lyric-rhythm data that is easier to obtain than paired lyric-melody data. Second, it is controllable. The design of template ensures that the generated melodies can be controlled by adjusting the musical elements in template. Both subjective and objective experimental evaluations demonstrate that TeleMelody generates melodies with higher quality, better controllability, and less requirement on paired lyric-melody data than previous generation systems.
XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
Jun 11, 2020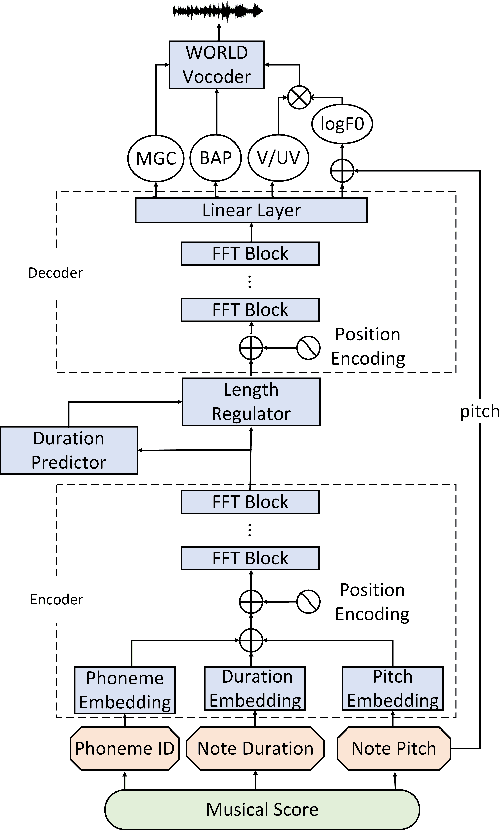
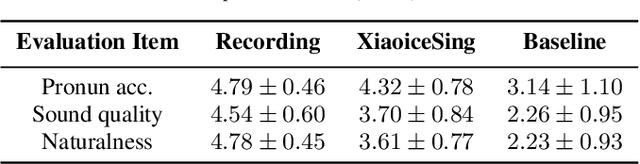
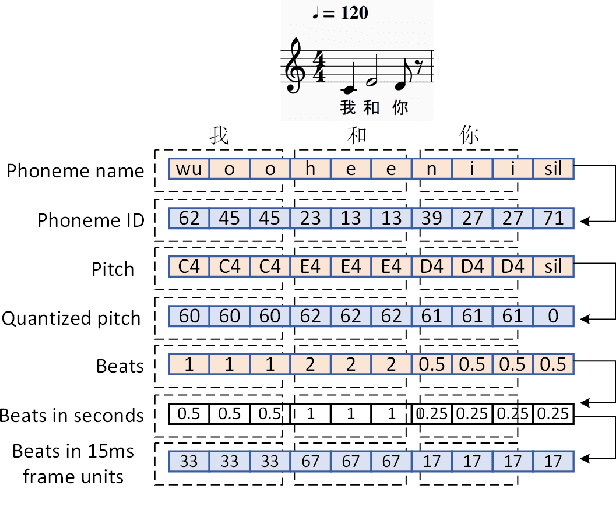
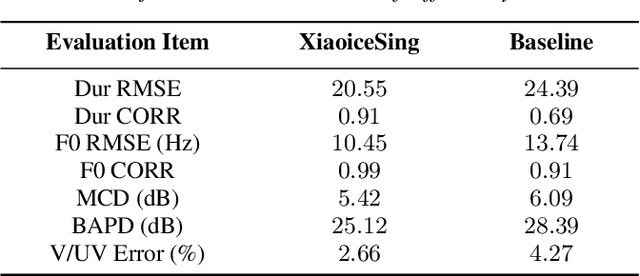
This paper presents XiaoiceSing, a high-quality singing voice synthesis system which employs an integrated network for spectrum, F0 and duration modeling. We follow the main architecture of FastSpeech while proposing some singing-specific design: 1) Besides phoneme ID and position encoding, features from musical score (e.g.note pitch and length) are also added. 2) To attenuate off-key issues, we add a residual connection in F0 prediction. 3) In addition to the duration loss of each phoneme, the duration of all the phonemes in a musical note is accumulated to calculate the syllable duration loss for rhythm enhancement. Experiment results show that XiaoiceSing outperforms the baseline system of convolutional neural networks by 1.44 MOS on sound quality, 1.18 on pronunciation accuracy and 1.38 on naturalness respectively. In two A/B tests, the proposed F0 and duration modeling methods achieve 97.3% and 84.3% preference rate over baseline respectively, which demonstrates the overwhelming advantages of XiaoiceSing.