 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
Paper and Code
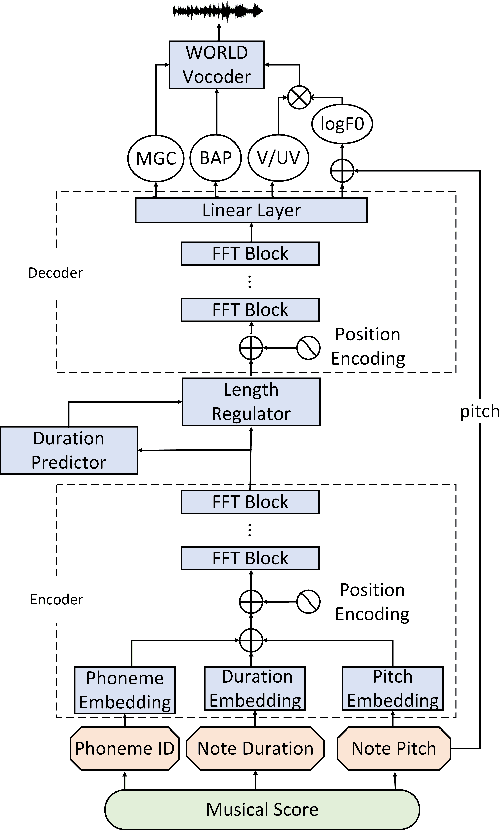
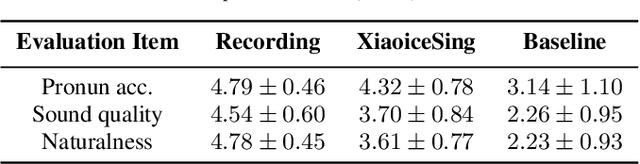
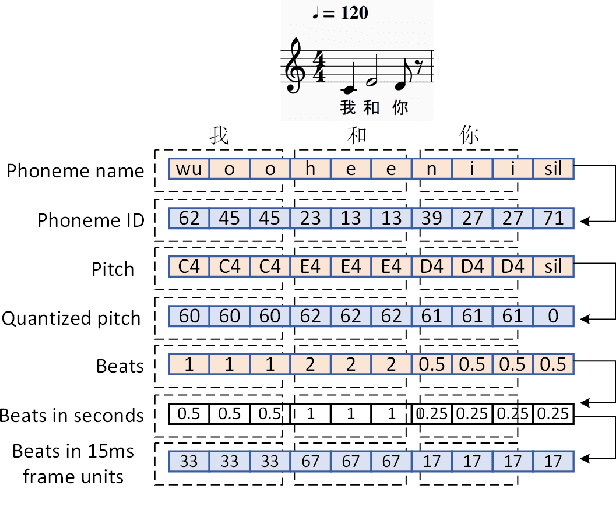
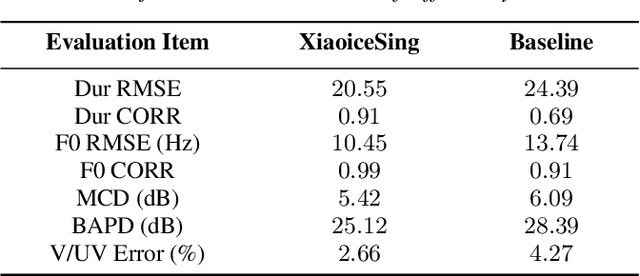
This paper presents XiaoiceSing, a high-quality singing voice synthesis system which employs an integrated network for spectrum, F0 and duration modeling. We follow the main architecture of FastSpeech while proposing some singing-specific design: 1) Besides phoneme ID and position encoding, features from musical score (e.g.note pitch and length) are also added. 2) To attenuate off-key issues, we add a residual connection in F0 prediction. 3) In addition to the duration loss of each phoneme, the duration of all the phonemes in a musical note is accumulated to calculate the syllable duration loss for rhythm enhancement. Experiment results show that XiaoiceSing outperforms the baseline system of convolutional neural networks by 1.44 MOS on sound quality, 1.18 on pronunciation accuracy and 1.38 on naturalness respectively. In two A/B tests, the proposed F0 and duration modeling methods achieve 97.3% and 84.3% preference rate over baseline respectively, which demonstrates the overwhelming advantages of XiaoiceSing.