 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Loop: Universal Repository Representation with RPG-Encoder
Feb 03, 2026Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art localization performance on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% in localization accuracy on SWE-bench Live Lite. These results highlight our superior fine-grained precision in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.
Sim-MSTNet: sim2real based Multi-task SpatioTemporal Network Traffic Forecasting
Jan 29, 2026Network traffic forecasting plays a crucial role in intelligent network operations, but existing techniques often perform poorly when faced with limited data. Additionally, multi-task learning methods struggle with task imbalance and negative transfer, especially when modeling various service types. To overcome these challenges, we propose Sim-MSTNet, a multi-task spatiotemporal network traffic forecasting model based on the sim2real approach. Our method leverages a simulator to generate synthetic data, effectively addressing the issue of poor generalization caused by data scarcity. By employing a domain randomization technique, we reduce the distributional gap between synthetic and real data through bi-level optimization of both sample weighting and model training. Moreover, Sim-MSTNet incorporates attention-based mechanisms to selectively share knowledge between tasks and applies dynamic loss weighting to balance task objectives. Extensive experiments on two open-source datasets show that Sim-MSTNet consistently outperforms state-of-the-art baselines, achieving enhanced accuracy and generalization.
LoL: Longer than Longer, Scaling Video Generation to Hour
Jan 23, 2026Recent research in long-form video generation has shifted from bidirectional to autoregressive models, yet these methods commonly suffer from error accumulation and a loss of long-term coherence. While attention sink frames have been introduced to mitigate this performance decay, they often induce a critical failure mode we term sink-collapse: the generated content repeatedly reverts to the sink frame, resulting in abrupt scene resets and cyclic motion patterns. Our analysis reveals that sink-collapse originates from an inherent conflict between the periodic structure of Rotary Position Embedding (RoPE) and the multi-head attention mechanisms prevalent in current generative models. To address it, we propose a lightweight, training-free approach that effectively suppresses this behavior by introducing multi-head RoPE jitter that breaks inter-head attention homogenization and mitigates long-horizon collapse. Extensive experiments show that our method successfully alleviates sink-collapse while preserving generation quality. To the best of our knowledge, this work achieves the first demonstration of real-time, streaming, and infinite-length video generation with little quality decay. As an illustration of this robustness, we generate continuous videos up to 12 hours in length, which, to our knowledge, is among the longest publicly demonstrated results in streaming video generation.
X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
Jan 11, 2026Competitive programming presents great challenges for Code LLMs due to its intensive reasoning demands and high logical complexity. However, current Code LLMs still rely heavily on real-world data, which limits their scalability. In this paper, we explore a fully synthetic approach: training Code LLMs with entirely generated tasks, solutions, and test cases, to empower code reasoning models without relying on real-world data. To support this, we leverage feature-based synthesis to propose a novel data synthesis pipeline called SynthSmith. SynthSmith shows strong potential in producing diverse and challenging tasks, along with verified solutions and tests, supporting both supervised fine-tuning and reinforcement learning. Based on the proposed synthetic SFT and RL datasets, we introduce the X-Coder model series, which achieves a notable pass rate of 62.9 avg@8 on LiveCodeBench v5 and 55.8 on v6, outperforming DeepCoder-14B-Preview and AReal-boba2-14B despite having only 7B parameters. In-depth analysis reveals that scaling laws hold on our synthetic dataset, and we explore which dimensions are more effective to scale. We further provide insights into code-centric reinforcement learning and highlight the key factors that shape performance through detailed ablations and analysis. Our findings demonstrate that scaling high-quality synthetic data and adopting staged training can greatly advance code reasoning, while mitigating reliance on real-world coding data.
DHI: Leveraging Diverse Hallucination Induction for Enhanced Contrastive Factuality Control in Large Language Models
Jan 03, 2026Large language models (LLMs) frequently produce inaccurate or fabricated information, known as "hallucinations," which compromises their reliability. Existing approaches often train an "Evil LLM" to deliberately generate hallucinations on curated datasets, using these induced hallucinations to guide contrastive decoding against a reliable "positive model" for hallucination mitigation. However, this strategy is limited by the narrow diversity of hallucinations induced, as Evil LLMs trained on specific error types tend to reproduce only these particular patterns, thereby restricting their overall effectiveness. To address these limitations, we propose DHI (Diverse Hallucination Induction), a novel training framework that enables the Evil LLM to generate a broader range of hallucination types without relying on pre-annotated hallucination data. DHI employs a modified loss function that down-weights the generation of specific factually correct tokens, encouraging the Evil LLM to produce diverse hallucinations at targeted positions while maintaining overall factual content. Additionally, we introduce a causal attention masking adaptation to reduce the impact of this penalization on the generation of subsequent tokens. During inference, we apply an adaptive rationality constraint that restricts contrastive decoding to tokens where the positive model exhibits high confidence, thereby avoiding unnecessary penalties on factually correct tokens. Extensive empirical results show that DHI achieves significant performance gains over other contrastive decoding-based approaches across multiple hallucination benchmarks.
SongSage: A Large Musical Language Model with Lyric Generative Pre-training
Jan 03, 2026Large language models have achieved significant success in various domains, yet their understanding of lyric-centric knowledge has not been fully explored. In this work, we first introduce PlaylistSense, a dataset to evaluate the playlist understanding capability of language models. PlaylistSense encompasses ten types of user queries derived from common real-world perspectives, challenging LLMs to accurately grasp playlist features and address diverse user intents. Comprehensive evaluations indicate that current general-purpose LLMs still have potential for improvement in playlist understanding. Inspired by this, we introduce SongSage, a large musical language model equipped with diverse lyric-centric intelligence through lyric generative pretraining. SongSage undergoes continual pretraining on LyricBank, a carefully curated corpus of 5.48 billion tokens focused on lyrical content, followed by fine-tuning with LyricBank-SFT, a meticulously crafted instruction set comprising 775k samples across nine core lyric-centric tasks. Experimental results demonstrate that SongSage exhibits a strong understanding of lyric-centric knowledge, excels in rewriting user queries for zero-shot playlist recommendations, generates and continues lyrics effectively, and performs proficiently across seven additional capabilities. Beyond its lyric-centric expertise, SongSage also retains general knowledge comprehension and achieves a competitive MMLU score. We will keep the datasets inaccessible due to copyright restrictions and release the SongSage and training script to ensure reproducibility and support music AI research and applications, the datasets release plan details are provided in the appendix.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
DK-STN: A Domain Knowledge Embedded Spatio-Temporal Network Model for MJO Forecast
Dec 22, 2025
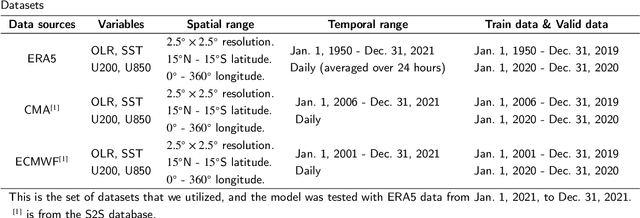


Understanding and predicting the Madden-Julian Oscillation (MJO) is fundamental for precipitation forecasting and disaster prevention. To date, long-term and accurate MJO prediction has remained a challenge for researchers. Conventional MJO prediction methods using Numerical Weather Prediction (NWP) are resource-intensive, time-consuming, and highly unstable (most NWP methods are sensitive to seasons, with better MJO forecast results in winter). While existing Artificial Neural Network (ANN) methods save resources and speed forecasting, their accuracy never reaches the 28 days predicted by the state-of-the-art NWP method, i.e., the operational forecasts from ECMWF, since neural networks cannot handle climate data effectively. In this paper, we present a Domain Knowledge Embedded Spatio-Temporal Network (DK-STN), a stable neural network model for accurate and efficient MJO forecasting. It combines the benefits of NWP and ANN methods and successfully improves the forecast accuracy of ANN methods while maintaining a high level of efficiency and stability. We begin with a spatial-temporal network (STN) and embed domain knowledge in it using two key methods: (i) applying a domain knowledge enhancement method and (ii) integrating a domain knowledge processing method into network training. We evaluated DK-STN with the 5th generation of ECMWF reanalysis (ERA5) data and compared it with ECMWF. Given 7 days of climate data as input, DK-STN can generate reliable forecasts for the following 28 days in 1-2 seconds, with an error of only 2-3 days in different seasons. DK-STN significantly exceeds ECMWF in that its forecast accuracy is equivalent to ECMWF's, while its efficiency and stability are significantly superior.
The Complete Anatomy of the Madden-Julian Oscillation Revealed by Artificial Intelligence
Dec 14, 2025Accurately defining the life cycle of the Madden-Julian Oscillation (MJO), the dominant mode of intraseasonal climate variability, remains a foundational challenge due to its propagating nature. The established linear-projection method (RMM index) often conflates mathematical artifacts with physical states, while direct clustering in raw data space is confounded by a "propagation penalty." Here, we introduce an "AI-for-theory" paradigm to objectively discover the MJO's intrinsic structure. We develop a deep learning model, PhysAnchor-MJO-AE, to learn a latent representation where vector distance corresponds to physical-feature similarity, enabling objective clustering of MJO dynamical states. Clustering these "MJO fingerprints" reveals the first complete, six-phase anatomical map of its life cycle. This taxonomy refines and critically completes the classical view by objectively isolating two long-hypothesized transitional phases: organizational growth over the Indian Ocean and the northward shift over the Philippine Sea. Derived from this anatomy, we construct a new physics-coherent monitoring framework that decouples location and intensity diagnostics. This framework reduces the rates of spurious propagation and convective misplacement by over an order of magnitude compared to the classical index. Our work transforms AI from a forecasting tool into a discovery microscope, establishing a reproducible template for extracting fundamental dynamical constructs from complex systems.
Rank-Aware Agglomeration of Foundation Models for Immunohistochemistry Image Cell Counting
Nov 16, 2025Accurate cell counting in immunohistochemistry (IHC) images is critical for quantifying protein expression and aiding cancer diagnosis. However, the task remains challenging due to the chromogen overlap, variable biomarker staining, and diverse cellular morphologies. Regression-based counting methods offer advantages over detection-based ones in handling overlapped cells, yet rarely support end-to-end multi-class counting. Moreover, the potential of foundation models remains largely underexplored in this paradigm. To address these limitations, we propose a rank-aware agglomeration framework that selectively distills knowledge from multiple strong foundation models, leveraging their complementary representations to handle IHC heterogeneity and obtain a compact yet effective student model, CountIHC. Unlike prior task-agnostic agglomeration strategies that either treat all teachers equally or rely on feature similarity, we design a Rank-Aware Teacher Selecting (RATS) strategy that models global-to-local patch rankings to assess each teacher's inherent counting capacity and enable sample-wise teacher selection. For multi-class cell counting, we introduce a fine-tuning stage that reformulates the task as vision-language alignment. Discrete semantic anchors derived from structured text prompts encode both category and quantity information, guiding the regression of class-specific density maps and improving counting for overlapping cells. Extensive experiments demonstrate that CountIHC surpasses state-of-the-art methods across 12 IHC biomarkers and 5 tissue types, while exhibiting high agreement with pathologists' assessments. Its effectiveness on H&E-stained data further confirms the scalability of the proposed method.