 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Rejection Sampling: Trajectory Fusion for Scaling Mathematical Reasoning
Feb 04, 2026Large language models (LLMs) have made impressive strides in mathematical reasoning, often fine-tuned using rejection sampling that retains only correct reasoning trajectories. While effective, this paradigm treats supervision as a binary filter that systematically excludes teacher-generated errors, leaving a gap in how reasoning failures are modeled during training. In this paper, we propose TrajFusion, a fine-tuning strategy that reframes rejection sampling as a structured supervision construction process. Specifically, TrajFusion forms fused trajectories that explicitly model trial-and-error reasoning by interleaving selected incorrect trajectories with reflection prompts and correct trajectories. The length of each fused sample is adaptively controlled based on the frequency and diversity of teacher errors, providing richer supervision for challenging problems while safely reducing to vanilla rejection sampling fine-tuning (RFT) when error signals are uninformative. TrajFusion requires no changes to the architecture or training objective. Extensive experiments across multiple math benchmarks demonstrate that TrajFusion consistently outperforms RFT, particularly on challenging and long-form reasoning problems.
ConPress: Learning Efficient Reasoning from Multi-Question Contextual Pressure
Feb 01, 2026Large reasoning models (LRMs) typically solve reasoning-intensive tasks by generating long chain-of-thought (CoT) traces, leading to substantial inference overhead. We identify a reproducible inference-time phenomenon, termed Self-Compression: when multiple independent and answerable questions are presented within a single prompt, the model spontaneously produces shorter reasoning traces for each question. This phenomenon arises from multi-question contextual pressure during generation and consistently manifests across models and benchmarks. Building on this observation, we propose ConPress (Learning from Contextual Pressure), a lightweight self-supervised fine-tuning approach. ConPress constructs multi-question prompts to induce self-compression, samples the resulting model outputs, and parses and filters per-question traces to obtain concise yet correct reasoning trajectories. These trajectories are directly used for supervised fine-tuning, internalizing compressed reasoning behavior in single-question settings without external teachers, manual pruning, or reinforcement learning. With only 8k fine-tuning examples, ConPress reduces reasoning token usage by 59% on MATH500 and 33% on AIME25, while maintaining competitive accuracy.
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
MuDAF: Long-Context Multi-Document Attention Focusing through Contrastive Learning on Attention Heads
Feb 19, 2025Large Language Models (LLMs) frequently show distracted attention due to irrelevant information in the input, which severely impairs their long-context capabilities. Inspired by recent studies on the effectiveness of retrieval heads in long-context factutality, we aim at addressing this distraction issue through improving such retrieval heads directly. We propose Multi-Document Attention Focusing (MuDAF), a novel method that explicitly optimizes the attention distribution at the head level through contrastive learning. According to the experimental results, MuDAF can significantly improve the long-context question answering performance of LLMs, especially in multi-document question answering. Extensive evaluations on retrieval scores and attention visualizations show that MuDAF possesses great potential in making attention heads more focused on relevant information and reducing attention distractions.
Towards Truthful Multilingual Large Language Models: Benchmarking and Alignment Strategies
Jun 20, 2024In the era of large language models (LLMs), building multilingual large language models (MLLMs) that can serve users worldwide holds great significance. However, existing research seldom focuses on the truthfulness of MLLMs. Meanwhile, contemporary multilingual aligning technologies struggle to balance massive languages and often exhibit serious truthfulness gaps across different languages, especially those that differ greatly from English. In our work, we construct a benchmark for truthfulness evaluation in multilingual scenarios and explore the ways to align facts across languages to enhance the truthfulness of MLLMs. Furthermore, we propose Fact-aware Multilingual Selective Synergy (FaMSS) to optimize the data allocation across a large number of languages and different data types. Experimental results demonstrate that our approach can effectively reduce the multilingual representation disparity and enhance the multilingual capabilities of LLMs.
Beyond Surface: Probing LLaMA Across Scales and Layers
Dec 14, 2023This paper presents an in-depth analysis of Large Language Models (LLMs), focusing on LLaMA, a prominent open-source foundational model in natural language processing. Instead of assessing LLaMA through its generative output, we design multiple-choice tasks to probe its intrinsic understanding in high-order tasks such as reasoning and computation. We examine the model horizontally, comparing different sizes, and vertically, assessing different layers. We unveil several key and uncommon findings based on the designed probing tasks: (1) Horizontally, enlarging model sizes almost could not automatically impart additional knowledge or computational prowess. Instead, it can enhance reasoning abilities, especially in math problem solving, and helps reduce hallucinations, but only beyond certain size thresholds; (2) In vertical analysis, the lower layers of LLaMA lack substantial arithmetic and factual knowledge, showcasing logical thinking, multilingual and recognitive abilities, with top layers housing most computational power and real-world knowledge.
Large Language Models are Diverse Role-Players for Summarization Evaluation
Mar 28, 2023Text summarization has a wide range of applications in many scenarios. The evaluation of the quality of the generated text is a complex problem. A big challenge to language evaluation is that there is a clear divergence between existing metrics and human evaluation. For example, the quality of a document summary can be measured by human annotators from both objective aspects, such as grammatical and semantic correctness, as well as subjective dimensions, such as comprehensiveness, succinctness, and interestingness. Most of the automatic evaluation methods like BLUE/ROUGE may be not able to capture the above dimensions well. In this paper, we propose a new evaluation framework based on LLMs, which provides a comprehensive evaluation framework by comparing generated text and reference text from both objective and subjective aspects. First, we propose to model objective and subjective dimensions of generated text based on roleplayers prompting mechanism. Furthermore, we introduce a context-based prompting mechanism that is able to generate dynamic roleplayer profiles based on input context. Finally, we design a multi-roleplayer prompting technology based on batch prompting to integrate multiple evaluation results into evaluation results. Experimental results on two real datasets for summarization show that our model is highly competitive and has a very high consistency with human annotators.
Multi-level Contrastive Learning for Cross-lingual Spoken Language Understanding
May 07, 2022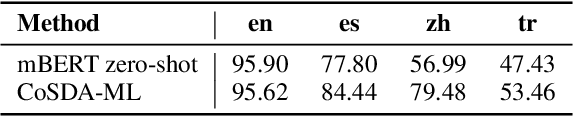

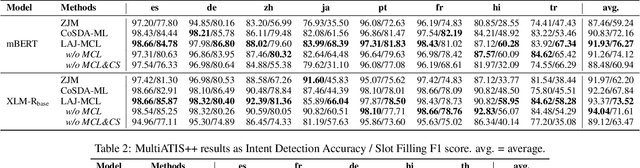
Although spoken language understanding (SLU) has achieved great success in high-resource languages, such as English, it remains challenging in low-resource languages mainly due to the lack of high quality training data. The recent multilingual code-switching approach samples some words in an input utterance and replaces them by expressions in some other languages of the same meaning. The multilingual code-switching approach achieves better alignments of representations across languages in zero-shot cross-lingual SLU. Surprisingly, all existing multilingual code-switching methods disregard the inherent semantic structure in SLU, i.e., most utterances contain one or more slots, and each slot consists of one or more words. In this paper, we propose to exploit the "utterance-slot-word" structure of SLU and systematically model this structure by a multi-level contrastive learning framework at the utterance, slot, and word levels. We develop novel code-switching schemes to generate hard negative examples for contrastive learning at all levels. Furthermore, we develop a label-aware joint model to leverage label semantics for cross-lingual knowledge transfer. Our experimental results show that our proposed methods significantly improve the performance compared with the strong baselines on two zero-shot cross-lingual SLU benchmark datasets.
Reinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Jun 01, 2021
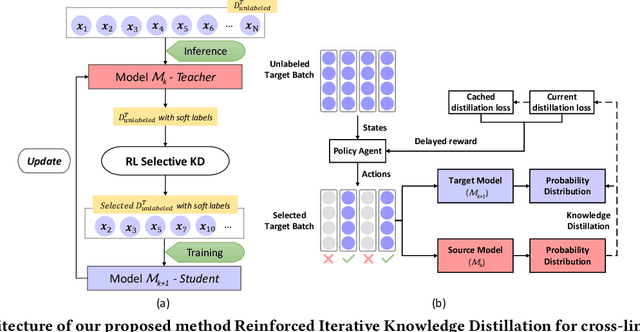

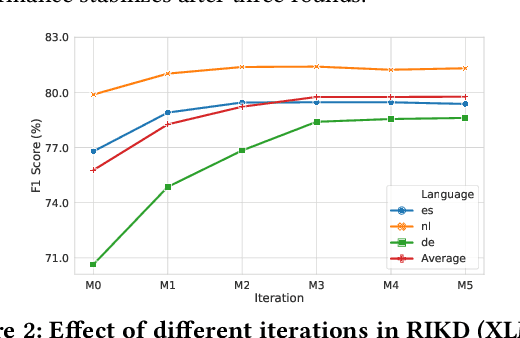
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.
CalibreNet: Calibration Networks for Multilingual Sequence Labeling
Nov 11, 2020

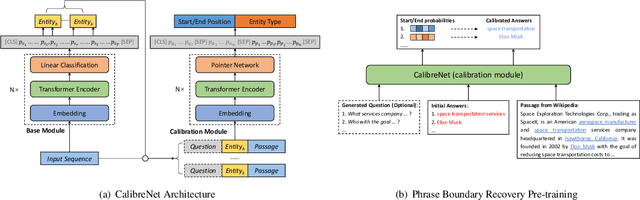
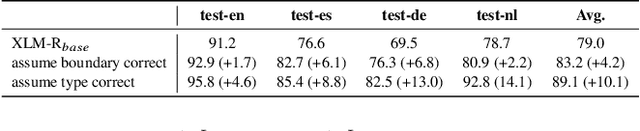
Lack of training data in low-resource languages presents huge challenges to sequence labeling tasks such as named entity recognition (NER) and machine reading comprehension (MRC). One major obstacle is the errors on the boundary of predicted answers. To tackle this problem, we propose CalibreNet, which predicts answers in two steps. In the first step, any existing sequence labeling method can be adopted as a base model to generate an initial answer. In the second step, CalibreNet refines the boundary of the initial answer. To tackle the challenge of lack of training data in low-resource languages, we dedicatedly develop a novel unsupervised phrase boundary recovery pre-training task to enhance the multilingual boundary detection capability of CalibreNet. Experiments on two cross-lingual benchmark datasets show that the proposed approach achieves SOTA results on zero-shot cross-lingual NER and MRC tasks.