 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-GAT: Graph Attention Network for Temporal Causality Discovery
Apr 21, 2023



The present study explores the intricacies of causal relationship extraction, a vital component in the pursuit of causality knowledge. Causality is frequently intertwined with temporal elements, as the progression from cause to effect is not instantaneous but rather ensconced in a temporal dimension. Thus, the extraction of temporal causality holds paramount significance in the field. In light of this, we propose a method for extracting causality from the text that integrates both temporal and causal relations, with a particular focus on the time aspect. To this end, we first compile a dataset that encompasses temporal relationships. Subsequently, we present a novel model, TC-GAT, which employs a graph attention mechanism to assign weights to the temporal relationships and leverages a causal knowledge graph to determine the adjacency matrix. Additionally, we implement an equilibrium mechanism to regulate the interplay between temporal and causal relations. Our experiments demonstrate that our proposed method significantly surpasses baseline models in the task of causality extraction.
Multi-level Contrastive Learning for Cross-lingual Spoken Language Understanding
May 07, 2022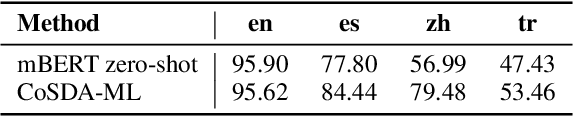

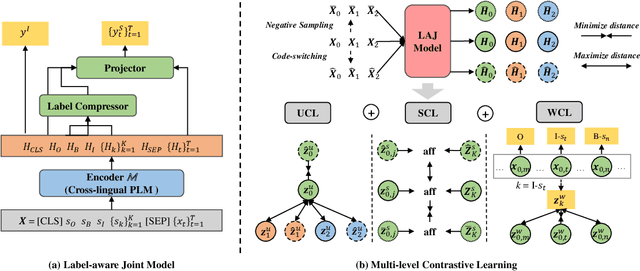
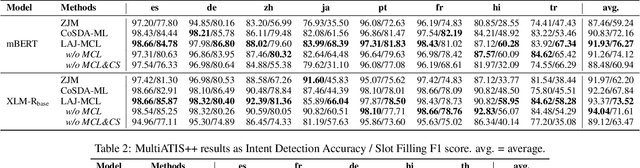
Although spoken language understanding (SLU) has achieved great success in high-resource languages, such as English, it remains challenging in low-resource languages mainly due to the lack of high quality training data. The recent multilingual code-switching approach samples some words in an input utterance and replaces them by expressions in some other languages of the same meaning. The multilingual code-switching approach achieves better alignments of representations across languages in zero-shot cross-lingual SLU. Surprisingly, all existing multilingual code-switching methods disregard the inherent semantic structure in SLU, i.e., most utterances contain one or more slots, and each slot consists of one or more words. In this paper, we propose to exploit the "utterance-slot-word" structure of SLU and systematically model this structure by a multi-level contrastive learning framework at the utterance, slot, and word levels. We develop novel code-switching schemes to generate hard negative examples for contrastive learning at all levels. Furthermore, we develop a label-aware joint model to leverage label semantics for cross-lingual knowledge transfer. Our experimental results show that our proposed methods significantly improve the performance compared with the strong baselines on two zero-shot cross-lingual SLU benchmark datasets.
Reinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Jun 01, 2021
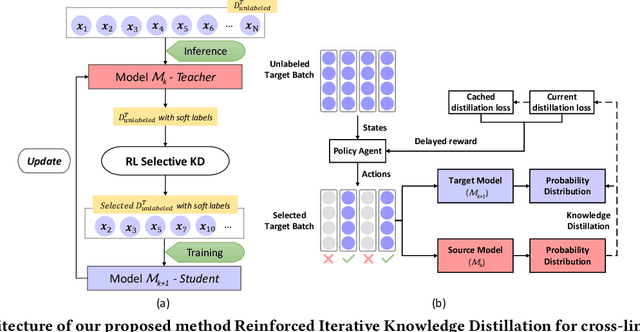

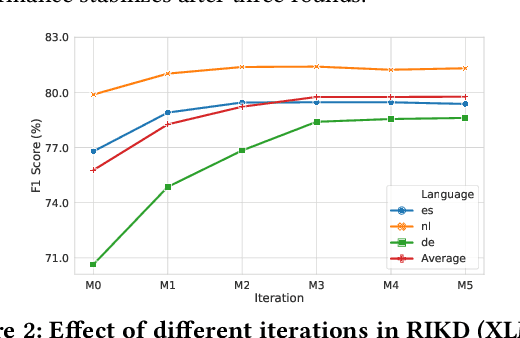
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.
CalibreNet: Calibration Networks for Multilingual Sequence Labeling
Nov 11, 2020

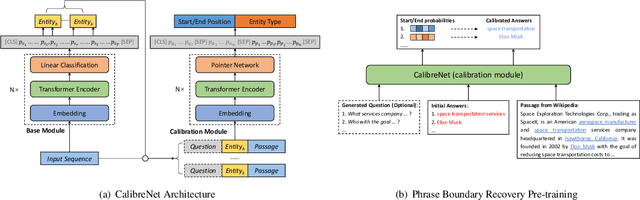
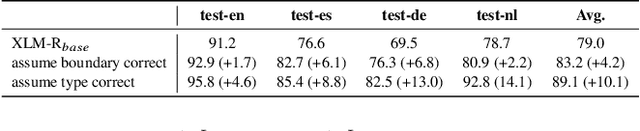
Lack of training data in low-resource languages presents huge challenges to sequence labeling tasks such as named entity recognition (NER) and machine reading comprehension (MRC). One major obstacle is the errors on the boundary of predicted answers. To tackle this problem, we propose CalibreNet, which predicts answers in two steps. In the first step, any existing sequence labeling method can be adopted as a base model to generate an initial answer. In the second step, CalibreNet refines the boundary of the initial answer. To tackle the challenge of lack of training data in low-resource languages, we dedicatedly develop a novel unsupervised phrase boundary recovery pre-training task to enhance the multilingual boundary detection capability of CalibreNet. Experiments on two cross-lingual benchmark datasets show that the proposed approach achieves SOTA results on zero-shot cross-lingual NER and MRC tasks.
A Block-based Generative Model for Attributed Networks Embedding
Jan 06, 2020

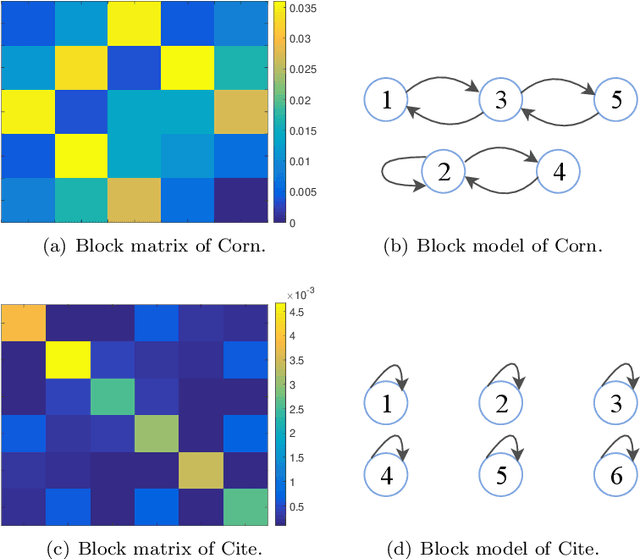
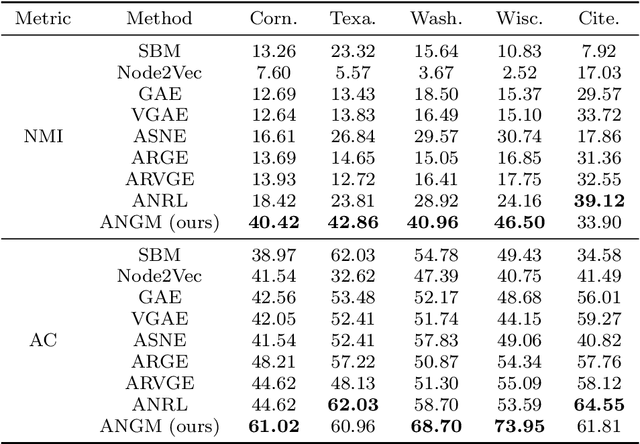
Attributed network embedding has attracted plenty of interests in recent years. It aims to learn task-independent, low-dimension, and continuous vectors for nodes preserving both topology and attribute information. Most existing methods, such as GCN and its variations, mainly focus on the local information, i.e., the attributes of the neighbors. Thus, they have been well studied for assortative networks but ignored disassortative networks, which are common in real scenes. To address this issue, we propose a block-based generative model for attributed network embedding on a probability perspective inspired by the stochastic block model (SBM). Specifically, the nodes are assigned to several blocks wherein the nodes in the same block share the similar link patterns. These patterns can define assortative networks containing communities or disassortative networks with the multipartite, hub, or any hybrid structures. Concerning the attribute information, we assume that each node has a hidden embedding related to its assigned block, and then we use a neural network to characterize the nonlinearity between the node embedding and its attribute. We perform extensive experiments on real-world and synthetic attributed networks, and the experimental results show that our proposed method remarkably outperforms state-of-the-art embedding methods for both clustering and classification tasks, especially on disassortative networks.
A Multi-level Neural Network for Implicit Causality Detection in Web Texts
Sep 08, 2019
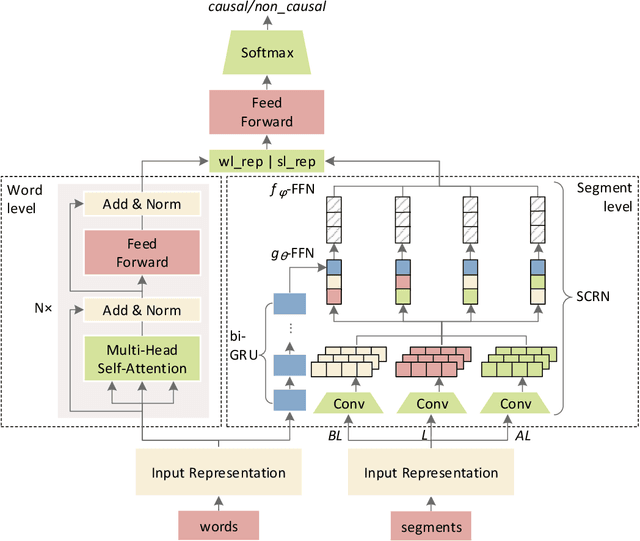

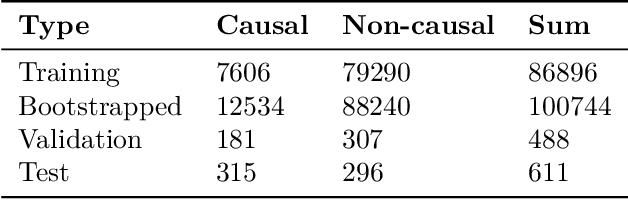
Mining causality from text is a complex and crucial natural language understanding task. Most of the early attempts at its solution can group into two categories: 1) utilizing co-occurrence frequency and world knowledge for causality detection; 2) extracting cause-effect pairs by using connectives and syntax patterns directly. However, because causality has various linguistic expressions, the noisy data and ignoring implicit expressions problems induced by these methods cannot be avoided. In this paper, we present a neural causality detection model, namely Multi-level Causality Detection Network (MCDN), to address this problem. Specifically, we adopt multi-head self-attention to acquire semantic feature at word level and integrate a novel Relation Network to infer causality at segment level. To the best of our knowledge, in touch with the causality tasks, this is the first time that the Relation Network is applied. The experimental results on the AltLex dataset, demonstrate that: a) MCDN is highly effective for the ambiguous and implicit causality inference; b) comparing with the regular text classification task, causality detection requires stronger inference capability; c) the proposed approach achieved state-of-the-art performance.
Low Cost Edge Sensing for High Quality Demosaicking
Jun 05, 2018
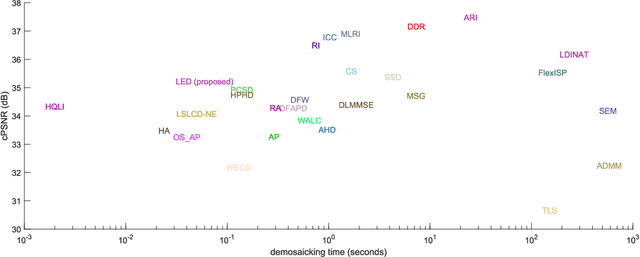
Digital cameras that use Color Filter Arrays (CFA) entail a demosaicking procedure to form full RGB images. As today's camera users generally require images to be viewed instantly, demosaicking algorithms for real applications must be fast. Moreover, the associated cost should be lower than the cost saved by using CFA. For this purpose, we revisit the classical Hamilton-Adams (HA) algorithm, which outperforms many sophisticated techniques in both speed and accuracy. Inspired by HA's strength and weakness, we design a very low cost edge sensing scheme. Briefly, it guides demosaicking by a logistic functional of the difference between directional variations. We extensively compare our algorithm with 28 demosaicking algorithms by running their open source codes on benchmark datasets. Compared to methods of similar computational cost, our method achieves substantially higher accuracy, Whereas compared to methods of similar accuracy, our method has significantly lower cost. Moreover, on test images of currently popular resolution, the quality of our algorithm is comparable to top performers, whereas its speed is tens of times faster.