 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Confounding Factors-Inhibition Adversarial Learning Framework for Multi-site fMRI Mental Disorder Identification
Apr 12, 2025In open data sets of functional magnetic resonance imaging (fMRI), the heterogeneity of the data is typically attributed to a combination of factors, including differences in scanning procedures, the presence of confounding effects, and population diversities between multiple sites. These factors contribute to the diminished effectiveness of representation learning, which in turn affects the overall efficacy of subsequent classification procedures. To address these limitations, we propose a novel multi-site adversarial learning network (MSalNET) for fMRI-based mental disorder detection. Firstly, a representation learning module is introduced with a node information assembly (NIA) mechanism to better extract features from functional connectivity (FC). This mechanism aggregates edge information from both horizontal and vertical directions, effectively assembling node information. Secondly, to generalize the feature across sites, we proposed a site-level feature extraction module that can learn from individual FC data, which circumvents additional prior information. Lastly, an adversarial learning network is proposed as a means of balancing the trade-off between individual classification and site regression tasks, with the introduction of a novel loss function. The proposed method was evaluated on two multi-site fMRI datasets, i.e., Autism Brain Imaging Data Exchange (ABIDE) and ADHD-200. The results indicate that the proposed method achieves a better performance than other related algorithms with the accuracy of 75.56 and 68.92 in ABIDE and ADHD-200 datasets, respectively. Furthermore, the result of the site regression indicates that the proposed method reduces site variability from a data-driven perspective. The most discriminative brain regions revealed by NIA are consistent with statistical findings, uncovering the "black box" of deep learning to a certain extent.
Toward Moiré-Free and Detail-Preserving Demosaicking
May 15, 2023
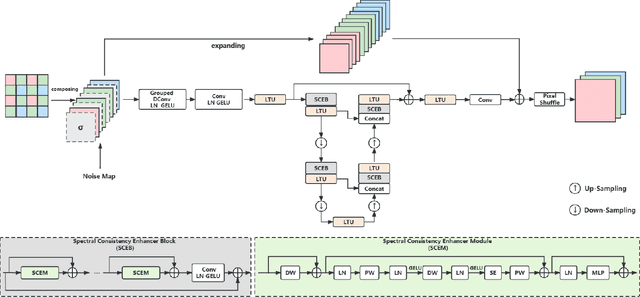


3D convolutions are commonly employed by demosaicking neural models, in the same way as solving other image restoration problems. Counter-intuitively, we show that 3D convolutions implicitly impede the RGB color spectra from exchanging complementary information, resulting in spectral-inconsistent inference of the local spatial high frequency components. As a consequence, shallow 3D convolution networks suffer the Moir\'e artifacts, but deep 3D convolutions cause over-smoothness. We analyze the fundamental difference between demosaicking and other problems that predict lost pixels between available ones (e.g., super-resolution reconstruction), and present the underlying reasons for the confliction between Moir\'e-free and detail-preserving. From the new perspective, our work decouples the common standard convolution procedure to spectral and spatial feature aggregations, which allow strengthening global communication in the spectral dimension while respecting local contrast in the spatial dimension. We apply our demosaicking model to two tasks: Joint Demosaicking-Denoising and Independently Demosaicking. In both applications, our model substantially alleviates artifacts such as Moir\'e and over-smoothness at similar or lower computational cost to currently top-performing models, as validated by diverse evaluations. Source code will be released along with paper publication.
Multi-Exposure HDR Composition by Gated Swin Transformer
Mar 15, 2023Fusing a sequence of perfectly aligned images captured at various exposures, has shown great potential to approach High Dynamic Range (HDR) imaging by sensors with limited dynamic range. However, in the presence of large motion of scene objects or the camera, mis-alignment is almost inevitable and leads to the notorious ``ghost'' artifacts. Besides, factors such as the noise in the dark region or color saturation in the over-bright region may also fail to fill local image details to the HDR image. This paper provides a novel multi-exposure fusion model based on Swin Transformer. Particularly, we design feature selection gates, which are integrated with the feature extraction layers to detect outliers and block them from HDR image synthesis. To reconstruct the missing local details by well-aligned and properly-exposed regions, we exploit the long distance contextual dependency in the exposure-space pyramid by the self-attention mechanism. Extensive numerical and visual evaluation has been conducted on a variety of benchmark datasets. The experiments show that our model achieves the accuracy on par with current top performing multi-exposure HDR imaging models, while gaining higher efficiency.
CGCV:Context Guided Correlation Volume for Optical Flow Neural Networks
Dec 20, 2022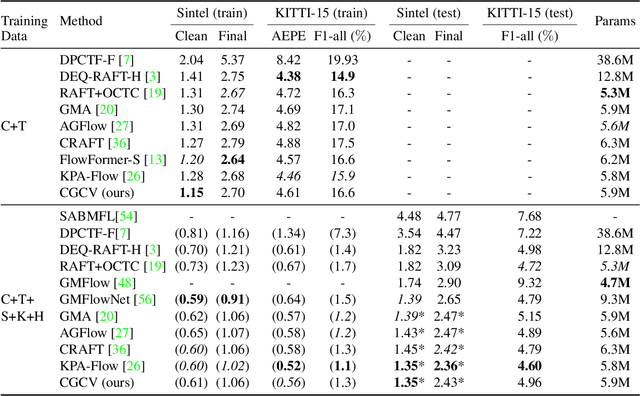

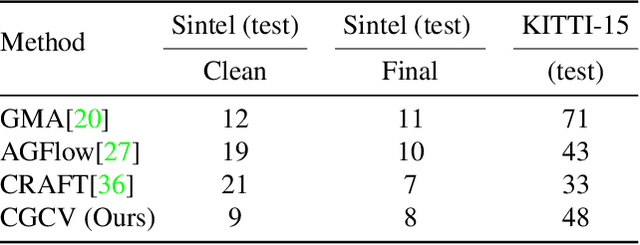

Optical flow, which computes the apparent motion from a pair of video frames, is a critical tool for scene motion estimation. Correlation volume is the central component of optical flow computational neural models. It estimates the pairwise matching costs between cross-frame features, and is then used to decode optical flow. However, traditional correlation volume is frequently noisy, outlier-prone, and sensitive to motion blur. We observe that, although the recent RAFT algorithm also adopts the traditional correlation volume, its additional context encoder provides semantically representative features to the flow decoder, implicitly compensating for the deficiency of the correlation volume. However, the benefits of this context encoder has been barely discussed or exploited. In this paper, we first investigate the functionality of RAFT's context encoder, then propose a new Context Guided Correlation Volume (CGCV) via gating and lifting schemes. CGCV can be universally integrated with RAFT-based flow computation methods for enhanced performance, especially effective in the presence of motion blur, de-focus blur and atmospheric effects. By incorporating the proposed CGCV with previous Global Motion Aggregation (GMA) method, at a minor cost of 0.5% extra parameters, the rank of GMA is lifted by 23 places on KITTI 2015 Leader Board, and 3 places on Sintel Leader Board. Moreover, at a similar model size, our correlation volume achieves competitive or superior performance to state of the art peer supervised models that employ Transformers or Graph Reasoning, as verified by extensive experiments.
Light Weight Color Image Warping with Inter-Channel Information
Dec 19, 2018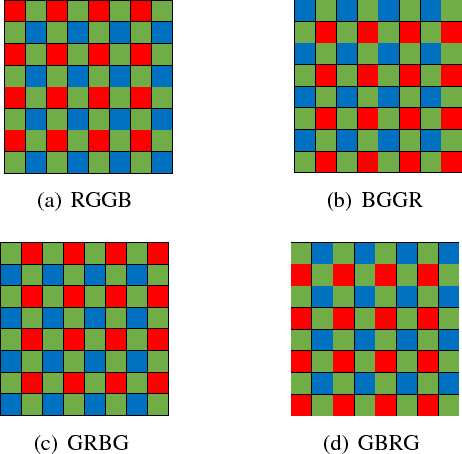
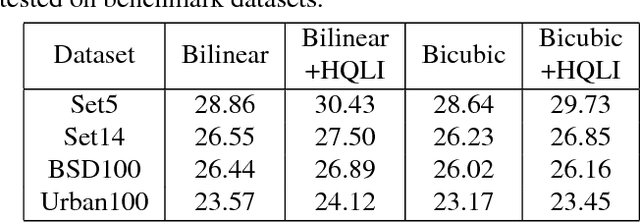
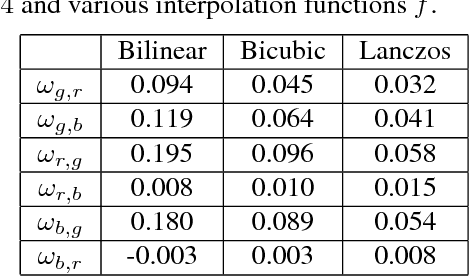
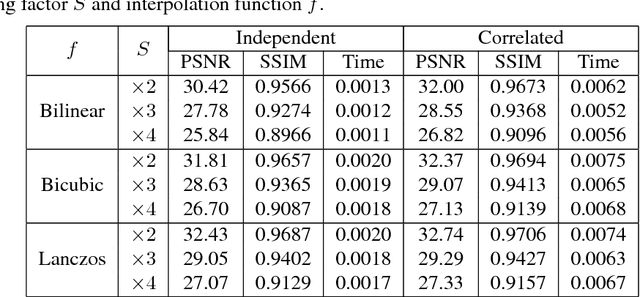
Image warping is a necessary step in many multimedia applications such as texture mapping, image-based rendering, panorama stitching, image resizing and optical flow computation etc. Traditionally, color image warping interpolation is performed in each color channel independently. In this paper, we show that the warping quality can be significantly enhanced by exploiting the cross-channel correlation. We design a warping scheme that integrates intra-channel interpolation with cross-channel variation at very low computational cost, which is required for interactive multimedia applications on mobile devices. The effectiveness and efficiency of our method are validated by extensive experiments.
Low Cost Edge Sensing for High Quality Demosaicking
Jun 05, 2018
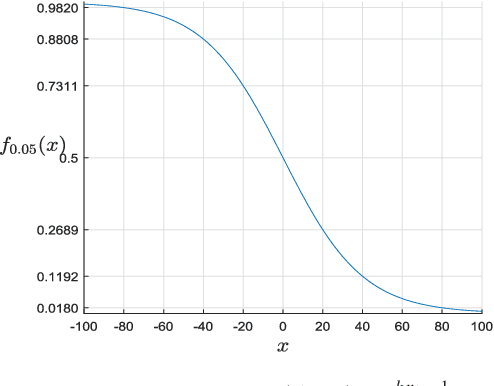
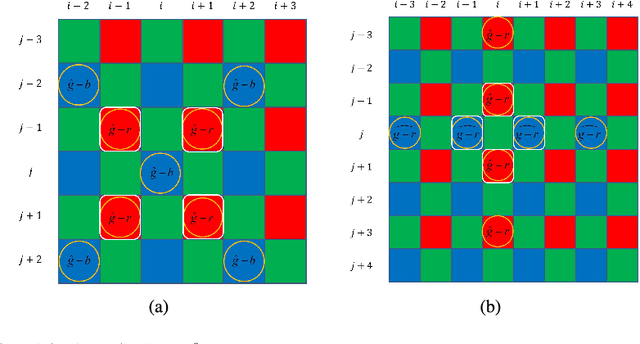
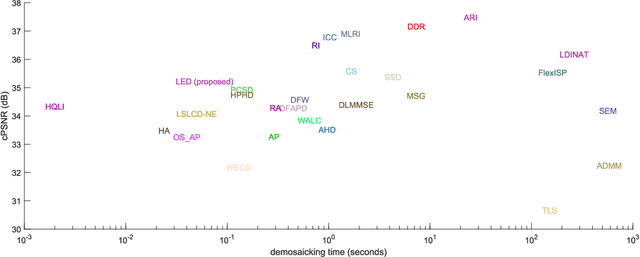
Digital cameras that use Color Filter Arrays (CFA) entail a demosaicking procedure to form full RGB images. As today's camera users generally require images to be viewed instantly, demosaicking algorithms for real applications must be fast. Moreover, the associated cost should be lower than the cost saved by using CFA. For this purpose, we revisit the classical Hamilton-Adams (HA) algorithm, which outperforms many sophisticated techniques in both speed and accuracy. Inspired by HA's strength and weakness, we design a very low cost edge sensing scheme. Briefly, it guides demosaicking by a logistic functional of the difference between directional variations. We extensively compare our algorithm with 28 demosaicking algorithms by running their open source codes on benchmark datasets. Compared to methods of similar computational cost, our method achieves substantially higher accuracy, Whereas compared to methods of similar accuracy, our method has significantly lower cost. Moreover, on test images of currently popular resolution, the quality of our algorithm is comparable to top performers, whereas its speed is tens of times faster.