 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Comorbidity-Informed Transfer Learning for Neuro-developmental Disorder Diagnosis
Apr 13, 2025



Neuro-developmental disorders are manifested as dysfunctions in cognition, communication, behaviour and adaptability, and deep learning-based computer-aided diagnosis (CAD) can alleviate the increasingly strained healthcare resources on neuroimaging. However, neuroimaging such as fMRI contains complex spatio-temporal features, which makes the corresponding representations susceptible to a variety of distractions, thus leading to less effective in CAD. For the first time, we present a Comorbidity-Informed Transfer Learning(CITL) framework for diagnosing neuro-developmental disorders using fMRI. In CITL, a new reinforced representation generation network is proposed, which first combines transfer learning with pseudo-labelling to remove interfering patterns from the temporal domain of fMRI and generates new representations using encoder-decoder architecture. The new representations are then trained in an architecturally simple classification network to obtain CAD model. In particular, the framework fully considers the comorbidity mechanisms of neuro-developmental disorders and effectively integrates them with semi-supervised learning and transfer learning, providing new perspectives on interdisciplinary. Experimental results demonstrate that CITL achieves competitive accuracies of 76.32% and 73.15% for detecting autism spectrum disorder and attention deficit hyperactivity disorder, respectively, which outperforms existing related transfer learning work for 7.2% and 0.5% respectively.
A Confounding Factors-Inhibition Adversarial Learning Framework for Multi-site fMRI Mental Disorder Identification
Apr 12, 2025In open data sets of functional magnetic resonance imaging (fMRI), the heterogeneity of the data is typically attributed to a combination of factors, including differences in scanning procedures, the presence of confounding effects, and population diversities between multiple sites. These factors contribute to the diminished effectiveness of representation learning, which in turn affects the overall efficacy of subsequent classification procedures. To address these limitations, we propose a novel multi-site adversarial learning network (MSalNET) for fMRI-based mental disorder detection. Firstly, a representation learning module is introduced with a node information assembly (NIA) mechanism to better extract features from functional connectivity (FC). This mechanism aggregates edge information from both horizontal and vertical directions, effectively assembling node information. Secondly, to generalize the feature across sites, we proposed a site-level feature extraction module that can learn from individual FC data, which circumvents additional prior information. Lastly, an adversarial learning network is proposed as a means of balancing the trade-off between individual classification and site regression tasks, with the introduction of a novel loss function. The proposed method was evaluated on two multi-site fMRI datasets, i.e., Autism Brain Imaging Data Exchange (ABIDE) and ADHD-200. The results indicate that the proposed method achieves a better performance than other related algorithms with the accuracy of 75.56 and 68.92 in ABIDE and ADHD-200 datasets, respectively. Furthermore, the result of the site regression indicates that the proposed method reduces site variability from a data-driven perspective. The most discriminative brain regions revealed by NIA are consistent with statistical findings, uncovering the "black box" of deep learning to a certain extent.
A Novel Perception Entropy Metric for Optimizing Vehicle Perception with LiDAR Deployment
Jul 25, 2024



Developing an effective evaluation metric is crucial for accurately and swiftly measuring LiDAR perception performance. One major issue is the lack of metrics that can simultaneously generate fast and accurate evaluations based on either object detection or point cloud data. In this study, we propose a novel LiDAR perception entropy metric based on the probability of vehicle grid occupancy. This metric reflects the influence of point cloud distribution on vehicle detection performance. Based on this, we also introduce a LiDAR deployment optimization model, which is solved using a differential evolution-based particle swarm optimization algorithm. A comparative experiment demonstrated that the proposed PE-VGOP offers a correlation of more than 0.98 with vehicle detection ground truth in evaluating LiDAR perception performance. Furthermore, compared to the base deployment, field experiments indicate that the proposed optimization model can significantly enhance the perception capabilities of various types of LiDARs, including RS-16, RS-32, and RS-80. Notably, it achieves a 25% increase in detection Recall for the RS-32 LiDAR.
The Application of ChatGPT in Responding to Questions Related to the Boston Bowel Preparation Scale
Feb 13, 2024



Background: Colonoscopy, a crucial diagnostic tool in gastroenterology, depends heavily on superior bowel preparation. ChatGPT, a large language model with emergent intelligence which also exhibits potential in medical applications. This study aims to assess the accuracy and consistency of ChatGPT in using the Boston Bowel Preparation Scale (BBPS) for colonoscopy assessment. Methods: We retrospectively collected 233 colonoscopy images from 2020 to 2023. These images were evaluated using the BBPS by 3 senior endoscopists and 3 novice endoscopists. Additionally, ChatGPT also assessed these images, having been divided into three groups and undergone specific Fine-tuning. Consistency was evaluated through two rounds of testing. Results: In the initial round, ChatGPT's accuracy varied between 48.93% and 62.66%, trailing the endoscopists' accuracy of 76.68% to 77.83%. Kappa values for ChatGPT was between 0.52 and 0.53, compared to 0.75 to 0.87 for the endoscopists. Conclusion: While ChatGPT shows promise in bowel preparation scoring, it currently does not match the accuracy and consistency of experienced endoscopists. Future research should focus on in-depth Fine-tuning.
Autoencoding a Soft Touch to Learn Grasping from On-land to Underwater
Aug 16, 2023Robots play a critical role as the physical agent of human operators in exploring the ocean. However, it remains challenging to grasp objects reliably while fully submerging under a highly pressurized aquatic environment with little visible light, mainly due to the fluidic interference on the tactile mechanics between the finger and object surfaces. This study investigates the transferability of grasping knowledge from on-land to underwater via a vision-based soft robotic finger that learns 6D forces and torques (FT) using a Supervised Variational Autoencoder (SVAE). A high-framerate camera captures the whole-body deformations while a soft robotic finger interacts with physical objects on-land and underwater. Results show that the trained SVAE model learned a series of latent representations of the soft mechanics transferrable from land to water, presenting a superior adaptation to the changing environments against commercial FT sensors. Soft, delicate, and reactive grasping enabled by tactile intelligence enhances the gripper's underwater interaction with improved reliability and robustness at a much-reduced cost, paving the path for learning-based intelligent grasping to support fundamental scientific discoveries in environmental and ocean research.
Proprioceptive Learning with Soft Polyhedral Networks
Aug 16, 2023



Proprioception is the "sixth sense" that detects limb postures with motor neurons. It requires a natural integration between the musculoskeletal systems and sensory receptors, which is challenging among modern robots that aim for lightweight, adaptive, and sensitive designs at a low cost. Here, we present the Soft Polyhedral Network with an embedded vision for physical interactions, capable of adaptive kinesthesia and viscoelastic proprioception by learning kinetic features. This design enables passive adaptations to omni-directional interactions, visually captured by a miniature high-speed motion tracking system embedded inside for proprioceptive learning. The results show that the soft network can infer real-time 6D forces and torques with accuracies of 0.25/0.24/0.35 N and 0.025/0.034/0.006 Nm in dynamic interactions. We also incorporate viscoelasticity in proprioception during static adaptation by adding a creep and relaxation modifier to refine the predicted results. The proposed soft network combines simplicity in design, omni-adaptation, and proprioceptive sensing with high accuracy, making it a versatile solution for robotics at a low cost with more than 1 million use cycles for tasks such as sensitive and competitive grasping, and touch-based geometry reconstruction. This study offers new insights into vision-based proprioception for soft robots in adaptive grasping, soft manipulation, and human-robot interaction.
An enhanced motion planning approach by integrating driving heterogeneity and long-term trajectory prediction for automated driving systems
Aug 02, 2023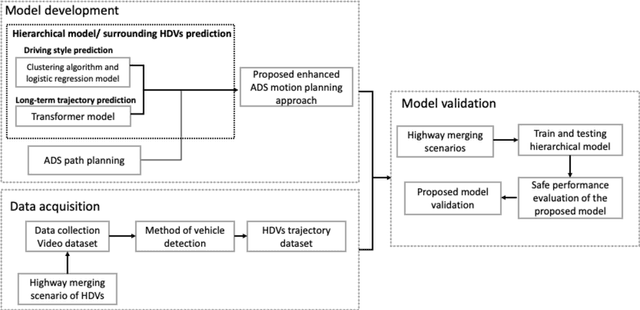
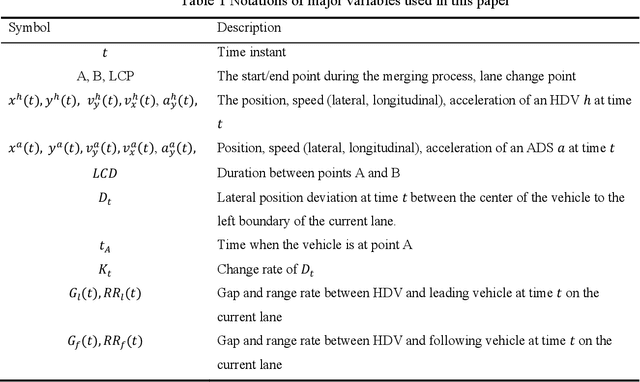
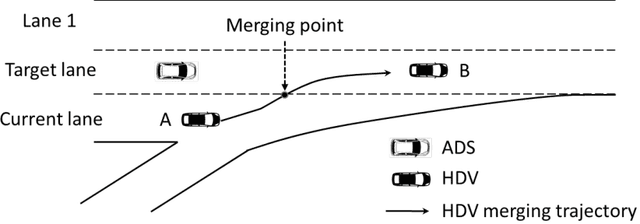

Navigating automated driving systems (ADSs) through complex driving environments is difficult. Predicting the driving behavior of surrounding human-driven vehicles (HDVs) is a critical component of an ADS. This paper proposes an enhanced motion-planning approach for an ADS in a highway-merging scenario. The proposed enhanced approach utilizes the results of two aspects: the driving behavior and long-term trajectory of surrounding HDVs, which are coupled using a hierarchical model that is used for the motion planning of an ADS to improve driving safety.
Jigsaw-based Benchmarking for Learning Robotic Manipulation
Jun 08, 2023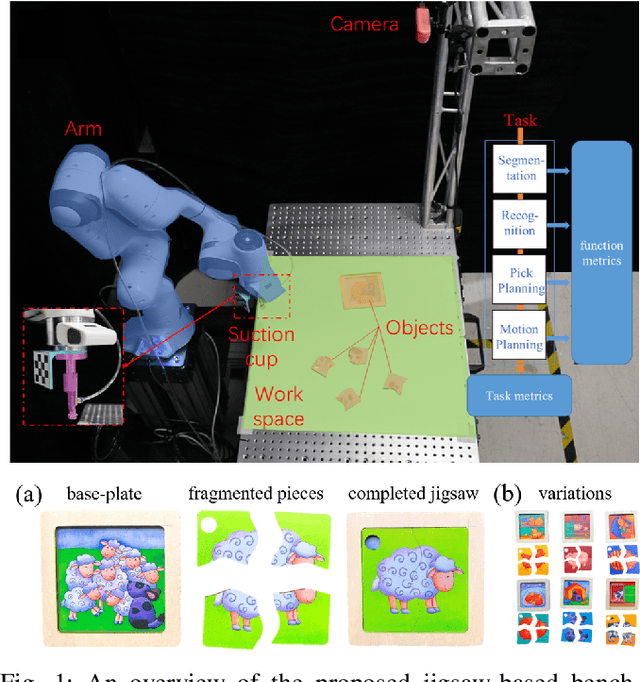
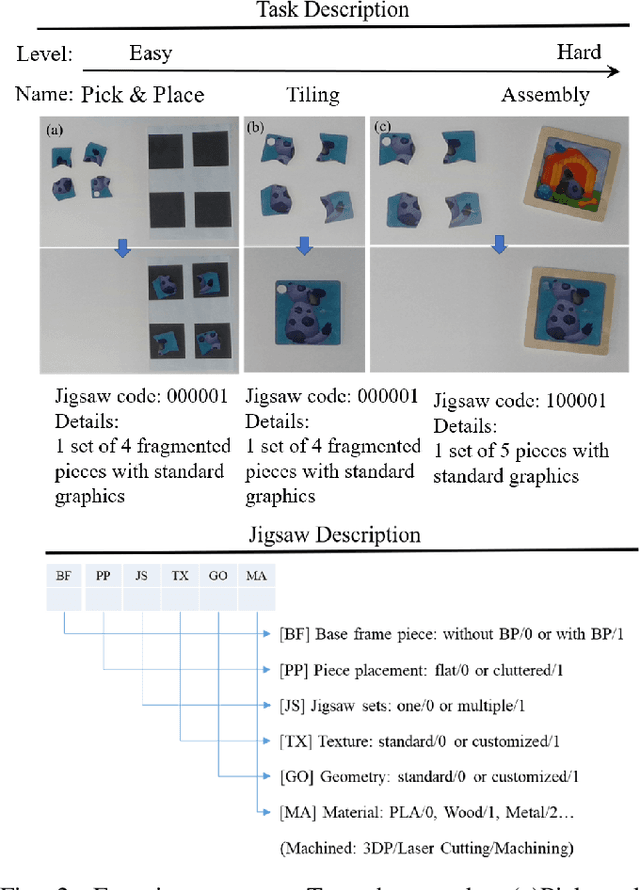
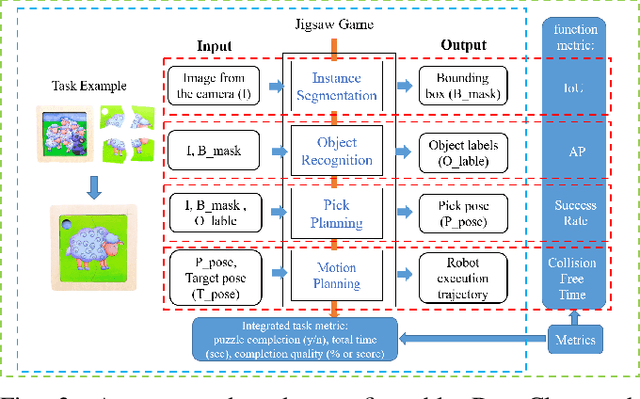
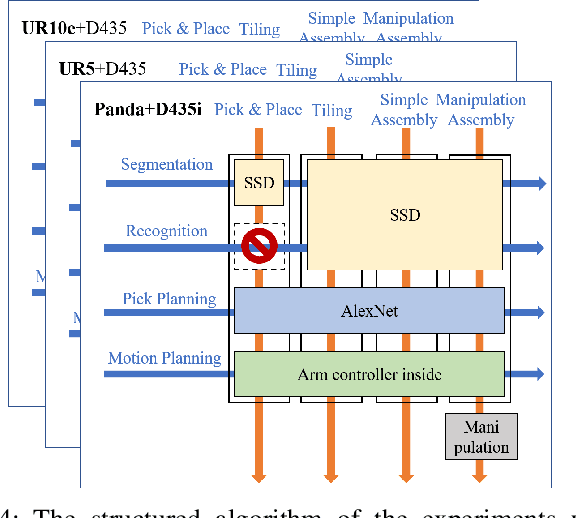
Benchmarking provides experimental evidence of the scientific baseline to enhance the progression of fundamental research, which is also applicable to robotics. In this paper, we propose a method to benchmark metrics of robotic manipulation, which addresses the spatial-temporal reasoning skills for robot learning with the jigsaw game. In particular, our approach exploits a simple set of jigsaw pieces by designing a structured protocol, which can be highly customizable according to a wide range of task specifications. Researchers can selectively adopt the proposed protocol to benchmark their research outputs, on a comparable scale in the functional, task, and system-level of details. The purpose is to provide a potential look-up table for learning-based robot manipulation, commonly available in other engineering disciplines, to facilitate the adoption of robotics through calculated, empirical, and systematic experimental evidence.
Traffic Analytics Development Kits (TADK): Enable Real-Time AI Inference in Networking Apps
Aug 16, 2022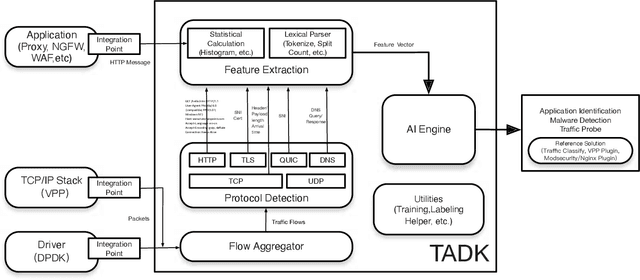
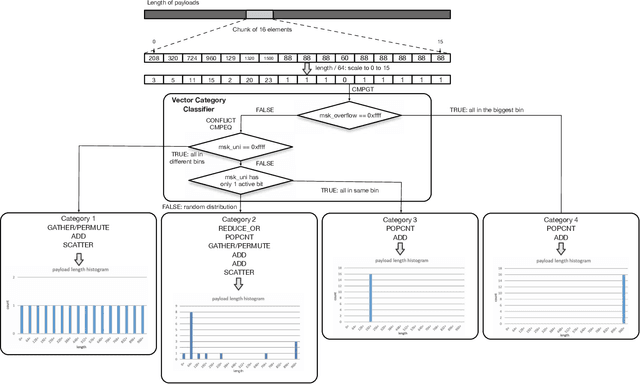
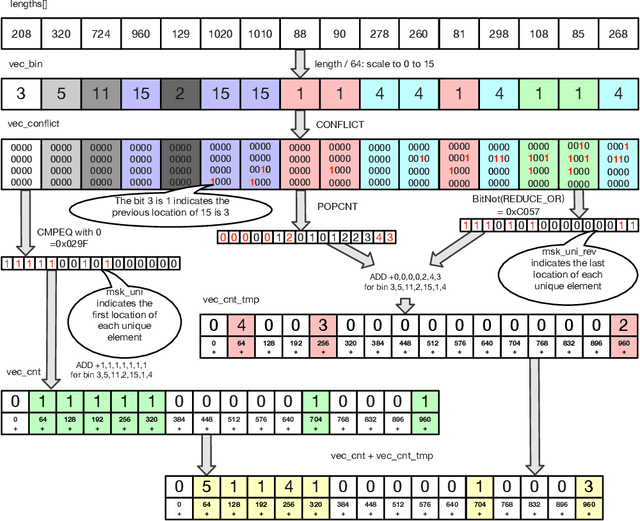
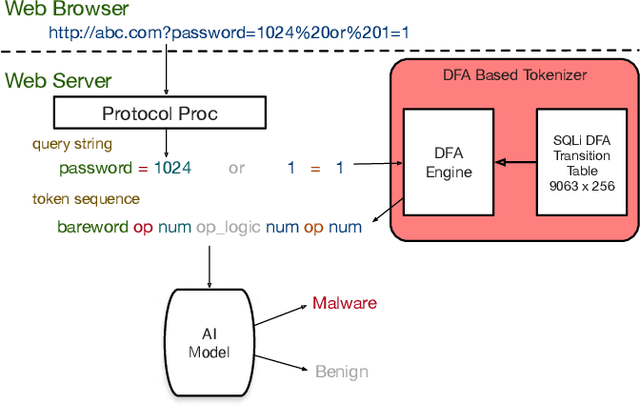
Sophisticated traffic analytics, such as the encrypted traffic analytics and unknown malware detection, emphasizes the need for advanced methods to analyze the network traffic. Traditional methods of using fixed patterns, signature matching, and rules to detect known patterns in network traffic are being replaced with AI (Artificial Intelligence) driven algorithms. However, the absence of a high-performance AI networking-specific framework makes deploying real-time AI-based processing within networking workloads impossible. In this paper, we describe the design of Traffic Analytics Development Kits (TADK), an industry-standard framework specific for AI-based networking workloads processing. TADK can provide real-time AI-based networking workload processing in networking equipment from the data center out to the edge without the need for specialized hardware (e.g., GPUs, Neural Processing Unit, and so on). We have deployed TADK in commodity WAF and 5G UPF, and the evaluation result shows that TADK can achieve a throughput up to 35.3Gbps per core on traffic feature extraction, 6.5Gbps per core on traffic classification, and can decrease SQLi/XSS detection down to 4.5us per request with higher accuracy than fixed pattern solution.