 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive ICP LiDAR Odometry Based on Reliable Initial Pose
Sep 26, 2025As a key technology for autonomous navigation and positioning in mobile robots, light detection and ranging (LiDAR) odometry is widely used in autonomous driving applications. The Iterative Closest Point (ICP)-based methods have become the core technique in LiDAR odometry due to their efficient and accurate point cloud registration capability. However, some existing ICP-based methods do not consider the reliability of the initial pose, which may cause the method to converge to a local optimum. Furthermore, the absence of an adaptive mechanism hinders the effective handling of complex dynamic environments, resulting in a significant degradation of registration accuracy. To address these issues, this paper proposes an adaptive ICP-based LiDAR odometry method that relies on a reliable initial pose. First, distributed coarse registration based on density filtering is employed to obtain the initial pose estimation. The reliable initial pose is then selected by comparing it with the motion prediction pose, reducing the initial error between the source and target point clouds. Subsequently, by combining the current and historical errors, the adaptive threshold is dynamically adjusted to accommodate the real-time changes in the dynamic environment. Finally, based on the reliable initial pose and the adaptive threshold, point-to-plane adaptive ICP registration is performed from the current frame to the local map, achieving high-precision alignment of the source and target point clouds. Extensive experiments on the public KITTI dataset demonstrate that the proposed method outperforms existing approaches and significantly enhances the accuracy of LiDAR odometry.
Joint graph entropy knowledge distillation for point cloud classification and robustness against corruptions
Sep 26, 2025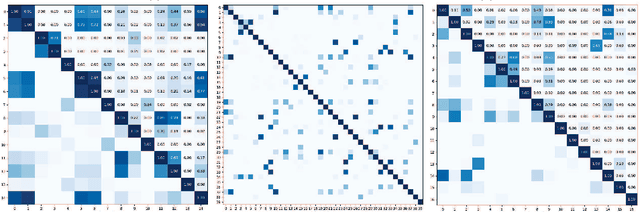



Classification tasks in 3D point clouds often assume that class events \replaced{are }{follow }independent and identically distributed (IID), although this assumption destroys the correlation between classes. This \replaced{study }{paper }proposes a classification strategy, \textbf{J}oint \textbf{G}raph \textbf{E}ntropy \textbf{K}nowledge \textbf{D}istillation (JGEKD), suitable for non-independent and identically distributed 3D point cloud data, \replaced{which }{the strategy } achieves knowledge transfer of class correlations through knowledge distillation by constructing a loss function based on joint graph entropy. First\deleted{ly}, we employ joint graphs to capture add{the }hidden relationships between classes\replaced{ and}{,} implement knowledge distillation to train our model by calculating the entropy of add{add }graph.\replaced{ Subsequently}{ Then}, to handle 3D point clouds \deleted{that is }invariant to spatial transformations, we construct \replaced{S}{s}iamese structures and develop two frameworks, self-knowledge distillation and teacher-knowledge distillation, to facilitate information transfer between different transformation forms of the same data. \replaced{In addition}{ Additionally}, we use the above framework to achieve knowledge transfer between point clouds and their corrupted forms, and increase the robustness against corruption of model. Extensive experiments on ScanObject, ModelNet40, ScanntV2\_cls and ModelNet-C demonstrate that the proposed strategy can achieve competitive results.
Traffic Analytics Development Kits (TADK): Enable Real-Time AI Inference in Networking Apps
Aug 16, 2022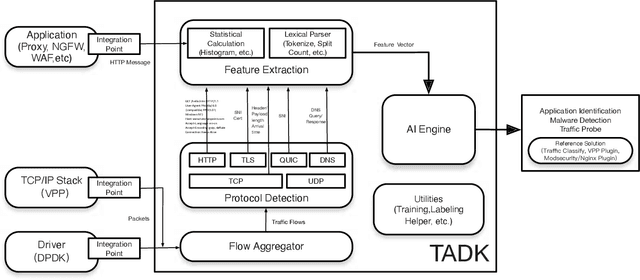
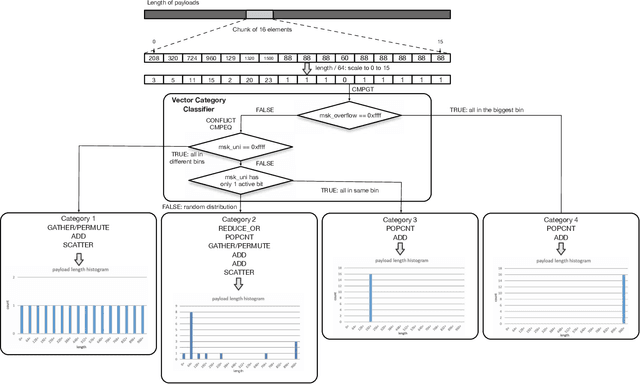
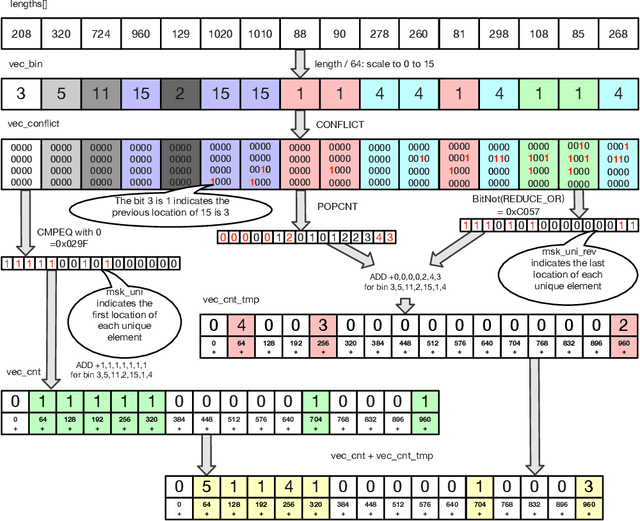
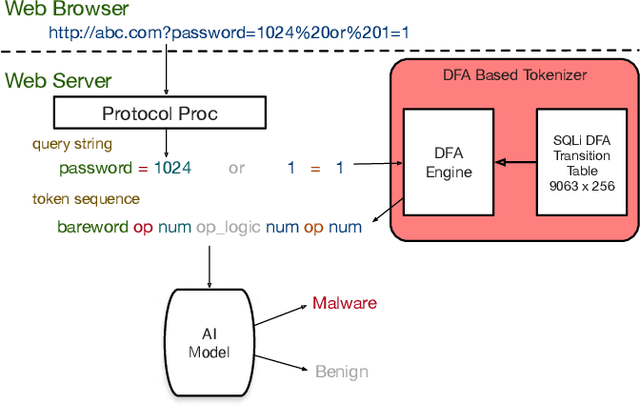
Sophisticated traffic analytics, such as the encrypted traffic analytics and unknown malware detection, emphasizes the need for advanced methods to analyze the network traffic. Traditional methods of using fixed patterns, signature matching, and rules to detect known patterns in network traffic are being replaced with AI (Artificial Intelligence) driven algorithms. However, the absence of a high-performance AI networking-specific framework makes deploying real-time AI-based processing within networking workloads impossible. In this paper, we describe the design of Traffic Analytics Development Kits (TADK), an industry-standard framework specific for AI-based networking workloads processing. TADK can provide real-time AI-based networking workload processing in networking equipment from the data center out to the edge without the need for specialized hardware (e.g., GPUs, Neural Processing Unit, and so on). We have deployed TADK in commodity WAF and 5G UPF, and the evaluation result shows that TADK can achieve a throughput up to 35.3Gbps per core on traffic feature extraction, 6.5Gbps per core on traffic classification, and can decrease SQLi/XSS detection down to 4.5us per request with higher accuracy than fixed pattern solution.
Multi-Task Hierarchical Learning Based Network Traffic Analytics
Jun 05, 2021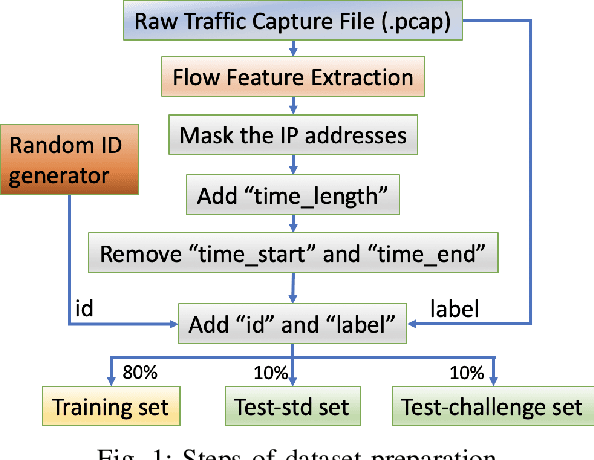
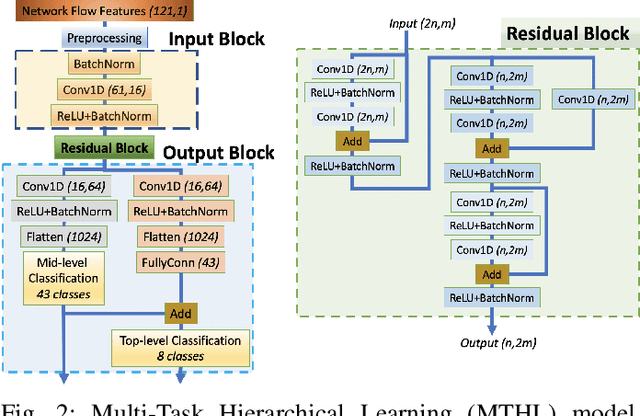
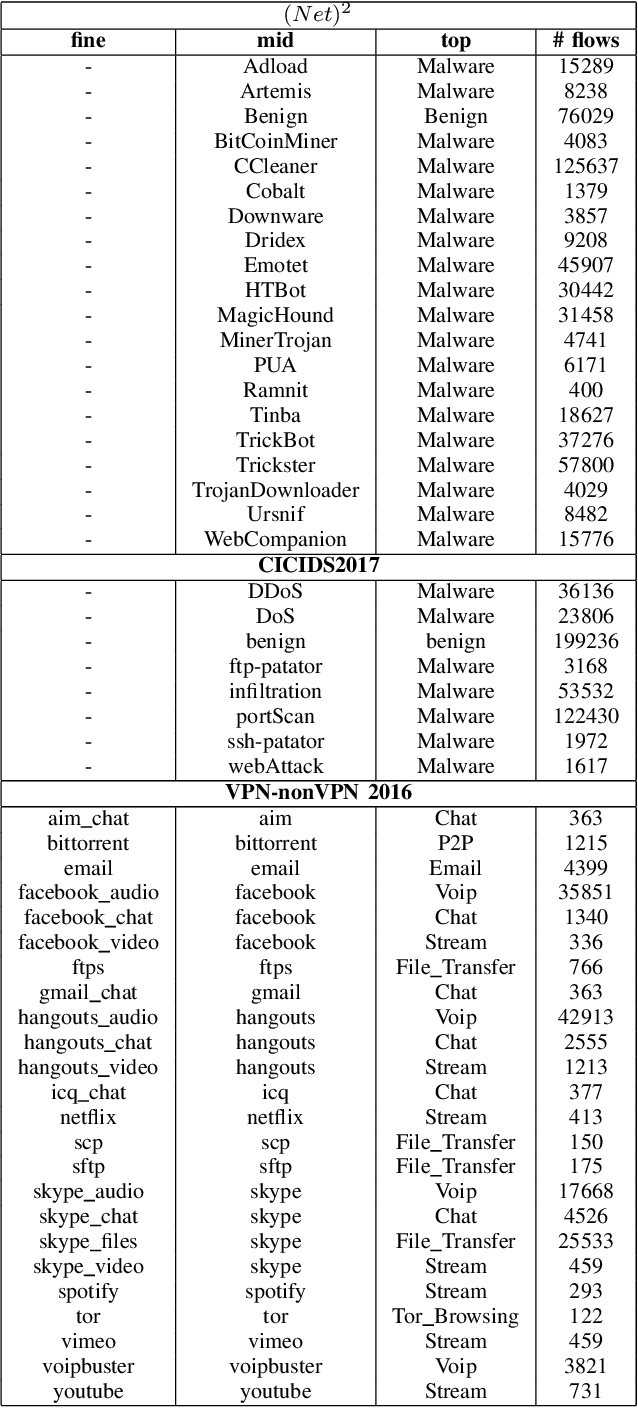

Classifying network traffic is the basis for important network applications. Prior research in this area has faced challenges on the availability of representative datasets, and many of the results cannot be readily reproduced. Such a problem is exacerbated by emerging data-driven machine learning based approaches. To address this issue, we present(N et)2databasewith three open datasets containing nearly 1.3M labeled flows in total, with a comprehensive list of flow features, for there search community1. We focus on broad aspects in network traffic analysis, including both malware detection and application classification. As we continue to grow them, we expect the datasets to serve as a common ground for AI driven, reproducible research on network flow analytics. We release the datasets publicly and also introduce a Multi-Task Hierarchical Learning (MTHL)model to perform all tasks in a single model. Our results show that MTHL is capable of accurately performing multiple tasks with hierarchical labeling with a dramatic reduction in training time.
NetML: A Challenge for Network Traffic Analytics
Apr 25, 2020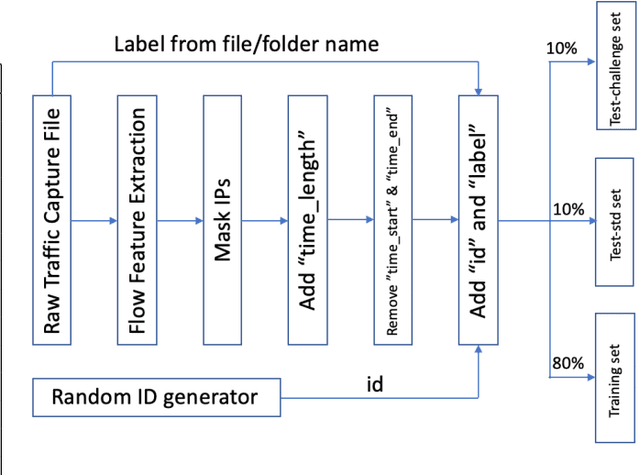
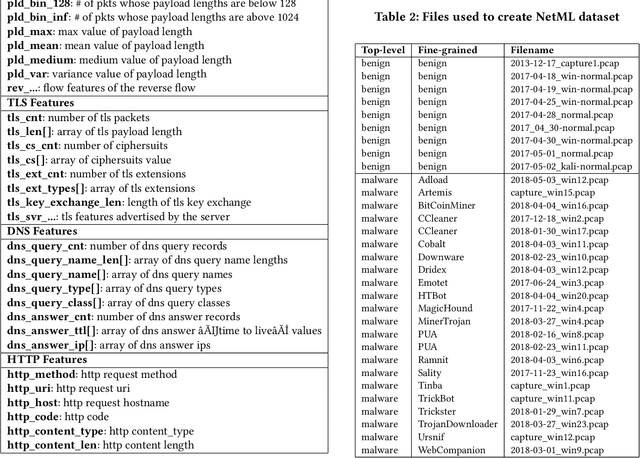
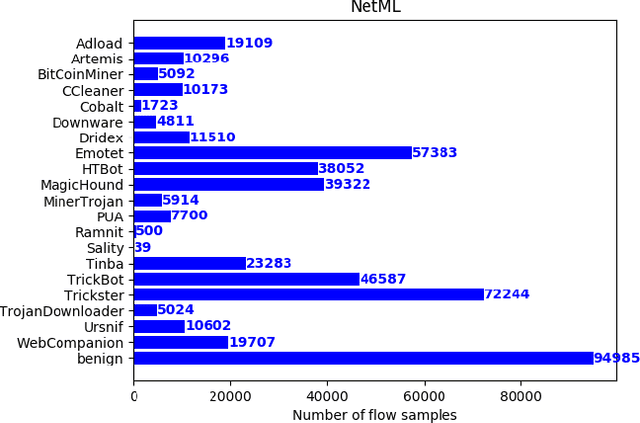
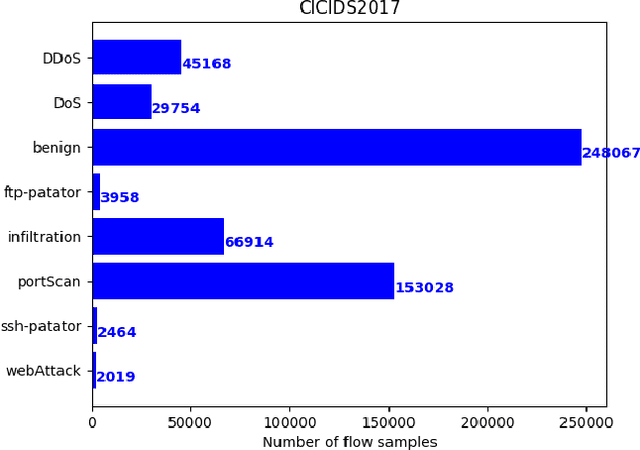
Classifying network traffic is the basis for important network applications. Prior research in this area has faced challenges on the availability of representative datasets, and many of the results cannot be readily reproduced. Such a problem is exacerbated by emerging data-driven machine learning based approaches. To address this issue, we provide three open datasets containing almost 1.3M labeled flows in total, with flow features and anonymized raw packets, for the research community. We focus on broad aspects in network traffic analysis, including both malware detection and application classification. We release the datasets in the form of an open challenge called NetML and implement several machine learning methods including random-forest, SVM and MLP. As we continue to grow NetML, we expect the datasets to serve as a common platform for AI driven, reproducible research on network flow analytics.