 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
Comorbidity-Informed Transfer Learning for Neuro-developmental Disorder Diagnosis
Apr 13, 2025



Neuro-developmental disorders are manifested as dysfunctions in cognition, communication, behaviour and adaptability, and deep learning-based computer-aided diagnosis (CAD) can alleviate the increasingly strained healthcare resources on neuroimaging. However, neuroimaging such as fMRI contains complex spatio-temporal features, which makes the corresponding representations susceptible to a variety of distractions, thus leading to less effective in CAD. For the first time, we present a Comorbidity-Informed Transfer Learning(CITL) framework for diagnosing neuro-developmental disorders using fMRI. In CITL, a new reinforced representation generation network is proposed, which first combines transfer learning with pseudo-labelling to remove interfering patterns from the temporal domain of fMRI and generates new representations using encoder-decoder architecture. The new representations are then trained in an architecturally simple classification network to obtain CAD model. In particular, the framework fully considers the comorbidity mechanisms of neuro-developmental disorders and effectively integrates them with semi-supervised learning and transfer learning, providing new perspectives on interdisciplinary. Experimental results demonstrate that CITL achieves competitive accuracies of 76.32% and 73.15% for detecting autism spectrum disorder and attention deficit hyperactivity disorder, respectively, which outperforms existing related transfer learning work for 7.2% and 0.5% respectively.
A Confounding Factors-Inhibition Adversarial Learning Framework for Multi-site fMRI Mental Disorder Identification
Apr 12, 2025In open data sets of functional magnetic resonance imaging (fMRI), the heterogeneity of the data is typically attributed to a combination of factors, including differences in scanning procedures, the presence of confounding effects, and population diversities between multiple sites. These factors contribute to the diminished effectiveness of representation learning, which in turn affects the overall efficacy of subsequent classification procedures. To address these limitations, we propose a novel multi-site adversarial learning network (MSalNET) for fMRI-based mental disorder detection. Firstly, a representation learning module is introduced with a node information assembly (NIA) mechanism to better extract features from functional connectivity (FC). This mechanism aggregates edge information from both horizontal and vertical directions, effectively assembling node information. Secondly, to generalize the feature across sites, we proposed a site-level feature extraction module that can learn from individual FC data, which circumvents additional prior information. Lastly, an adversarial learning network is proposed as a means of balancing the trade-off between individual classification and site regression tasks, with the introduction of a novel loss function. The proposed method was evaluated on two multi-site fMRI datasets, i.e., Autism Brain Imaging Data Exchange (ABIDE) and ADHD-200. The results indicate that the proposed method achieves a better performance than other related algorithms with the accuracy of 75.56 and 68.92 in ABIDE and ADHD-200 datasets, respectively. Furthermore, the result of the site regression indicates that the proposed method reduces site variability from a data-driven perspective. The most discriminative brain regions revealed by NIA are consistent with statistical findings, uncovering the "black box" of deep learning to a certain extent.
DiVE: DiT-based Video Generation with Enhanced Control
Sep 03, 2024



Generating high-fidelity, temporally consistent videos in autonomous driving scenarios faces a significant challenge, e.g. problematic maneuvers in corner cases. Despite recent video generation works are proposed to tackcle the mentioned problem, i.e. models built on top of Diffusion Transformers (DiT), works are still missing which are targeted on exploring the potential for multi-view videos generation scenarios. Noticeably, we propose the first DiT-based framework specifically designed for generating temporally and multi-view consistent videos which precisely match the given bird's-eye view layouts control. Specifically, the proposed framework leverages a parameter-free spatial view-inflated attention mechanism to guarantee the cross-view consistency, where joint cross-attention modules and ControlNet-Transformer are integrated to further improve the precision of control. To demonstrate our advantages, we extensively investigate the qualitative comparisons on nuScenes dataset, particularly in some most challenging corner cases. In summary, the effectiveness of our proposed method in producing long, controllable, and highly consistent videos under difficult conditions is proven to be effective.
Exploring the Mutual Influence between Self-Supervised Single-Frame and Multi-Frame Depth Estimation
Apr 25, 2023



Although both self-supervised single-frame and multi-frame depth estimation methods only require unlabeled monocular videos for training, the information they leverage varies because single-frame methods mainly rely on appearance-based features while multi-frame methods focus on geometric cues. Considering the complementary information of single-frame and multi-frame methods, some works attempt to leverage single-frame depth to improve multi-frame depth. However, these methods can neither exploit the difference between single-frame depth and multi-frame depth to improve multi-frame depth nor leverage multi-frame depth to optimize single-frame depth models. To fully utilize the mutual influence between single-frame and multi-frame methods, we propose a novel self-supervised training framework. Specifically, we first introduce a pixel-wise adaptive depth sampling module guided by single-frame depth to train the multi-frame model. Then, we leverage the minimum reprojection based distillation loss to transfer the knowledge from the multi-frame depth network to the single-frame network to improve single-frame depth. Finally, we regard the improved single-frame depth as a prior to further boost the performance of multi-frame depth estimation. Experimental results on the KITTI and Cityscapes datasets show that our method outperforms existing approaches in the self-supervised monocular setting.
Visual Attention-based Self-supervised Absolute Depth Estimation using Geometric Priors in Autonomous Driving
May 18, 2022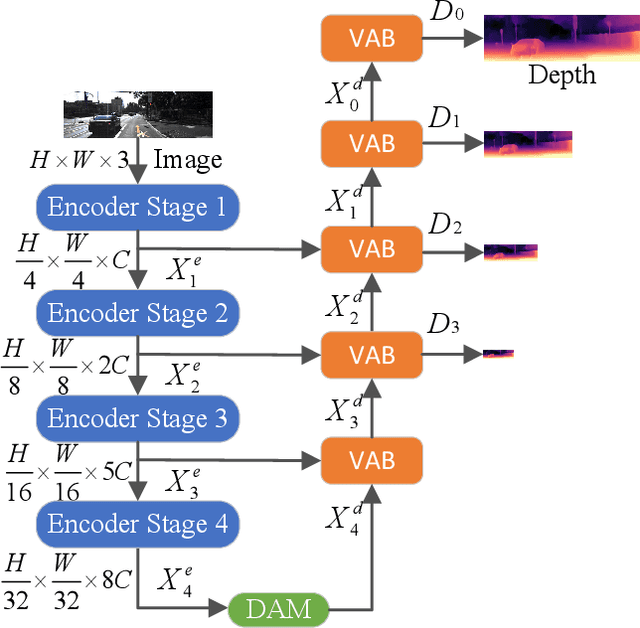
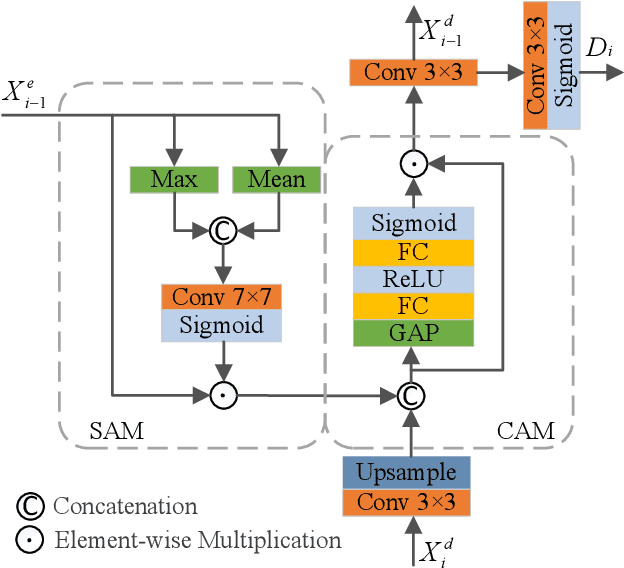

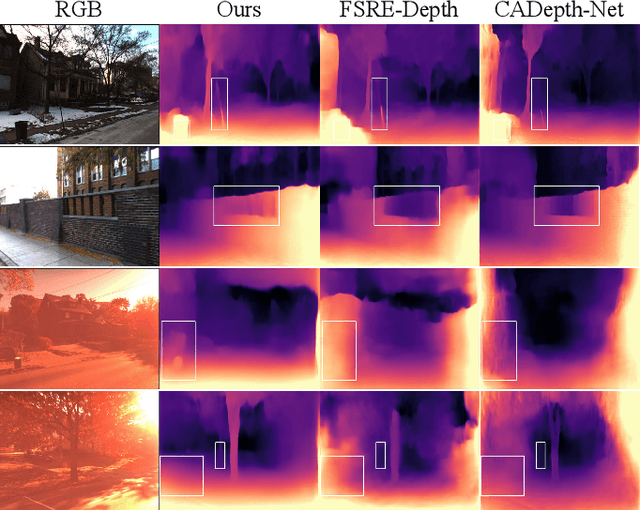
Although existing monocular depth estimation methods have made great progress, predicting an accurate absolute depth map from a single image is still challenging due to the limited modeling capacity of networks and the scale ambiguity issue. In this paper, we introduce a fully Visual Attention-based Depth (VADepth) network, where spatial attention and channel attention are applied to all stages. By continuously extracting the dependencies of features along the spatial and channel dimensions over a long distance, VADepth network can effectively preserve important details and suppress interfering features to better perceive the scene structure for more accurate depth estimates. In addition, we utilize geometric priors to form scale constraints for scale-aware model training. Specifically, we construct a novel scale-aware loss using the distance between the camera and a plane fitted by the ground points corresponding to the pixels of the rectangular area in the bottom middle of the image. Experimental results on the KITTI dataset show that this architecture achieves the state-of-the-art performance and our method can directly output absolute depth without post-processing. Moreover, our experiments on the SeasonDepth dataset also demonstrate the robustness of our model to multiple unseen environments.
Machine Learning based Pallets Detection and Tracking in AGVs
Apr 19, 2020
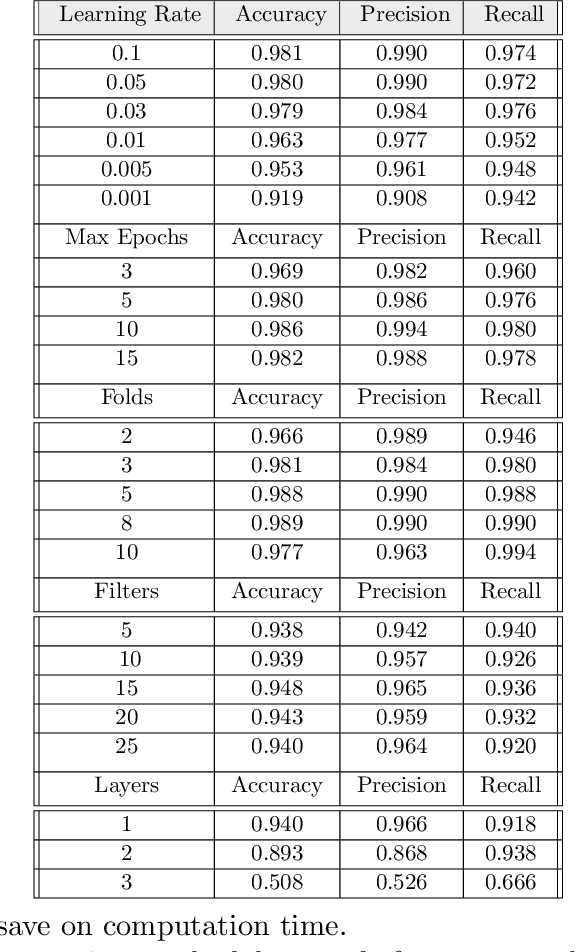

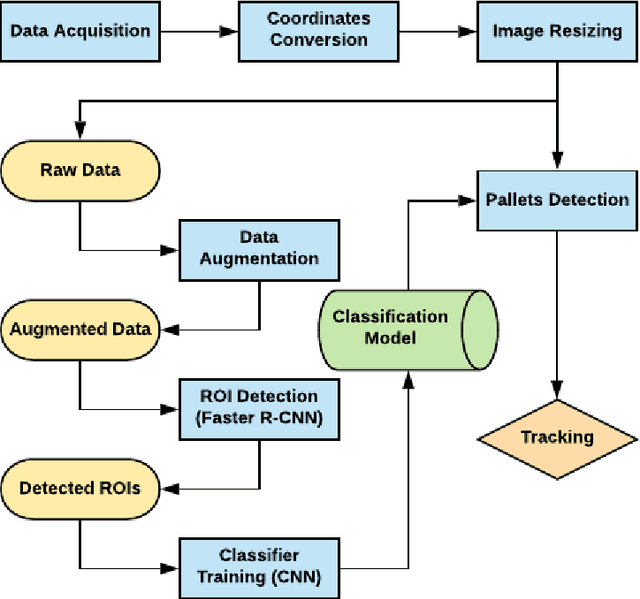
The use of automated guided vehicles (AGVs) has played a pivotal role in manufacturing and distribution operations, providing reliable and efficient product handling. In this project, we constructed a deep learning-based pallets detection and tracking architecture for pallets detection and position tracking. By using data preprocessing and augmentation techniques and experiment with hyperparameter tuning, we achieved the result with 25% reduction of error rate, 28.5% reduction of false negative rate, and 20% reduction of training time.