 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
Active Light Modulation to Counter Manipulation of Speech Visual Content
Apr 30, 2025



High-profile speech videos are prime targets for falsification, owing to their accessibility and influence. This work proposes Spotlight, a low-overhead and unobtrusive system for protecting live speech videos from visual falsification of speaker identity and lip and facial motion. Unlike predominant falsification detection methods operating in the digital domain, Spotlight creates dynamic physical signatures at the event site and embeds them into all video recordings via imperceptible modulated light. These physical signatures encode semantically-meaningful features unique to the speech event, including the speaker's identity and facial motion, and are cryptographically-secured to prevent spoofing. The signatures can be extracted from any video downstream and validated against the portrayed speech content to check its integrity. Key elements of Spotlight include (1) a framework for generating extremely compact (i.e., 150-bit), pose-invariant speech video features, based on locality-sensitive hashing; and (2) an optical modulation scheme that embeds >200 bps into video while remaining imperceptible both in video and live. Prototype experiments on extensive video datasets show Spotlight achieves AUCs $\geq$ 0.99 and an overall true positive rate of 100% in detecting falsified videos. Further, Spotlight is highly robust across recording conditions, video post-processing techniques, and white-box adversarial attacks on its video feature extraction methodologies.
Set Phasers to Stun: Beaming Power and Control to Mobile Robots with Laser Light
Apr 24, 2025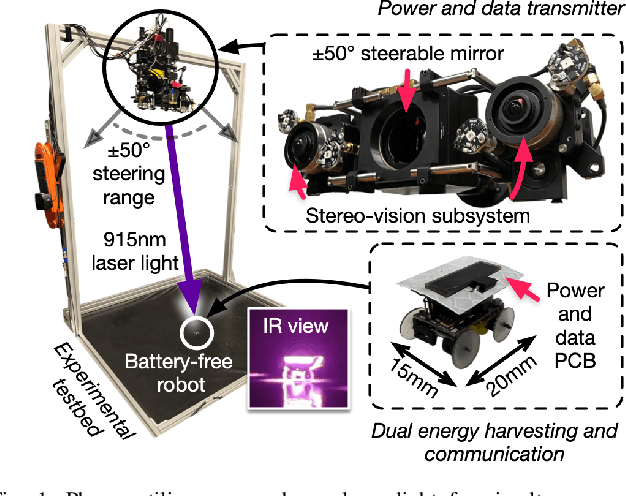
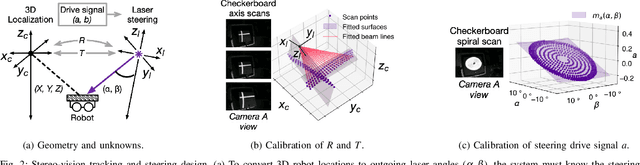
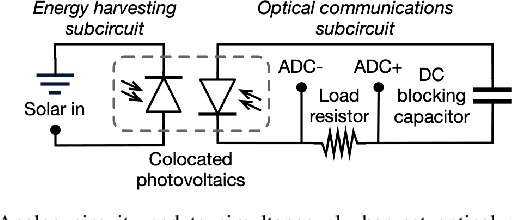
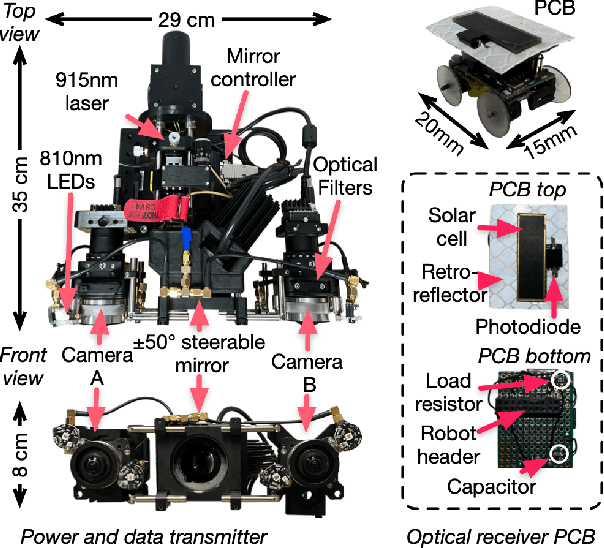
We present Phaser, a flexible system that directs narrow-beam laser light to moving robots for concurrent wireless power delivery and communication. We design a semi-automatic calibration procedure to enable fusion of stereo-vision-based 3D robot tracking with high-power beam steering, and a low-power optical communication scheme that reuses the laser light as a data channel. We fabricate a Phaser prototype using off-the-shelf hardware and evaluate its performance with battery-free autonomous robots. Phaser delivers optical power densities of over 110 mW/cm$^2$ and error-free data to mobile robots at multi-meter ranges, with on-board decoding drawing 0.3 mA (97\% less current than Bluetooth Low Energy). We demonstrate Phaser fully powering gram-scale battery-free robots to nearly 2x higher speeds than prior work while simultaneously controlling them to navigate around obstacles and along paths. Code, an open-source design guide, and a demonstration video of Phaser is available at https://mobilex.cs.columbia.edu/phaser.
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
Nov 18, 2024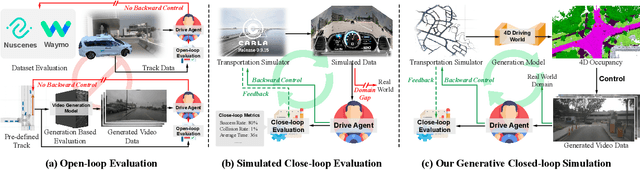
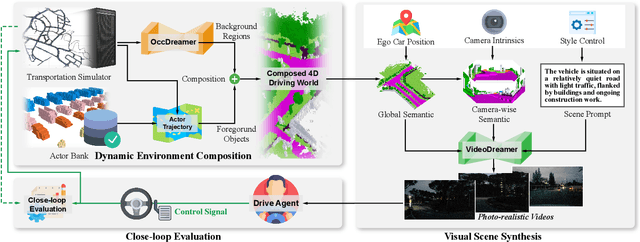

Autonomous driving evaluation requires simulation environments that closely replicate actual road conditions, including real-world sensory data and responsive feedback loops. However, many existing simulations need to predict waypoints along fixed routes on public datasets or synthetic photorealistic data, \ie, open-loop simulation usually lacks the ability to assess dynamic decision-making. While the recent efforts of closed-loop simulation offer feedback-driven environments, they cannot process visual sensor inputs or produce outputs that differ from real-world data. To address these challenges, we propose DrivingSphere, a realistic and closed-loop simulation framework. Its core idea is to build 4D world representation and generate real-life and controllable driving scenarios. In specific, our framework includes a Dynamic Environment Composition module that constructs a detailed 4D driving world with a format of occupancy equipping with static backgrounds and dynamic objects, and a Visual Scene Synthesis module that transforms this data into high-fidelity, multi-view video outputs, ensuring spatial and temporal consistency. By providing a dynamic and realistic simulation environment, DrivingSphere enables comprehensive testing and validation of autonomous driving algorithms, ultimately advancing the development of more reliable autonomous cars. The benchmark will be publicly released.
DiVE: DiT-based Video Generation with Enhanced Control
Sep 03, 2024



Generating high-fidelity, temporally consistent videos in autonomous driving scenarios faces a significant challenge, e.g. problematic maneuvers in corner cases. Despite recent video generation works are proposed to tackcle the mentioned problem, i.e. models built on top of Diffusion Transformers (DiT), works are still missing which are targeted on exploring the potential for multi-view videos generation scenarios. Noticeably, we propose the first DiT-based framework specifically designed for generating temporally and multi-view consistent videos which precisely match the given bird's-eye view layouts control. Specifically, the proposed framework leverages a parameter-free spatial view-inflated attention mechanism to guarantee the cross-view consistency, where joint cross-attention modules and ControlNet-Transformer are integrated to further improve the precision of control. To demonstrate our advantages, we extensively investigate the qualitative comparisons on nuScenes dataset, particularly in some most challenging corner cases. In summary, the effectiveness of our proposed method in producing long, controllable, and highly consistent videos under difficult conditions is proven to be effective.
AIRA: A Low-cost IR-based Approach Towards Autonomous Precision Drone Landing and NLOS Indoor Navigation
Jul 08, 2024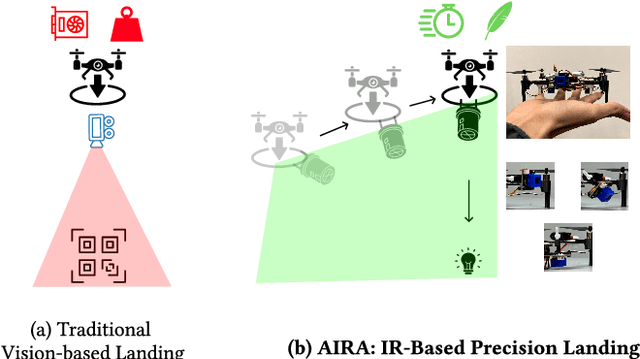
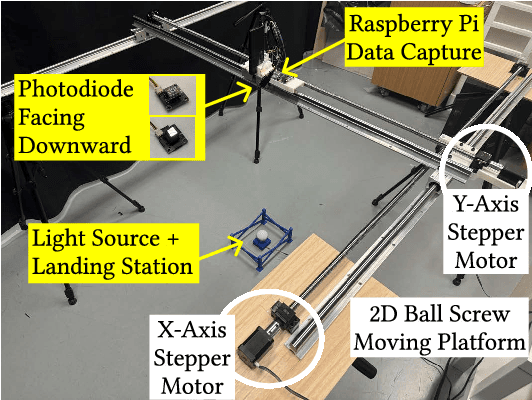
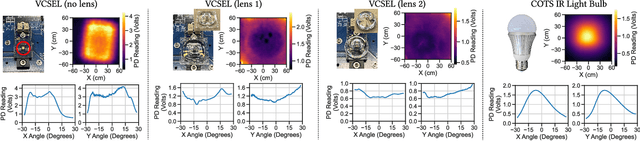
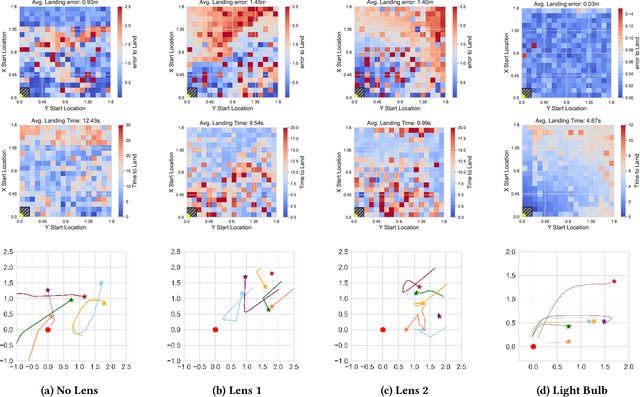
Automatic drone landing is an important step for achieving fully autonomous drones. Although there are many works that leverage GPS, video, wireless signals, and active acoustic sensing to perform precise landing, autonomous drone landing remains an unsolved challenge for palm-sized microdrones that may not be able to support the high computational requirements of vision, wireless, or active audio sensing. We propose AIRA, a low-cost infrared light-based platform that targets precise and efficient landing of low-resource microdrones. AIRA consists of an infrared light bulb at the landing station along with an energy efficient hardware photodiode (PD) sensing platform at the bottom of the drone. AIRA costs under 83 USD, while achieving comparable performance to existing vision-based methods at a fraction of the energy cost. AIRA requires only three PDs without any complex pattern recognition models to accurately land the drone, under $10$cm of error, from up to $11.1$ meters away, compared to camera-based methods that require recognizing complex markers using high resolution images with a range of only up to $1.2$ meters from the same height. Moreover, we demonstrate that AIRA can accurately guide drones in low light and partial non line of sight scenarios, which are difficult for traditional vision-based approaches.