 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Order Matters in Autoregressive Speech Synthesis
Jan 13, 2026Autoregressive speech synthesis often adopts a left-to-right order, yet generation order is a modelling choice. We investigate decoding order through masked diffusion framework, which progressively unmasks positions and allows arbitrary decoding orders during training and inference. By interpolating between identity and random permutations, we show that randomness in decoding order affects speech quality. We further compare fixed strategies, such as \texttt{l2r} and \texttt{r2l} with adaptive ones, such as Top-$K$, finding that fixed-order decoding, including the dominating left-to-right approach, is suboptimal, while adaptive decoding yields better performance. Finally, since masked diffusion requires discrete inputs, we quantise acoustic representations and find that even 1-bit quantisation can support reasonably high-quality speech.
AIRA: A Low-cost IR-based Approach Towards Autonomous Precision Drone Landing and NLOS Indoor Navigation
Jul 08, 2024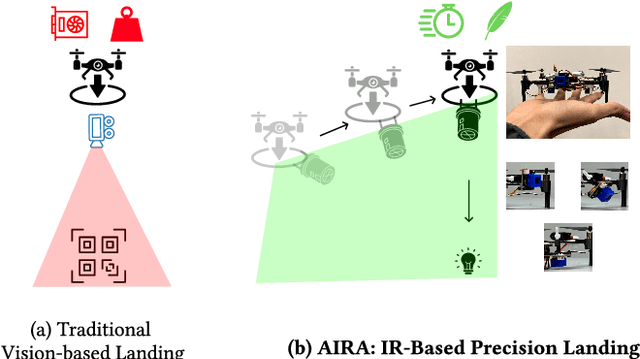
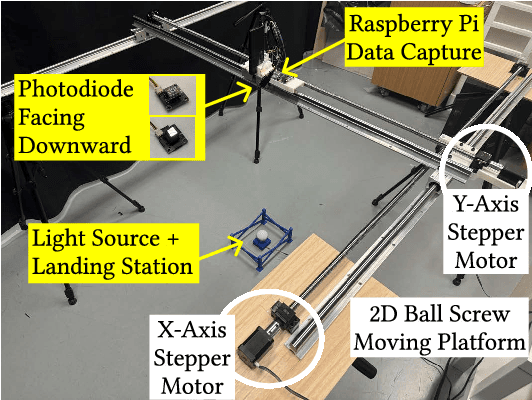
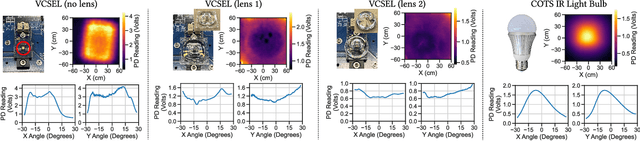
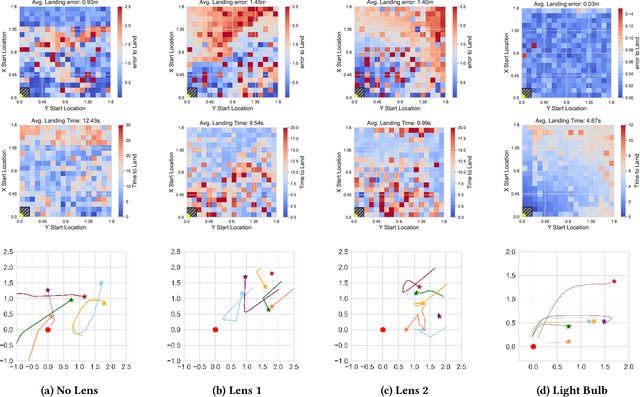
Automatic drone landing is an important step for achieving fully autonomous drones. Although there are many works that leverage GPS, video, wireless signals, and active acoustic sensing to perform precise landing, autonomous drone landing remains an unsolved challenge for palm-sized microdrones that may not be able to support the high computational requirements of vision, wireless, or active audio sensing. We propose AIRA, a low-cost infrared light-based platform that targets precise and efficient landing of low-resource microdrones. AIRA consists of an infrared light bulb at the landing station along with an energy efficient hardware photodiode (PD) sensing platform at the bottom of the drone. AIRA costs under 83 USD, while achieving comparable performance to existing vision-based methods at a fraction of the energy cost. AIRA requires only three PDs without any complex pattern recognition models to accurately land the drone, under $10$cm of error, from up to $11.1$ meters away, compared to camera-based methods that require recognizing complex markers using high resolution images with a range of only up to $1.2$ meters from the same height. Moreover, we demonstrate that AIRA can accurately guide drones in low light and partial non line of sight scenarios, which are difficult for traditional vision-based approaches.
TRAMBA: A Hybrid Transformer and Mamba Architecture for Practical Audio and Bone Conduction Speech Super Resolution and Enhancement on Mobile and Wearable Platforms
May 02, 2024We propose TRAMBA, a hybrid transformer and Mamba architecture for acoustic and bone conduction speech enhancement, suitable for mobile and wearable platforms. Bone conduction speech enhancement has been impractical to adopt in mobile and wearable platforms for several reasons: (i) data collection is labor-intensive, resulting in scarcity; (ii) there exists a performance gap between state of-art models with memory footprints of hundreds of MBs and methods better suited for resource-constrained systems. To adapt TRAMBA to vibration-based sensing modalities, we pre-train TRAMBA with audio speech datasets that are widely available. Then, users fine-tune with a small amount of bone conduction data. TRAMBA outperforms state-of-art GANs by up to 7.3% in PESQ and 1.8% in STOI, with an order of magnitude smaller memory footprint and an inference speed up of up to 465 times. We integrate TRAMBA into real systems and show that TRAMBA (i) improves battery life of wearables by up to 160% by requiring less data sampling and transmission; (ii) generates higher quality voice in noisy environments than over-the-air speech; (iii) requires a memory footprint of less than 20.0 MB.
RASP: A Drone-based Reconfigurable Actuation and Sensing Platform Towards Ambient Intelligent Systems
Mar 19, 2024Realizing consumer-grade drones that are as useful as robot vacuums throughout our homes or personal smartphones in our daily lives requires drones to sense, actuate, and respond to general scenarios that may arise. Towards this vision, we propose RASP, a modular and reconfigurable sensing and actuation platform that allows drones to autonomously swap onboard sensors and actuators in only 25 seconds, allowing a single drone to quickly adapt to a diverse range of tasks. RASP consists of a mechanical layer to physically swap sensor modules, an electrical layer to maintain power and communication lines to the sensor/actuator, and a software layer to maintain a common interface between the drone and any sensor module in our platform. Leveraging recent advances in large language and visual language models, we further introduce the architecture, implementation, and real-world deployments of a personal assistant system utilizing RASP. We demonstrate that RASP can enable a diverse range of useful tasks in home, office, lab, and other indoor settings.
Dispersed Pixel Perturbation-based Imperceptible Backdoor Trigger for Image Classifier Models
Aug 19, 2022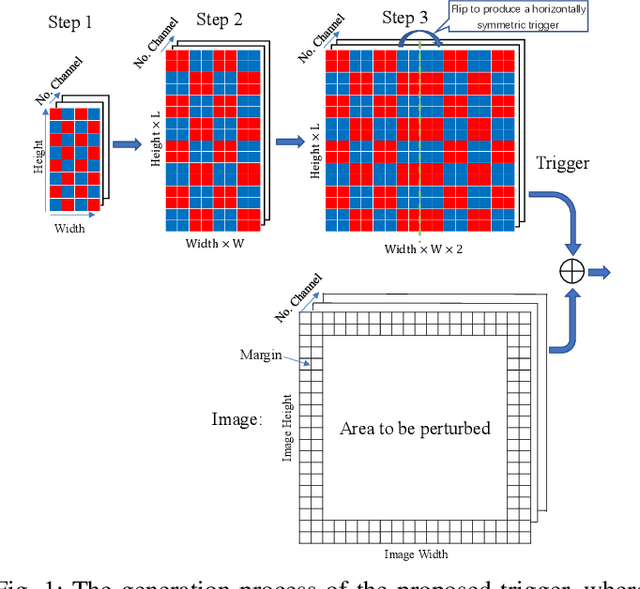
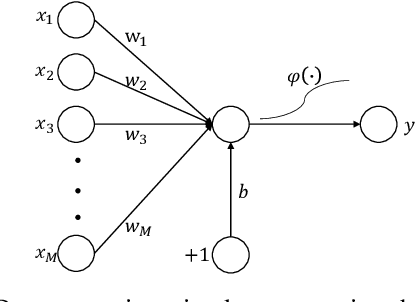
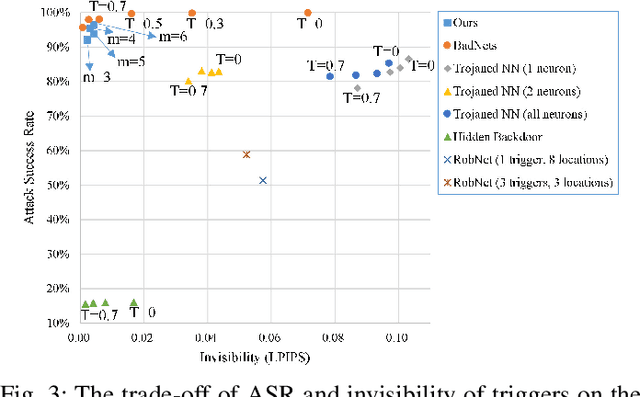
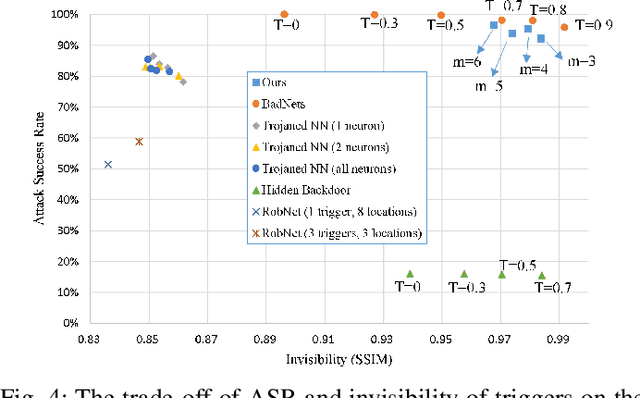
Typical deep neural network (DNN) backdoor attacks are based on triggers embedded in inputs. Existing imperceptible triggers are computationally expensive or low in attack success. In this paper, we propose a new backdoor trigger, which is easy to generate, imperceptible, and highly effective. The new trigger is a uniformly randomly generated three-dimensional (3D) binary pattern that can be horizontally and/or vertically repeated and mirrored and superposed onto three-channel images for training a backdoored DNN model. Dispersed throughout an image, the new trigger produces weak perturbation to individual pixels, but collectively holds a strong recognizable pattern to train and activate the backdoor of the DNN. We also analytically reveal that the trigger is increasingly effective with the improving resolution of the images. Experiments are conducted using the ResNet-18 and MLP models on the MNIST, CIFAR-10, and BTSR datasets. In terms of imperceptibility, the new trigger outperforms existing triggers, such as BadNets, Trojaned NN, and Hidden Backdoor, by over an order of magnitude. The new trigger achieves an almost 100% attack success rate, only reduces the classification accuracy by less than 0.7%-2.4%, and invalidates the state-of-the-art defense techniques.