 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSRL: Generalizable Time-Series Behavioral Modeling via Semantic RL-Tuned LLMs -- A Case Study in Mental Health
May 20, 2026Longitudinal passive sensing enables continuous health prediction, yet models often fail under cross-dataset distribution shifts. Traditional ML overfits cohort-specific artifacts, while Large Language Models (LLMs) struggle to reason reliably over long, heterogeneous time-series. We introduce TimeSRL, a two-stage LLM framework that routes predictions through an explicit semantic bottleneck. The model first abstracts raw signals into high-level natural language, then predicts behavioral outcomes from these abstractions alone. This forces the model to reason over semantic concepts that we argue generalize better than raw numbers. We optimize this process end-to-end using Group Relative Policy Optimization (GRPO) with Reinforcement Learning from Verifiable Rewards (RLVR), learning outcome-aligned abstractions without gold intermediate annotations. Instantiated on mental-health prediction, TimeSRL achieves state-of-the-art performance on a benchmark designed to stress-test cross-cohort generalization under a rigorous leave-one-dataset-out (LOSO) protocol, reducing mean absolute error (MAE) over strong non-LLM ML and LLM baselines by 3.1--10.1% and 9.5--44.1% for anxiety, and 3.2--9.6% and 27.4--57.6% for depression (all $p$s<0.05). TimeSRL significantly outperforms prior methods in cross-benchmark transfer across different sensing pipelines, rivaling its own within-domain performance without target-domain fine-tuning. These results demonstrate that semantic abstractions are reusable and point to a new direction for generalizable behavior modeling via RL-tuned LLMs.
Pro$^2$Assist: Continuous Step-Aware Proactive Assistance with Multimodal Egocentric Perception for Long-Horizon Procedural Tasks
May 05, 2026Procedural tasks with multiple ordered steps are ubiquitous in daily life. Recent advances in multimodal large language models (MLLMs) have enabled personal assistants that support daily activities. However, existing systems primarily provide reactive guidance triggered by user queries, or limited proactive assistance for isolated short-term events rather than long-horizon procedural tasks. In this work, we introduce Pro$^2$Assist, a step-aware proactive assistant that continuously tracks fine-grained task progress and reasons over the user's evolving state to provide timely assistance throughout tasks. Pro$^2$Assist leverages multimodal data from augmented reality (AR) glasses to achieve motion-based perception. It then extracts step-oriented procedural context from multi-scale temporal dynamics and task-specific expert knowledge. Based on both sensory input and procedural context, Pro$^2$Assist performs continuous reasoning to infer user needs and display timely assistance on AR glasses. We evaluate Pro$^2$Assist using a dataset curated from public sources and a real-world dataset collected on our testbed with AR glasses. Extensive evaluations show that Pro$^2$Assist outperforms the best-performing baselines by over 21% in procedural action understanding accuracy, and it achieves up to 2.29x the proactive timing accuracy of baselines. A user study with 20 participants further shows that 90% find Pro$^2$Assist useful, indicating its effectiveness for real-world procedural assistance.
ReSPEC: A Framework for Online Multispectral Sensor Reconfiguration in Dynamic Environments
Feb 11, 2026Multi-sensor fusion is central to robust robotic perception, yet most existing systems operate under static sensor configurations, collecting all modalities at fixed rates and fidelity regardless of their situational utility. This rigidity wastes bandwidth, computation, and energy, and prevents systems from prioritizing sensors under challenging conditions such as poor lighting or occlusion. Recent advances in reinforcement learning (RL) and modality-aware fusion suggest the potential for adaptive perception, but prior efforts have largely focused on re-weighting features at inference time, ignoring the physical cost of sensor data collection. We introduce a framework that unifies sensing, learning, and actuation into a closed reconfiguration loop. A task-specific detection backbone extracts multispectral features (e.g. RGB, IR, mmWave, depth) and produces quantitative contribution scores for each modality. These scores are passed to an RL agent, which dynamically adjusts sensor configurations, including sampling frequency, resolution, sensing range, and etc., in real time. Less informative sensors are down-sampled or deactivated, while critical sensors are sampled at higher fidelity as environmental conditions evolve. We implement and evaluate this framework on a mobile rover, showing that adaptive control reduces GPU load by 29.3\% with only a 5.3\% accuracy drop compared to a heuristic baseline. These results highlight the potential of resource-aware adaptive sensing for embedded robotic platforms.
Sim2Radar: Toward Bridging the Radar Sim-to-Real Gap with VLM-Guided Scene Reconstruction
Feb 10, 2026Millimeter-wave (mmWave) radar provides reliable perception in visually degraded indoor environments (e.g., smoke, dust, and low light), but learning-based radar perception is bottlenecked by the scarcity and cost of collecting and annotating large-scale radar datasets. We present Sim2Radar, an end-to-end framework that synthesizes training radar data directly from single-view RGB images, enabling scalable data generation without manual scene modeling. Sim2Radar reconstructs a material-aware 3D scene by combining monocular depth estimation, segmentation, and vision-language reasoning to infer object materials, then simulates mmWave propagation with a configurable physics-based ray tracer using Fresnel reflection models parameterized by ITU-R electromagnetic properties. Evaluated on real-world indoor scenes, Sim2Radar improves downstream 3D radar perception via transfer learning: pre-training a radar point-cloud object detection model on synthetic data and fine-tuning on real radar yields up to +3.7 3D AP (IoU 0.3), with gains driven primarily by improved spatial localization. These results suggest that physics-based, vision-driven radar simulation can provide effective geometric priors for radar learning and measurably improve performance under limited real-data supervision.
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
May 20, 2025Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
Exploring Finetuned Audio-LLM on Heart Murmur Features
Jan 23, 2025



Large language models (LLMs) for audio have excelled in recognizing and analyzing human speech, music, and environmental sounds. However, their potential for understanding other types of sounds, particularly biomedical sounds, remains largely underexplored despite significant scientific interest. In this study, we focus on diagnosing cardiovascular diseases using phonocardiograms, i.e., heart sounds. Most existing deep neural network (DNN) paradigms are restricted to heart murmur classification (healthy vs unhealthy) and do not predict other acoustic features of the murmur such as timing, grading, harshness, pitch, and quality, which are important in helping physicians diagnose the underlying heart conditions. We propose to finetune an audio LLM, Qwen2-Audio, on the PhysioNet CirCor DigiScope phonocardiogram (PCG) dataset and evaluate its performance in classifying 11 expert-labeled murmur features. Additionally, we aim to achieve more noise-robust and generalizable system by exploring a preprocessing segmentation algorithm using an audio representation model, SSAMBA. Our results indicate that the LLM-based model outperforms state-of-the-art methods in 8 of the 11 features and performs comparably in the remaining 3. Moreover, the LLM successfully classifies long-tail murmur features with limited training data, a task that all previous methods have failed to classify. These findings underscore the potential of audio LLMs as assistants to human cardiologists in enhancing heart disease diagnosis.
SocialMind: LLM-based Proactive AR Social Assistive System with Human-like Perception for In-situ Live Interactions
Dec 05, 2024

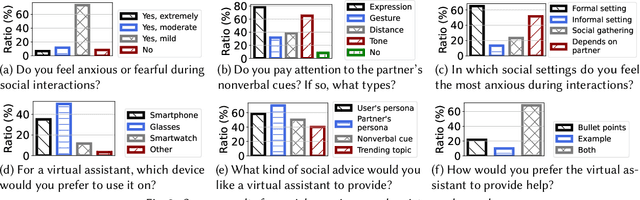
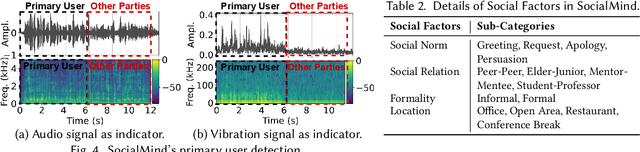
Social interactions are fundamental to human life. The recent emergence of large language models (LLMs)-based virtual assistants has demonstrated their potential to revolutionize human interactions and lifestyles. However, existing assistive systems mainly provide reactive services to individual users, rather than offering in-situ assistance during live social interactions with conversational partners. In this study, we introduce SocialMind, the first LLM-based proactive AR social assistive system that provides users with in-situ social assistance. SocialMind employs human-like perception leveraging multi-modal sensors to extract both verbal and nonverbal cues, social factors, and implicit personas, incorporating these social cues into LLM reasoning for social suggestion generation. Additionally, SocialMind employs a multi-tier collaborative generation strategy and proactive update mechanism to display social suggestions on Augmented Reality (AR) glasses, ensuring that suggestions are timely provided to users without disrupting the natural flow of conversation. Evaluations on three public datasets and a user study with 20 participants show that SocialMind achieves 38.3% higher engagement compared to baselines, and 95% of participants are willing to use SocialMind in their live social interactions.
AIRA: A Low-cost IR-based Approach Towards Autonomous Precision Drone Landing and NLOS Indoor Navigation
Jul 08, 2024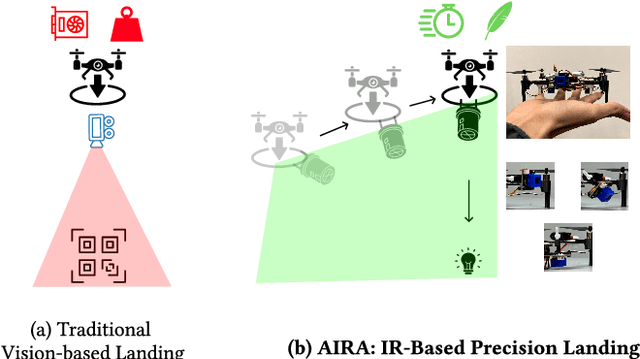
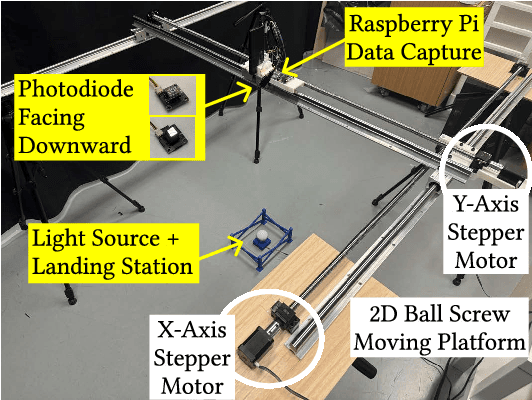
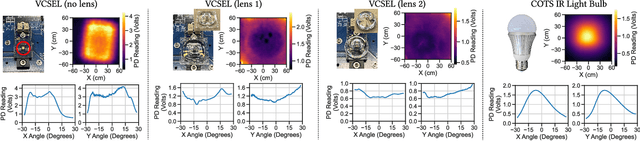
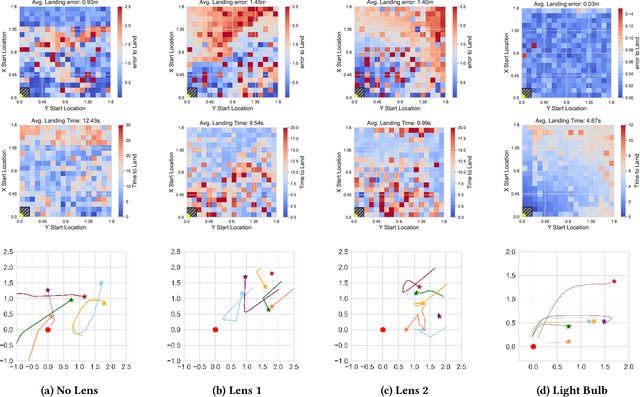
Automatic drone landing is an important step for achieving fully autonomous drones. Although there are many works that leverage GPS, video, wireless signals, and active acoustic sensing to perform precise landing, autonomous drone landing remains an unsolved challenge for palm-sized microdrones that may not be able to support the high computational requirements of vision, wireless, or active audio sensing. We propose AIRA, a low-cost infrared light-based platform that targets precise and efficient landing of low-resource microdrones. AIRA consists of an infrared light bulb at the landing station along with an energy efficient hardware photodiode (PD) sensing platform at the bottom of the drone. AIRA costs under 83 USD, while achieving comparable performance to existing vision-based methods at a fraction of the energy cost. AIRA requires only three PDs without any complex pattern recognition models to accurately land the drone, under $10$cm of error, from up to $11.1$ meters away, compared to camera-based methods that require recognizing complex markers using high resolution images with a range of only up to $1.2$ meters from the same height. Moreover, we demonstrate that AIRA can accurately guide drones in low light and partial non line of sight scenarios, which are difficult for traditional vision-based approaches.
DrHouse: An LLM-empowered Diagnostic Reasoning System through Harnessing Outcomes from Sensor Data and Expert Knowledge
May 21, 2024Large language models (LLMs) have the potential to transform digital healthcare, as evidenced by recent advances in LLM-based virtual doctors. However, current approaches rely on patient's subjective descriptions of symptoms, causing increased misdiagnosis. Recognizing the value of daily data from smart devices, we introduce a novel LLM-based multi-turn consultation virtual doctor system, DrHouse, which incorporates three significant contributions: 1) It utilizes sensor data from smart devices in the diagnosis process, enhancing accuracy and reliability. 2) DrHouse leverages continuously updating medical databases such as Up-to-Date and PubMed to ensure our model remains at diagnostic standard's forefront. 3) DrHouse introduces a novel diagnostic algorithm that concurrently evaluates potential diseases and their likelihood, facilitating more nuanced and informed medical assessments. Through multi-turn interactions, DrHouse determines the next steps, such as accessing daily data from smart devices or requesting in-lab tests, and progressively refines its diagnoses. Evaluations on three public datasets and our self-collected datasets show that DrHouse can achieve up to an 18.8% increase in diagnosis accuracy over the state-of-the-art baselines. The results of a 32-participant user study show that 75% medical experts and 91.7% patients are willing to use DrHouse.