 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIFERENCE: A Discrete Event Simulation Framework for Developing Distributed AI Models
Mar 27, 2026Developing and evaluating distributed inference algorithms remains difficult due to the lack of standardized tools for modeling heterogeneous devices and networks. Existing studies often rely on ad-hoc testbeds or proprietary infrastructure, making results hard to reproduce and limiting exploration of hypothetical hardware or network configurations. We present UNIFERENCE, a discrete-event simulation (DES) framework designed for developing, benchmarking, and deploying distributed AI models within a unified environment. UNIFERENCE models device and network behavior through lightweight logical processes that synchronize only on communication primitives, eliminating rollbacks while preserving the causal order. It integrates seamlessly with PyTorch Distributed, enabling the same codebase to transition from simulation to real deployment. Our evaluation demonstrates that UNIFERENCE profiles runtime with up to 98.6% accuracy compared to real physical deployments across diverse backends and hardware setups. By bridging simulation and deployment, UNIFERENCE provides an accessible, reproducible platform for studying distributed inference algorithms and exploring future system designs, from high-performance clusters to edge-scale devices. The framework is open-sourced at https://github.com/Dogacel/Uniference.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025
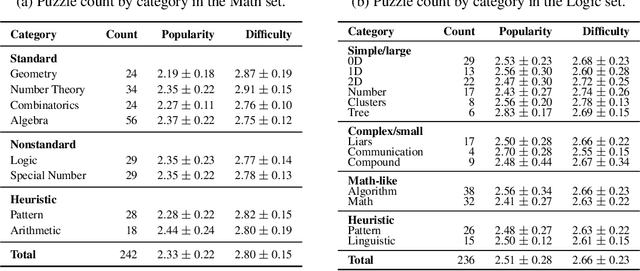

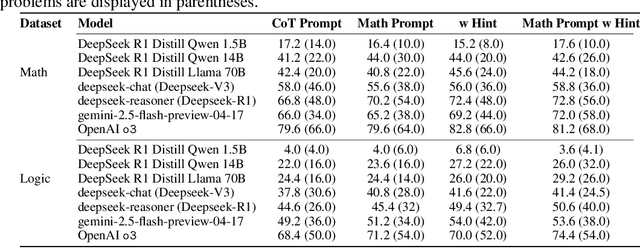
Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
TW-CRL: Time-Weighted Contrastive Reward Learning for Efficient Inverse Reinforcement Learning
Apr 08, 2025Episodic tasks in Reinforcement Learning (RL) often pose challenges due to sparse reward signals and high-dimensional state spaces, which hinder efficient learning. Additionally, these tasks often feature hidden "trap states" -- irreversible failures that prevent task completion but do not provide explicit negative rewards to guide agents away from repeated errors. To address these issues, we propose Time-Weighted Contrastive Reward Learning (TW-CRL), an Inverse Reinforcement Learning (IRL) framework that leverages both successful and failed demonstrations. By incorporating temporal information, TW-CRL learns a dense reward function that identifies critical states associated with success or failure. This approach not only enables agents to avoid trap states but also encourages meaningful exploration beyond simple imitation of expert trajectories. Empirical evaluations on navigation tasks and robotic manipulation benchmarks demonstrate that TW-CRL surpasses state-of-the-art methods, achieving improved efficiency and robustness.
ElastiFormer: Learned Redundancy Reduction in Transformer via Self-Distillation
Nov 22, 2024



We introduce ElastiFormer, a post-training technique that adapts pretrained Transformer models into an elastic counterpart with variable inference time compute. ElastiFormer introduces small routing modules (as low as .00006% additional trainable parameters) to dynamically selects subsets of network parameters and input tokens to be processed by each layer of the pretrained network in an inputdependent manner. The routing modules are trained using self-distillation losses to minimize the differences between the output of the pretrained-model and their elastic counterparts. As ElastiFormer makes no assumption regarding the modality of the pretrained Transformer model, it can be readily applied to all modalities covering causal language modeling, image modeling as well as visual-language modeling tasks. We show that 20% to 50% compute saving could be achieved for different components of the transformer layer, which could be further reduced by adding very low rank LoRA weights (rank 1) trained via the same distillation objective. Finally, by comparing routing trained on different subsets of ImageNet, we show that ElastiFormer is robust against the training domain.
AIRA: A Low-cost IR-based Approach Towards Autonomous Precision Drone Landing and NLOS Indoor Navigation
Jul 08, 2024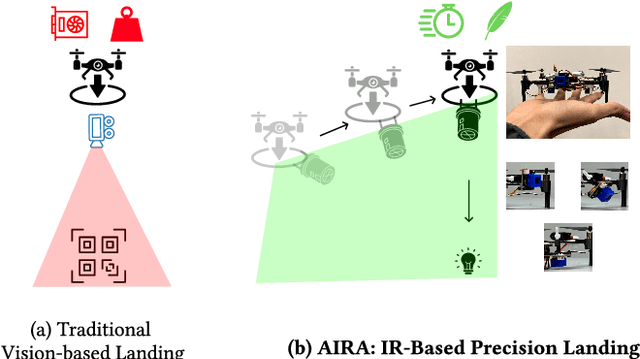
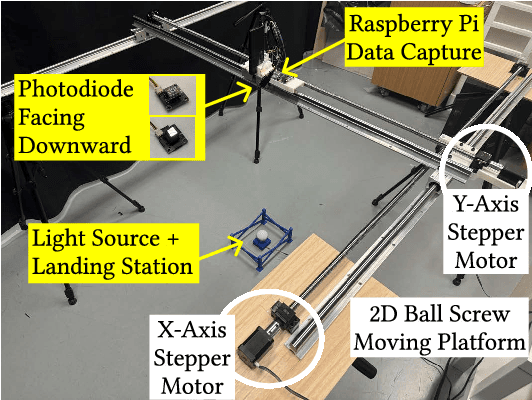
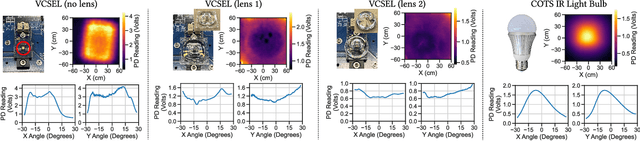
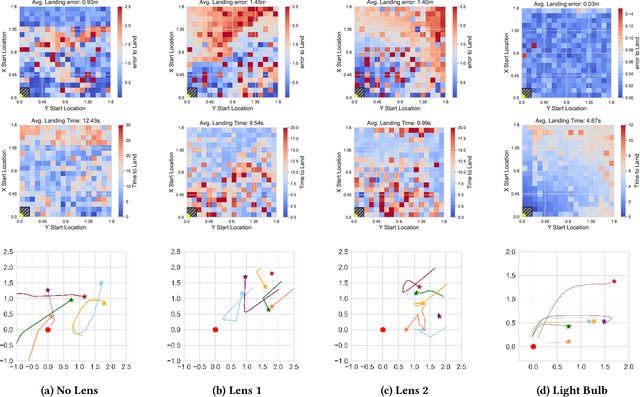
Automatic drone landing is an important step for achieving fully autonomous drones. Although there are many works that leverage GPS, video, wireless signals, and active acoustic sensing to perform precise landing, autonomous drone landing remains an unsolved challenge for palm-sized microdrones that may not be able to support the high computational requirements of vision, wireless, or active audio sensing. We propose AIRA, a low-cost infrared light-based platform that targets precise and efficient landing of low-resource microdrones. AIRA consists of an infrared light bulb at the landing station along with an energy efficient hardware photodiode (PD) sensing platform at the bottom of the drone. AIRA costs under 83 USD, while achieving comparable performance to existing vision-based methods at a fraction of the energy cost. AIRA requires only three PDs without any complex pattern recognition models to accurately land the drone, under $10$cm of error, from up to $11.1$ meters away, compared to camera-based methods that require recognizing complex markers using high resolution images with a range of only up to $1.2$ meters from the same height. Moreover, we demonstrate that AIRA can accurately guide drones in low light and partial non line of sight scenarios, which are difficult for traditional vision-based approaches.
TRAMBA: A Hybrid Transformer and Mamba Architecture for Practical Audio and Bone Conduction Speech Super Resolution and Enhancement on Mobile and Wearable Platforms
May 02, 2024We propose TRAMBA, a hybrid transformer and Mamba architecture for acoustic and bone conduction speech enhancement, suitable for mobile and wearable platforms. Bone conduction speech enhancement has been impractical to adopt in mobile and wearable platforms for several reasons: (i) data collection is labor-intensive, resulting in scarcity; (ii) there exists a performance gap between state of-art models with memory footprints of hundreds of MBs and methods better suited for resource-constrained systems. To adapt TRAMBA to vibration-based sensing modalities, we pre-train TRAMBA with audio speech datasets that are widely available. Then, users fine-tune with a small amount of bone conduction data. TRAMBA outperforms state-of-art GANs by up to 7.3% in PESQ and 1.8% in STOI, with an order of magnitude smaller memory footprint and an inference speed up of up to 465 times. We integrate TRAMBA into real systems and show that TRAMBA (i) improves battery life of wearables by up to 160% by requiring less data sampling and transmission; (ii) generates higher quality voice in noisy environments than over-the-air speech; (iii) requires a memory footprint of less than 20.0 MB.
RASP: A Drone-based Reconfigurable Actuation and Sensing Platform Towards Ambient Intelligent Systems
Mar 19, 2024Realizing consumer-grade drones that are as useful as robot vacuums throughout our homes or personal smartphones in our daily lives requires drones to sense, actuate, and respond to general scenarios that may arise. Towards this vision, we propose RASP, a modular and reconfigurable sensing and actuation platform that allows drones to autonomously swap onboard sensors and actuators in only 25 seconds, allowing a single drone to quickly adapt to a diverse range of tasks. RASP consists of a mechanical layer to physically swap sensor modules, an electrical layer to maintain power and communication lines to the sensor/actuator, and a software layer to maintain a common interface between the drone and any sensor module in our platform. Leveraging recent advances in large language and visual language models, we further introduce the architecture, implementation, and real-world deployments of a personal assistant system utilizing RASP. We demonstrate that RASP can enable a diverse range of useful tasks in home, office, lab, and other indoor settings.
Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances
Nov 11, 2021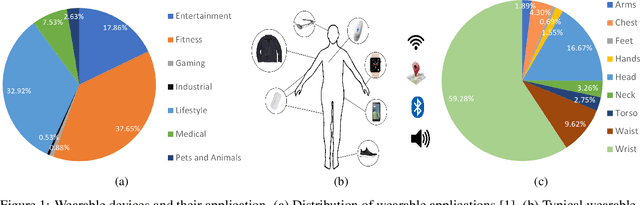
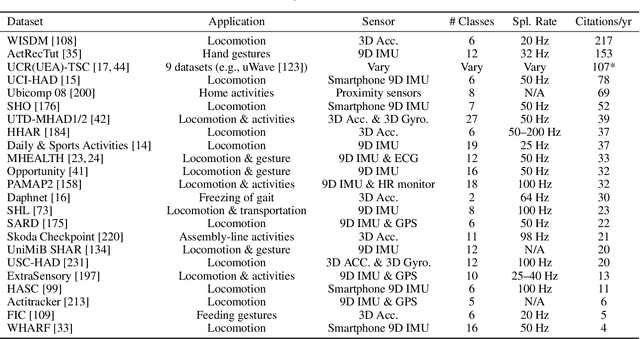
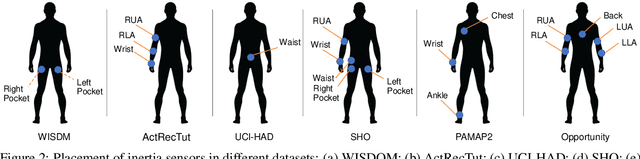
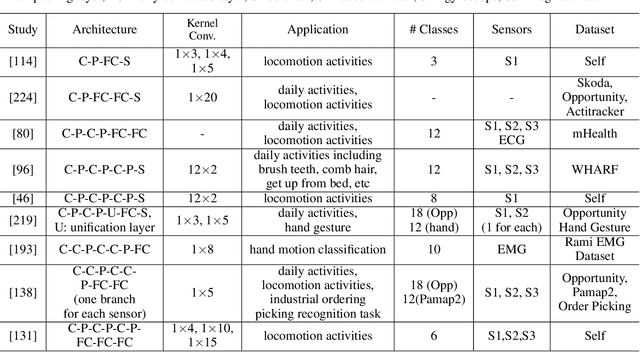
Mobile and wearable devices have enabled numerous applications, including activity tracking, wellness monitoring, and human-computer interaction, that measure and improve our daily lives. Many of these applications are made possible by leveraging the rich collection of low-power sensors found in many mobile and wearable devices to perform human activity recognition (HAR). Recently, deep learning has greatly pushed the boundaries of HAR on mobile and wearable devices. This paper systematically categorizes and summarizes existing work that introduces deep learning methods for wearables-based HAR and provides a comprehensive analysis of the current advancements, developing trends, and major challenges. We also present cutting-edge frontiers and future directions for deep learning--based HAR.