 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Consistency Embodied World Model with Multi-View Trajectory Videos
Nov 19, 2025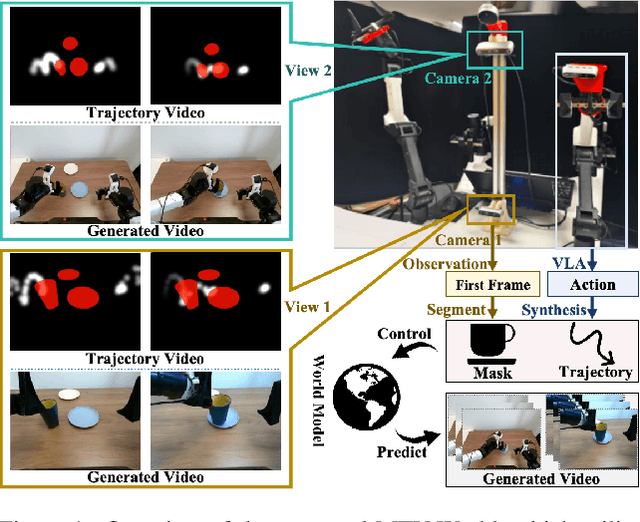

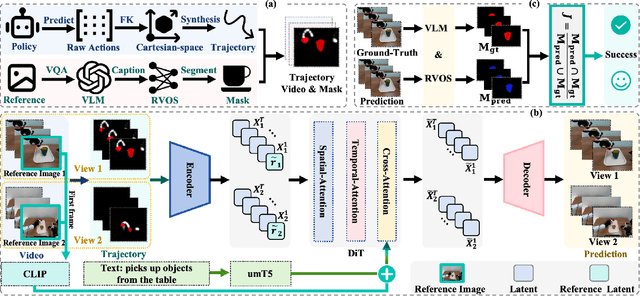
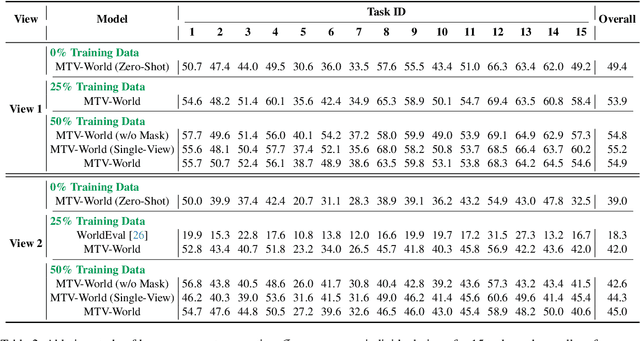
Embodied world models aim to predict and interact with the physical world through visual observations and actions. However, existing models struggle to accurately translate low-level actions (e.g., joint positions) into precise robotic movements in predicted frames, leading to inconsistencies with real-world physical interactions. To address these limitations, we propose MTV-World, an embodied world model that introduces Multi-view Trajectory-Video control for precise visuomotor prediction. Specifically, instead of directly using low-level actions for control, we employ trajectory videos obtained through camera intrinsic and extrinsic parameters and Cartesian-space transformation as control signals. However, projecting 3D raw actions onto 2D images inevitably causes a loss of spatial information, making a single view insufficient for accurate interaction modeling. To overcome this, we introduce a multi-view framework that compensates for spatial information loss and ensures high-consistency with physical world. MTV-World forecasts future frames based on multi-view trajectory videos as input and conditioning on an initial frame per view. Furthermore, to systematically evaluate both robotic motion precision and object interaction accuracy, we develop an auto-evaluation pipeline leveraging multimodal large models and referring video object segmentation models. To measure spatial consistency, we formulate it as an object location matching problem and adopt the Jaccard Index as the evaluation metric. Extensive experiments demonstrate that MTV-World achieves precise control execution and accurate physical interaction modeling in complex dual-arm scenarios.
WorldEval: World Model as Real-World Robot Policies Evaluator
May 25, 2025The field of robotics has made significant strides toward developing generalist robot manipulation policies. However, evaluating these policies in real-world scenarios remains time-consuming and challenging, particularly as the number of tasks scales and environmental conditions change. In this work, we demonstrate that world models can serve as a scalable, reproducible, and reliable proxy for real-world robot policy evaluation. A key challenge is generating accurate policy videos from world models that faithfully reflect the robot actions. We observe that directly inputting robot actions or using high-dimensional encoding methods often fails to generate action-following videos. To address this, we propose Policy2Vec, a simple yet effective approach to turn a video generation model into a world simulator that follows latent action to generate the robot video. We then introduce WorldEval, an automated pipeline designed to evaluate real-world robot policies entirely online. WorldEval effectively ranks various robot policies and individual checkpoints within a single policy, and functions as a safety detector to prevent dangerous actions by newly developed robot models. Through comprehensive paired evaluations of manipulation policies in real-world environments, we demonstrate a strong correlation between policy performance in WorldEval and real-world scenarios. Furthermore, our method significantly outperforms popular methods such as real-to-sim approach.
Speech Audio Generation from dynamic MRI via a Knowledge Enhanced Conditional Variational Autoencoder
Mar 09, 2025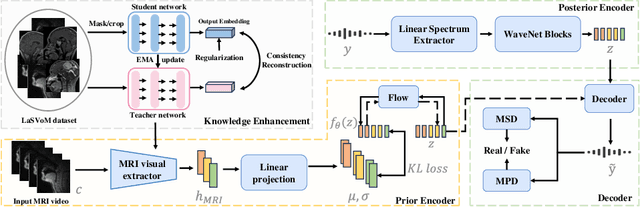
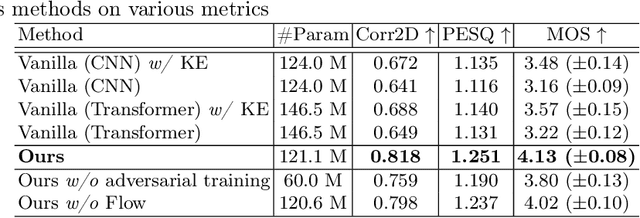
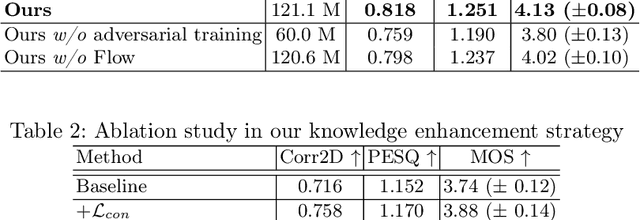
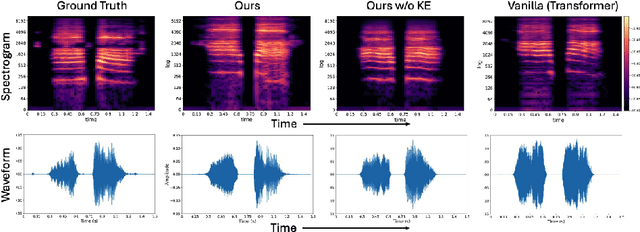
Dynamic Magnetic Resonance Imaging (MRI) of the vocal tract has become an increasingly adopted imaging modality for speech motor studies. Beyond image signals, systematic data loss, noise pollution, and audio file corruption can occur due to the unpredictability of the MRI acquisition environment. In such cases, generating audio from images is critical for data recovery in both clinical and research applications. However, this remains challenging due to hardware constraints, acoustic interference, and data corruption. Existing solutions, such as denoising and multi-stage synthesis methods, face limitations in audio fidelity and generalizability. To address these challenges, we propose a Knowledge Enhanced Conditional Variational Autoencoder (KE-CVAE), a novel two-step "knowledge enhancement + variational inference" framework for generating speech audio signals from cine dynamic MRI sequences. This approach introduces two key innovations: (1) integration of unlabeled MRI data for knowledge enhancement, and (2) a variational inference architecture to improve generative modeling capacity. To the best of our knowledge, this is one of the first attempts at synthesizing speech audio directly from dynamic MRI video sequences. The proposed method was trained and evaluated on an open-source dynamic vocal tract MRI dataset recorded during speech. Experimental results demonstrate its effectiveness in generating natural speech waveforms while addressing MRI-specific acoustic challenges, outperforming conventional deep learning-based synthesis approaches.
A Two-Stage Pretraining-Finetuning Framework for Treatment Effect Estimation with Unmeasured Confounding
Jan 15, 2025

Estimating the conditional average treatment effect (CATE) from observational data plays a crucial role in areas such as e-commerce, healthcare, and economics. Existing studies mainly rely on the strong ignorability assumption that there are no unmeasured confounders, whose presence cannot be tested from observational data and can invalidate any causal conclusion. In contrast, data collected from randomized controlled trials (RCT) do not suffer from confounding, but are usually limited by a small sample size. In this paper, we propose a two-stage pretraining-finetuning (TSPF) framework using both large-scale observational data and small-scale RCT data to estimate the CATE in the presence of unmeasured confounding. In the first stage, a foundational representation of covariates is trained to estimate counterfactual outcomes through large-scale observational data. In the second stage, we propose to train an augmented representation of the covariates, which is concatenated to the foundational representation obtained in the first stage to adjust for the unmeasured confounding. To avoid overfitting caused by the small-scale RCT data in the second stage, we further propose a partial parameter initialization approach, rather than training a separate network. The superiority of our approach is validated on two public datasets with extensive experiments. The code is available at https://github.com/zhouchuanCN/KDD25-TSPF.
DAIL: Data Augmentation for In-Context Learning via Self-Paraphrase
Nov 06, 2023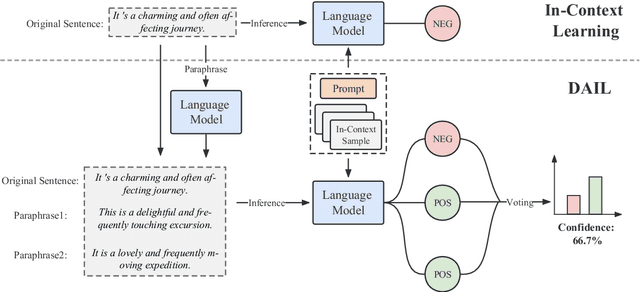
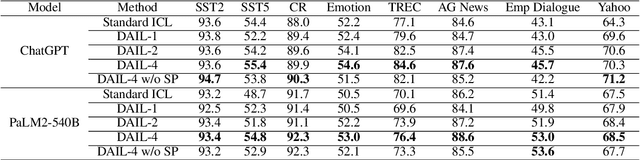
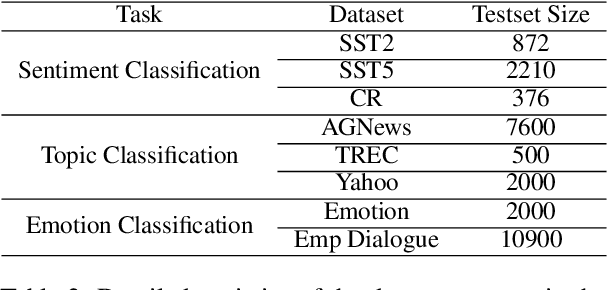
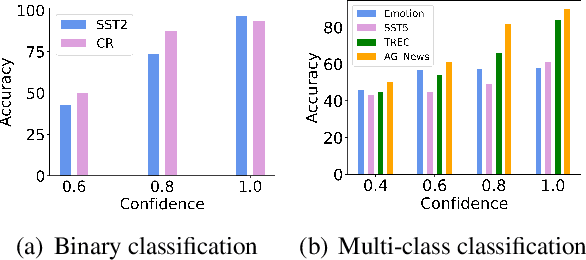
In-Context Learning (ICL) combined with pre-trained large language models has achieved promising results on various NLP tasks. However, ICL requires high-quality annotated demonstrations which might not be available in real-world scenarios. To overcome this limitation, we propose \textbf{D}ata \textbf{A}ugmentation for \textbf{I}n-Context \textbf{L}earning (\textbf{DAIL}). DAIL leverages the intuition that large language models are more familiar with the content generated by themselves. It first utilizes the language model to generate paraphrases of the test sample and employs majority voting to determine the final result based on individual predictions. Our extensive empirical evaluation shows that DAIL outperforms the standard ICL method and other ensemble-based methods in the low-resource scenario. Additionally, we explore the use of voting consistency as a confidence score of the model when the logits of predictions are inaccessible. We believe our work will stimulate further research on ICL in low-resource settings.
Deep Learning in Human Activity Recognition with Wearable Sensors: A Review on Advances
Nov 11, 2021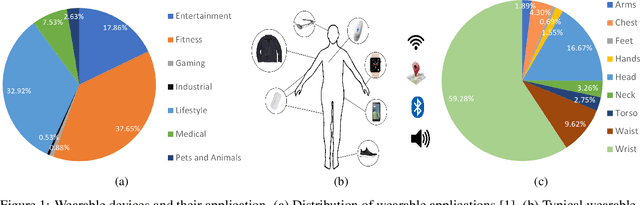
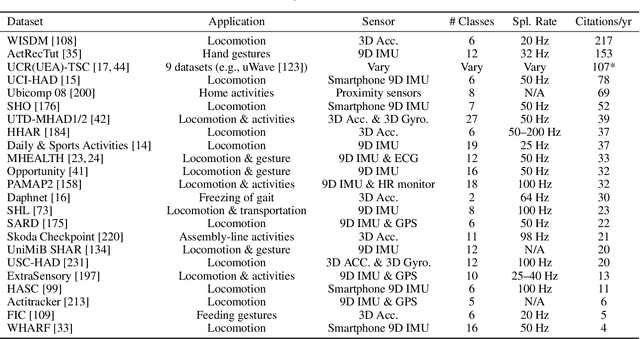
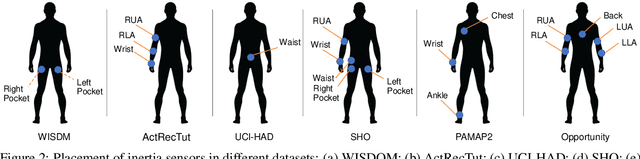
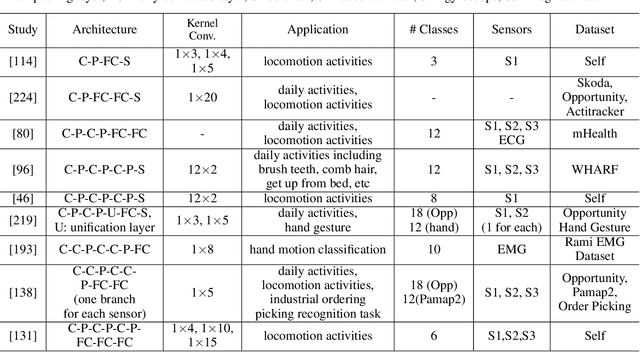
Mobile and wearable devices have enabled numerous applications, including activity tracking, wellness monitoring, and human-computer interaction, that measure and improve our daily lives. Many of these applications are made possible by leveraging the rich collection of low-power sensors found in many mobile and wearable devices to perform human activity recognition (HAR). Recently, deep learning has greatly pushed the boundaries of HAR on mobile and wearable devices. This paper systematically categorizes and summarizes existing work that introduces deep learning methods for wearables-based HAR and provides a comprehensive analysis of the current advancements, developing trends, and major challenges. We also present cutting-edge frontiers and future directions for deep learning--based HAR.