 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Fine-Tuning of 3D Convolutional Foundation Models for ADHD Classification with Low-Rank Adaptation
Nov 08, 2025Early diagnosis of attention-deficit/hyperactivity disorder (ADHD) in children plays a crucial role in improving outcomes in education and mental health. Diagnosing ADHD using neuroimaging data, however, remains challenging due to heterogeneous presentations and overlapping symptoms with other conditions. To address this, we propose a novel parameter-efficient transfer learning approach that adapts a large-scale 3D convolutional foundation model, pre-trained on CT images, to an MRI-based ADHD classification task. Our method introduces Low-Rank Adaptation (LoRA) in 3D by factorizing 3D convolutional kernels into 2D low-rank updates, dramatically reducing trainable parameters while achieving superior performance. In a five-fold cross-validated evaluation on a public diffusion MRI database, our 3D LoRA fine-tuning strategy achieved state-of-the-art results, with one model variant reaching 71.9% accuracy and another attaining an AUC of 0.716. Both variants use only 1.64 million trainable parameters (over 113x fewer than a fully fine-tuned foundation model). Our results represent one of the first successful cross-modal (CT-to-MRI) adaptations of a foundation model in neuroimaging, establishing a new benchmark for ADHD classification while greatly improving efficiency.
Brightness-Invariant Tracking Estimation in Tagged MRI
May 23, 2025Magnetic resonance (MR) tagging is an imaging technique for noninvasively tracking tissue motion in vivo by creating a visible pattern of magnetization saturation (tags) that deforms with the tissue. Due to longitudinal relaxation and progression to steady-state, the tags and tissue brightnesses change over time, which makes tracking with optical flow methods error-prone. Although Fourier methods can alleviate these problems, they are also sensitive to brightness changes as well as spectral spreading due to motion. To address these problems, we introduce the brightness-invariant tracking estimation (BRITE) technique for tagged MRI. BRITE disentangles the anatomy from the tag pattern in the observed tagged image sequence and simultaneously estimates the Lagrangian motion. The inherent ill-posedness of this problem is addressed by leveraging the expressive power of denoising diffusion probabilistic models to represent the probabilistic distribution of the underlying anatomy and the flexibility of physics-informed neural networks to estimate biologically-plausible motion. A set of tagged MR images of a gel phantom was acquired with various tag periods and imaging flip angles to demonstrate the impact of brightness variations and to validate our method. The results show that BRITE achieves more accurate motion and strain estimates as compared to other state of the art methods, while also being resistant to tag fading.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025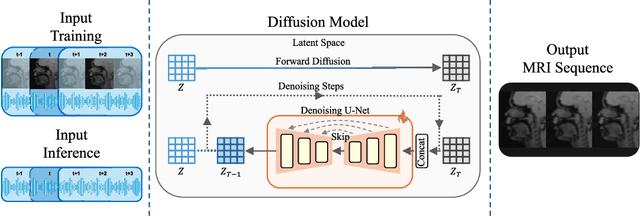
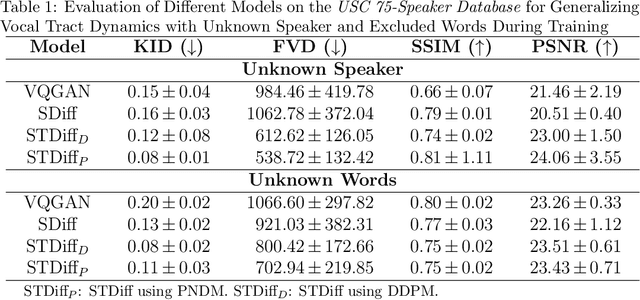
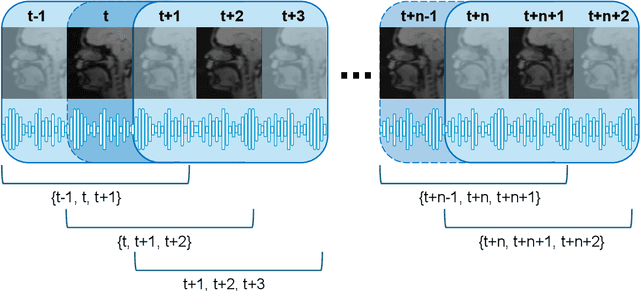

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Speech Audio Generation from dynamic MRI via a Knowledge Enhanced Conditional Variational Autoencoder
Mar 09, 2025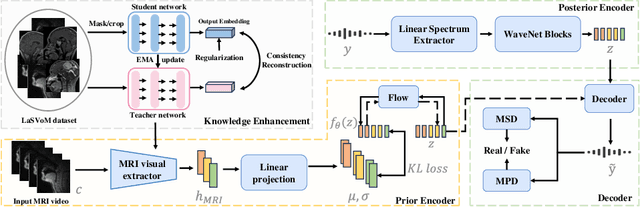
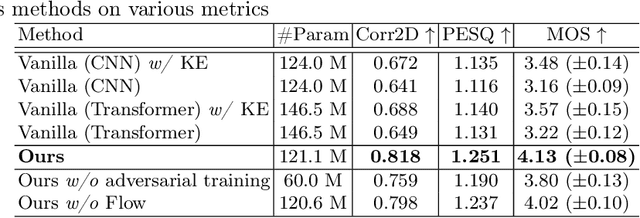
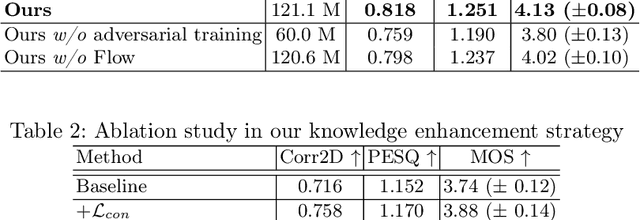
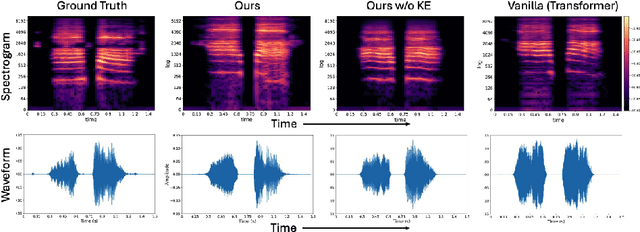
Dynamic Magnetic Resonance Imaging (MRI) of the vocal tract has become an increasingly adopted imaging modality for speech motor studies. Beyond image signals, systematic data loss, noise pollution, and audio file corruption can occur due to the unpredictability of the MRI acquisition environment. In such cases, generating audio from images is critical for data recovery in both clinical and research applications. However, this remains challenging due to hardware constraints, acoustic interference, and data corruption. Existing solutions, such as denoising and multi-stage synthesis methods, face limitations in audio fidelity and generalizability. To address these challenges, we propose a Knowledge Enhanced Conditional Variational Autoencoder (KE-CVAE), a novel two-step "knowledge enhancement + variational inference" framework for generating speech audio signals from cine dynamic MRI sequences. This approach introduces two key innovations: (1) integration of unlabeled MRI data for knowledge enhancement, and (2) a variational inference architecture to improve generative modeling capacity. To the best of our knowledge, this is one of the first attempts at synthesizing speech audio directly from dynamic MRI video sequences. The proposed method was trained and evaluated on an open-source dynamic vocal tract MRI dataset recorded during speech. Experimental results demonstrate its effectiveness in generating natural speech waveforms while addressing MRI-specific acoustic challenges, outperforming conventional deep learning-based synthesis approaches.
DiffuMask-Editor: A Novel Paradigm of Integration Between the Segmentation Diffusion Model and Image Editing to Improve Segmentation Ability
Nov 04, 2024



Semantic segmentation models, like mask2former, often demand a substantial amount of manually annotated data, which is time-consuming and inefficient to acquire. Leveraging state-of-the-art text-to-image models like Midjourney and Stable Diffusion has emerged as an effective strategy for automatically generating synthetic data instead of human annotations. However, prior approaches have been constrained to synthesizing single-instance images due to the instability inherent in generating multiple instances with Stable Diffusion. To expand the domains and diversity of synthetic datasets, this paper introduces a novel paradigm named DiffuMask-Editor, which combines the Diffusion Model for Segmentation with Image Editing. By integrating multiple objects into images using Text2Image models, our method facilitates the creation of more realistic datasets that closely resemble open-world settings while simultaneously generating accurate masks. Our approach significantly reduces the laborious effort associated with manual annotation while ensuring precise mask generation. Experimental results demonstrate that synthetic data generated by DiffuMask-Editor enable segmentation methods to achieve superior performance compared to real data. Particularly in zero-shot backgrounds, DiffuMask-Editor achieves new state-of-the-art results on Unseen classes of VOC 2012. The code and models will be publicly available soon.
Semi-Supervised Bone Marrow Lesion Detection from Knee MRI Segmentation Using Mask Inpainting Models
Sep 27, 2024



Bone marrow lesions (BMLs) are critical indicators of knee osteoarthritis (OA). Since they often appear as small, irregular structures with indistinguishable edges in knee magnetic resonance images (MRIs), effective detection of BMLs in MRI is vital for OA diagnosis and treatment. This paper proposes a semi-supervised local anomaly detection method using mask inpainting models for identification of BMLs in high-resolution knee MRI, effectively integrating a 3D femur bone segmentation model, a large mask inpainting model, and a series of post-processing techniques. The method was evaluated using MRIs at various resolutions from a subset of the public Osteoarthritis Initiative database. Dice score, Intersection over Union (IoU), and pixel-level sensitivity, specificity, and accuracy showed an advantage over the multiresolution knowledge distillation method-a state-of-the-art global anomaly detection method. Especially, segmentation performance is enhanced on higher-resolution images, achieving an over two times performance increase on the Dice score and the IoU score at a 448x448 resolution level. We also demonstrate that with increasing size of the BML region, both the Dice and IoU scores improve as the proportion of distinguishable boundary decreases. The identified BML masks can serve as markers for downstream tasks such as segmentation and classification. The proposed method has shown a potential in improving BML detection, laying a foundation for further advances in imaging-based OA research.
Label-Efficient 3D Brain Segmentation via Complementary 2D Diffusion Models with Orthogonal Views
Jul 17, 2024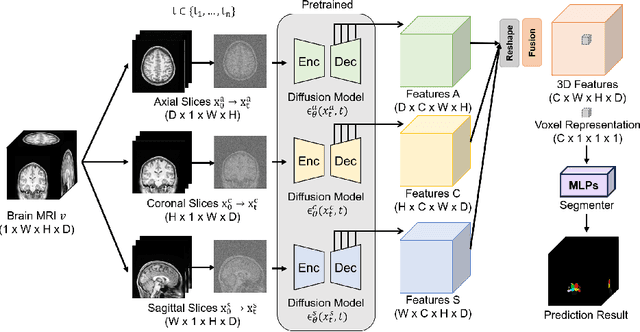
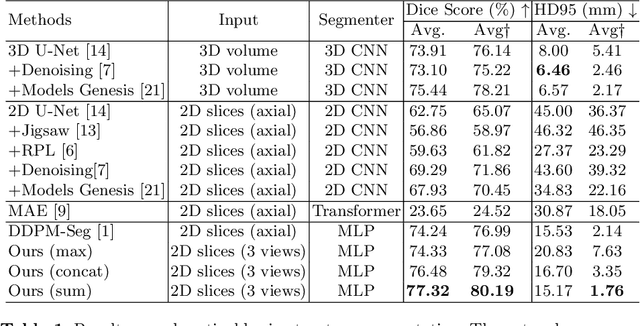
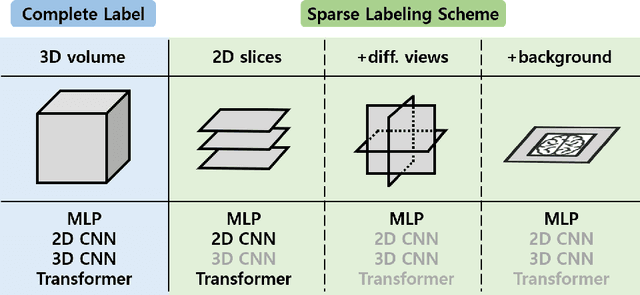
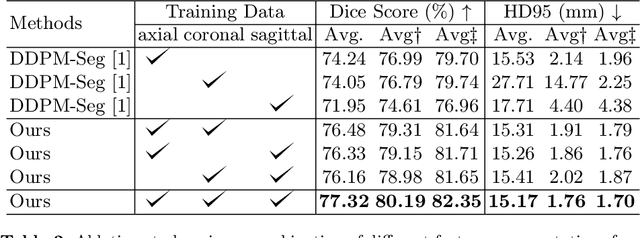
Deep learning-based segmentation techniques have shown remarkable performance in brain segmentation, yet their success hinges on the availability of extensive labeled training data. Acquiring such vast datasets, however, poses a significant challenge in many clinical applications. To address this issue, in this work, we propose a novel 3D brain segmentation approach using complementary 2D diffusion models. The core idea behind our approach is to first mine 2D features with semantic information extracted from the 2D diffusion models by taking orthogonal views as input, followed by fusing them into a 3D contextual feature representation. Then, we use these aggregated features to train multi-layer perceptrons to classify the segmentation labels. Our goal is to achieve reliable segmentation quality without requiring complete labels for each individual subject. Our experiments on training in brain subcortical structure segmentation with a dataset from only one subject demonstrate that our approach outperforms state-of-the-art self-supervised learning methods. Further experiments on the minimum requirement of annotation by sparse labeling yield promising results even with only nine slices and a labeled background region.
Speech motion anomaly detection via cross-modal translation of 4D motion fields from tagged MRI
Feb 10, 2024Understanding the relationship between tongue motion patterns during speech and their resulting speech acoustic outcomes -- i.e., articulatory-acoustic relation -- is of great importance in assessing speech quality and developing innovative treatment and rehabilitative strategies. This is especially important when evaluating and detecting abnormal articulatory features in patients with speech-related disorders. In this work, we aim to develop a framework for detecting speech motion anomalies in conjunction with their corresponding speech acoustics. This is achieved through the use of a deep cross-modal translator trained on data from healthy individuals only, which bridges the gap between 4D motion fields obtained from tagged MRI and 2D spectrograms derived from speech acoustic data. The trained translator is used as an anomaly detector, by measuring the spectrogram reconstruction quality on healthy individuals or patients. In particular, the cross-modal translator is likely to yield limited generalization capabilities on patient data, which includes unseen out-of-distribution patterns and demonstrates subpar performance, when compared with healthy individuals.~A one-class SVM is then used to distinguish the spectrograms of healthy individuals from those of patients. To validate our framework, we collected a total of 39 paired tagged MRI and speech waveforms, consisting of data from 36 healthy individuals and 3 tongue cancer patients. We used both 3D convolutional and transformer-based deep translation models, training them on the healthy training set and then applying them to both the healthy and patient testing sets. Our framework demonstrates a capability to detect abnormal patient data, thereby illustrating its potential in enhancing the understanding of the articulatory-acoustic relation for both healthy individuals and patients.
Disentangled Multimodal Brain MR Image Translation via Transformer-based Modality Infuser
Feb 01, 2024Multimodal Magnetic Resonance (MR) Imaging plays a crucial role in disease diagnosis due to its ability to provide complementary information by analyzing a relationship between multimodal images on the same subject. Acquiring all MR modalities, however, can be expensive, and, during a scanning session, certain MR images may be missed depending on the study protocol. The typical solution would be to synthesize the missing modalities from the acquired images such as using generative adversarial networks (GANs). Yet, GANs constructed with convolutional neural networks (CNNs) are likely to suffer from a lack of global relationships and mechanisms to condition the desired modality. To address this, in this work, we propose a transformer-based modality infuser designed to synthesize multimodal brain MR images. In our method, we extract modality-agnostic features from the encoder and then transform them into modality-specific features using the modality infuser. Furthermore, the modality infuser captures long-range relationships among all brain structures, leading to the generation of more realistic images. We carried out experiments on the BraTS 2018 dataset, translating between four MR modalities, and our experimental results demonstrate the superiority of our proposed method in terms of synthesis quality. In addition, we conducted experiments on a brain tumor segmentation task and different conditioning methods.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023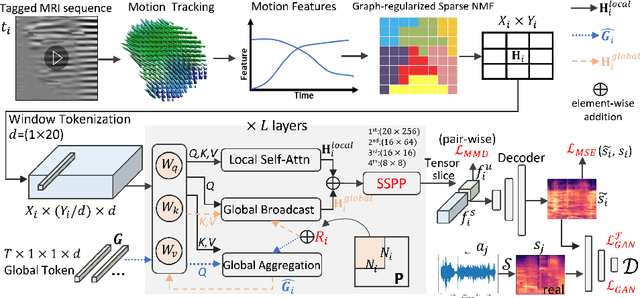
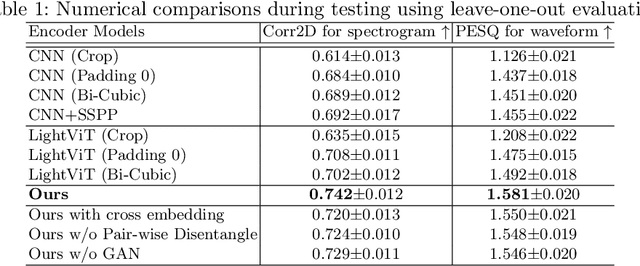
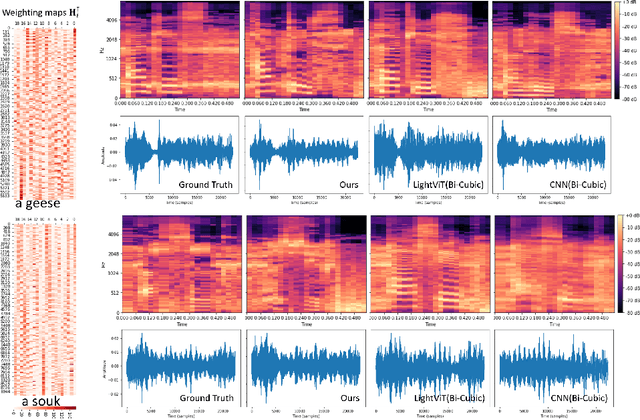
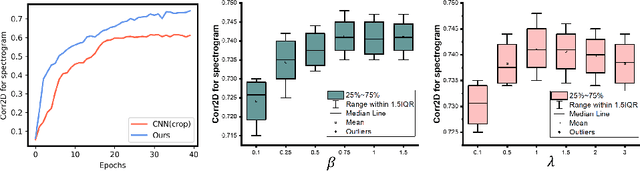
The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.