 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Conditioning Module to Control Pretrained Diffusion Models for 3D Medical Images
Oct 29, 2024


Spatial control methods using additional modules on pretrained diffusion models have gained attention for enabling conditional generation in natural images. These methods guide the generation process with new conditions while leveraging the capabilities of large models. They could be beneficial as training strategies in the context of 3D medical imaging, where training a diffusion model from scratch is challenging due to high computational costs and data scarcity. However, the potential application of spatial control methods with additional modules to 3D medical images has not yet been explored. In this paper, we present a tailored spatial control method for 3D medical images with a novel lightweight module, Volumetric Conditioning Module (VCM). Our VCM employs an asymmetric U-Net architecture to effectively encode complex information from various levels of 3D conditions, providing detailed guidance in image synthesis. To examine the applicability of spatial control methods and the effectiveness of VCM for 3D medical data, we conduct experiments under single- and multimodal conditions scenarios across a wide range of dataset sizes, from extremely small datasets with 10 samples to large datasets with 500 samples. The experimental results show that the VCM is effective for conditional generation and efficient in terms of requiring less training data and computational resources. We further investigate the potential applications for our spatial control method through axial super-resolution for medical images. Our code is available at \url{https://github.com/Ahn-Ssu/VCM}
Label-Efficient 3D Brain Segmentation via Complementary 2D Diffusion Models with Orthogonal Views
Jul 17, 2024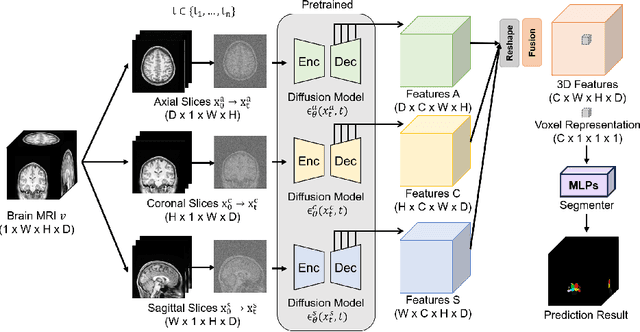
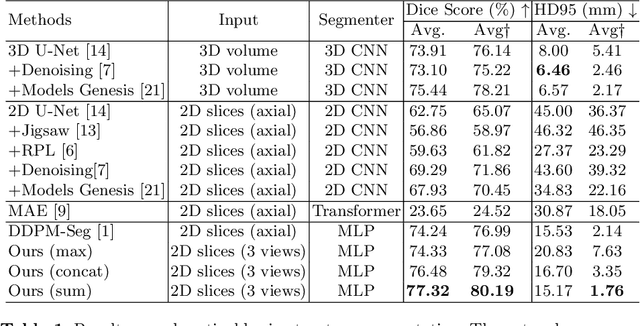
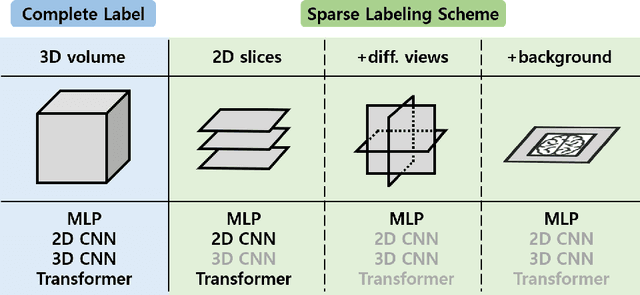
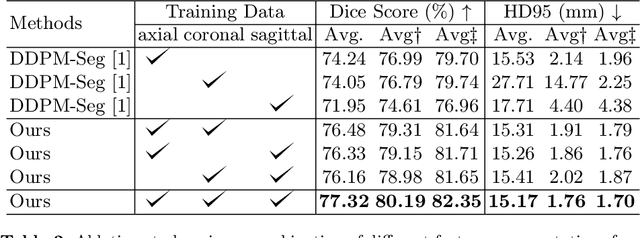
Deep learning-based segmentation techniques have shown remarkable performance in brain segmentation, yet their success hinges on the availability of extensive labeled training data. Acquiring such vast datasets, however, poses a significant challenge in many clinical applications. To address this issue, in this work, we propose a novel 3D brain segmentation approach using complementary 2D diffusion models. The core idea behind our approach is to first mine 2D features with semantic information extracted from the 2D diffusion models by taking orthogonal views as input, followed by fusing them into a 3D contextual feature representation. Then, we use these aggregated features to train multi-layer perceptrons to classify the segmentation labels. Our goal is to achieve reliable segmentation quality without requiring complete labels for each individual subject. Our experiments on training in brain subcortical structure segmentation with a dataset from only one subject demonstrate that our approach outperforms state-of-the-art self-supervised learning methods. Further experiments on the minimum requirement of annotation by sparse labeling yield promising results even with only nine slices and a labeled background region.