 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTab: A Comprehensive Benchmark Suite for Multi-Dimensional Evaluation in Tabular Domains
May 20, 2025Despite the widespread use of tabular data in real-world applications, most benchmarks rely on average-case metrics, which fail to reveal how model behavior varies across diverse data regimes. To address this, we propose MultiTab, a benchmark suite and evaluation framework for multi-dimensional, data-aware analysis of tabular learning algorithms. Rather than comparing models only in aggregate, MultiTab categorizes 196 publicly available datasets along key data characteristics, including sample size, label imbalance, and feature interaction, and evaluates 13 representative models spanning a range of inductive biases. Our analysis shows that model performance is highly sensitive to such regimes: for example, models using sample-level similarity excel on datasets with large sample sizes or high inter-feature correlation, while models encoding inter-feature dependencies perform best with weakly correlated features. These findings reveal that inductive biases do not always behave as intended, and that regime-aware evaluation is essential for understanding and improving model behavior. MultiTab enables more principled model design and offers practical guidance for selecting models tailored to specific data characteristics. All datasets, code, and optimization logs are publicly available at https://huggingface.co/datasets/LGAI-DILab/Multitab.
A Benchmark Suite for Evaluating Neural Mutual Information Estimators on Unstructured Datasets
Oct 14, 2024



Mutual Information (MI) is a fundamental metric for quantifying dependency between two random variables. When we can access only the samples, but not the underlying distribution functions, we can evaluate MI using sample-based estimators. Assessment of such MI estimators, however, has almost always relied on analytical datasets including Gaussian multivariates. Such datasets allow analytical calculations of the true MI values, but they are limited in that they do not reflect the complexities of real-world datasets. This study introduces a comprehensive benchmark suite for evaluating neural MI estimators on unstructured datasets, specifically focusing on images and texts. By leveraging same-class sampling for positive pairing and introducing a binary symmetric channel trick, we show that we can accurately manipulate true MI values of real-world datasets. Using the benchmark suite, we investigate seven challenging scenarios, shedding light on the reliability of neural MI estimators for unstructured datasets.
Diffusion based Semantic Outlier Generation via Nuisance Awareness for Out-of-Distribution Detection
Aug 27, 2024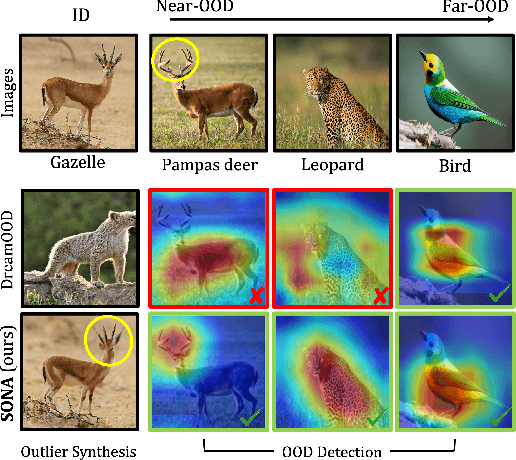
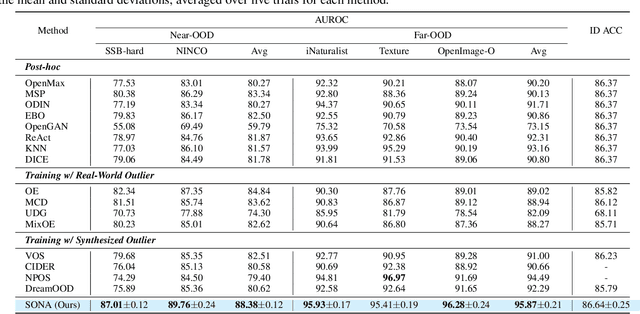
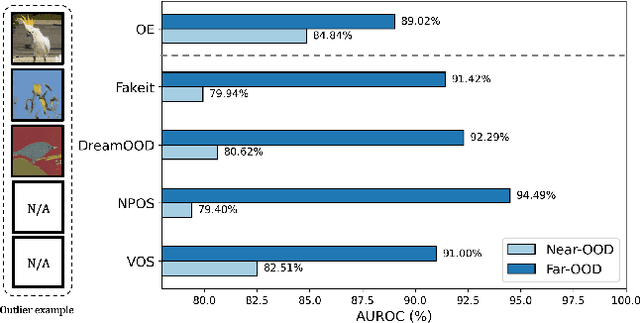
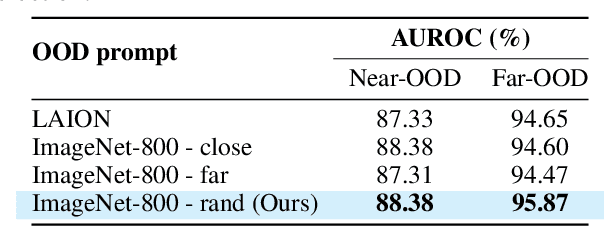
Out-of-distribution (OOD) detection, which determines whether a given sample is part of the in-distribution (ID), has recently shown promising results through training with synthetic OOD datasets. Nonetheless, existing methods often produce outliers that are considerably distant from the ID, showing limited efficacy for capturing subtle distinctions between ID and OOD. To address these issues, we propose a novel framework, Semantic Outlier generation via Nuisance Awareness (SONA), which notably produces challenging outliers by directly leveraging pixel-space ID samples through diffusion models. Our approach incorporates SONA guidance, providing separate control over semantic and nuisance regions of ID samples. Thereby, the generated outliers achieve two crucial properties: (i) they present explicit semantic-discrepant information, while (ii) maintaining various levels of nuisance resemblance with ID. Furthermore, the improved OOD detector training with SONA outliers facilitates learning with a focus on semantic distinctions. Extensive experiments demonstrate the effectiveness of our framework, achieving an impressive AUROC of 88% on near-OOD datasets, which surpasses the performance of baseline methods by a significant margin of approximately 6%.
Label-Efficient 3D Brain Segmentation via Complementary 2D Diffusion Models with Orthogonal Views
Jul 17, 2024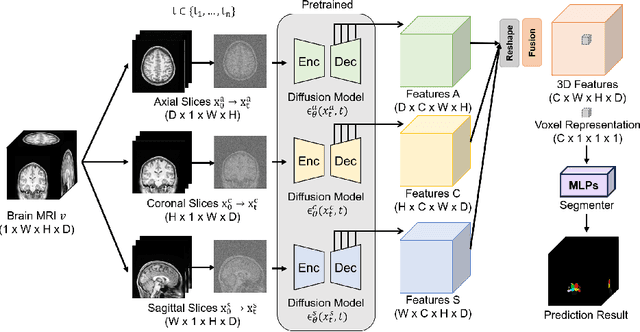
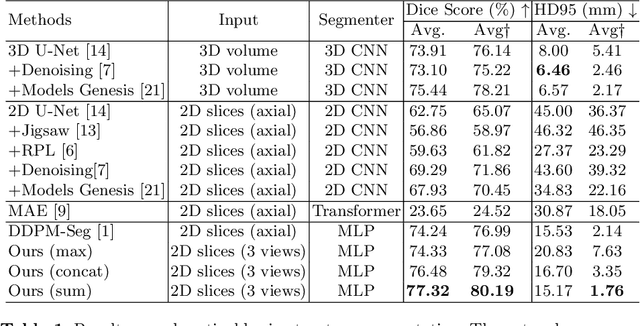
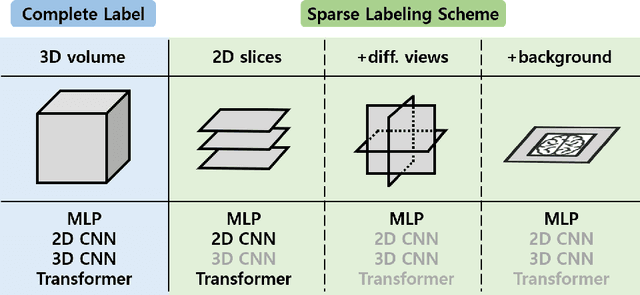
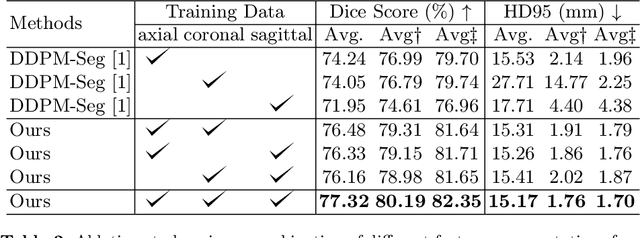
Deep learning-based segmentation techniques have shown remarkable performance in brain segmentation, yet their success hinges on the availability of extensive labeled training data. Acquiring such vast datasets, however, poses a significant challenge in many clinical applications. To address this issue, in this work, we propose a novel 3D brain segmentation approach using complementary 2D diffusion models. The core idea behind our approach is to first mine 2D features with semantic information extracted from the 2D diffusion models by taking orthogonal views as input, followed by fusing them into a 3D contextual feature representation. Then, we use these aggregated features to train multi-layer perceptrons to classify the segmentation labels. Our goal is to achieve reliable segmentation quality without requiring complete labels for each individual subject. Our experiments on training in brain subcortical structure segmentation with a dataset from only one subject demonstrate that our approach outperforms state-of-the-art self-supervised learning methods. Further experiments on the minimum requirement of annotation by sparse labeling yield promising results even with only nine slices and a labeled background region.
Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains
May 14, 2024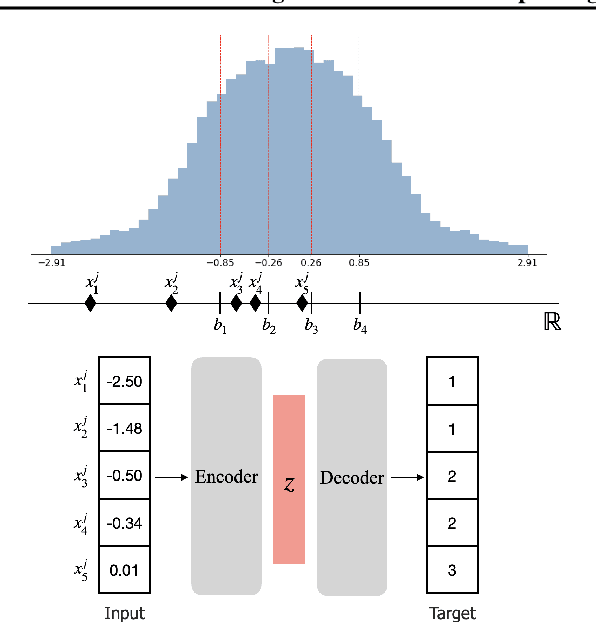
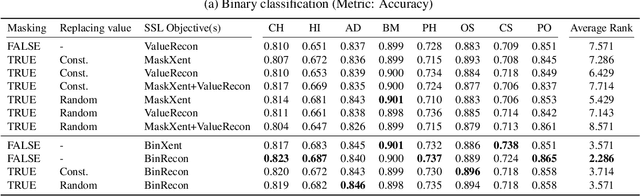
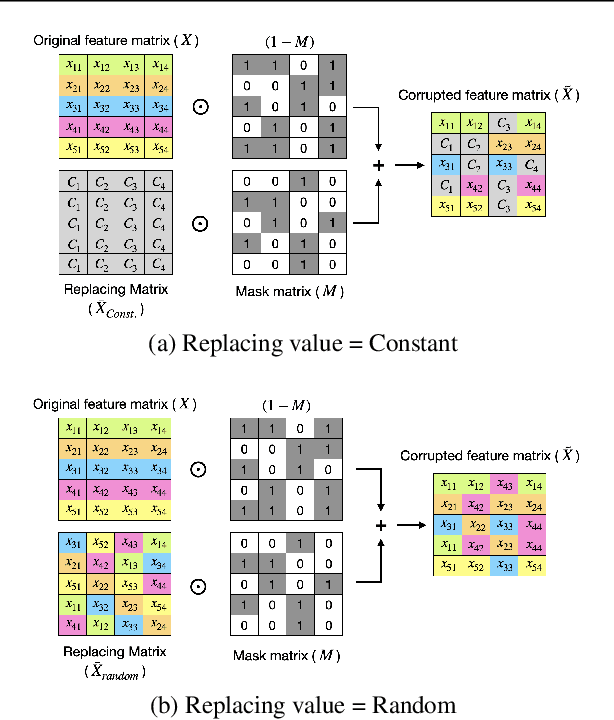
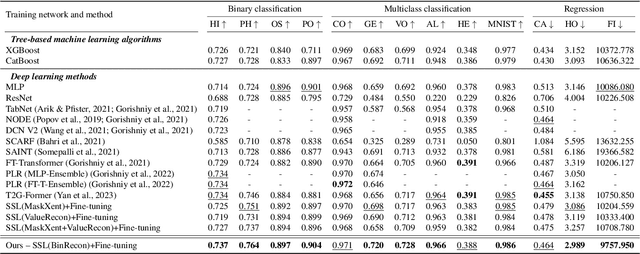
The ability of deep networks to learn superior representations hinges on leveraging the proper inductive biases, considering the inherent properties of datasets. In tabular domains, it is critical to effectively handle heterogeneous features (both categorical and numerical) in a unified manner and to grasp irregular functions like piecewise constant functions. To address the challenges in the self-supervised learning framework, we propose a novel pretext task based on the classical binning method. The idea is straightforward: reconstructing the bin indices (either orders or classes) rather than the original values. This pretext task provides the encoder with an inductive bias to capture the irregular dependencies, mapping from continuous inputs to discretized bins, and mitigates the feature heterogeneity by setting all features to have category-type targets. Our empirical investigations ascertain several advantages of binning: capturing the irregular function, compatibility with encoder architecture and additional modifications, standardizing all features into equal sets, grouping similar values within a feature, and providing ordering information. Comprehensive evaluations across diverse tabular datasets corroborate that our method consistently improves tabular representation learning performance for a wide range of downstream tasks. The codes are available in https://github.com/kyungeun-lee/tabularbinning.
Towards a Rigorous Analysis of Mutual Information in Contrastive Learning
Aug 30, 2023



Contrastive learning has emerged as a cornerstone in recent achievements of unsupervised representation learning. Its primary paradigm involves an instance discrimination task with a mutual information loss. The loss is known as InfoNCE and it has yielded vital insights into contrastive learning through the lens of mutual information analysis. However, the estimation of mutual information can prove challenging, creating a gap between the elegance of its mathematical foundation and the complexity of its estimation. As a result, drawing rigorous insights or conclusions from mutual information analysis becomes intricate. In this study, we introduce three novel methods and a few related theorems, aimed at enhancing the rigor of mutual information analysis. Despite their simplicity, these methods can carry substantial utility. Leveraging these approaches, we reassess three instances of contrastive learning analysis, illustrating their capacity to facilitate deeper comprehension or to rectify pre-existing misconceptions. Specifically, we investigate small batch size, mutual information as a measure, and the InfoMin principle.
DR.CPO: Diversified and Realistic 3D Augmentation via Iterative Construction, Random Placement, and HPR Occlusion
Mar 20, 2023



In autonomous driving, data augmentation is commonly used for improving 3D object detection. The most basic methods include insertion of copied objects and rotation and scaling of the entire training frame. Numerous variants have been developed as well. The existing methods, however, are considerably limited when compared to the variety of the real world possibilities. In this work, we develop a diversified and realistic augmentation method that can flexibly construct a whole-body object, freely locate and rotate the object, and apply self-occlusion and external-occlusion accordingly. To improve the diversity of the whole-body object construction, we develop an iterative method that stochastically combines multiple objects observed from the real world into a single object. Unlike the existing augmentation methods, the constructed objects can be randomly located and rotated in the training frame because proper occlusions can be reflected to the whole-body objects in the final step. Finally, proper self-occlusion at each local object level and external-occlusion at the global frame level are applied using the Hidden Point Removal (HPR) algorithm that is computationally efficient. HPR is also used for adaptively controlling the point density of each object according to the object's distance from the LiDAR. Experiment results show that the proposed DR.CPO algorithm is data-efficient and model-agnostic without incurring any computational overhead. Also, DR.CPO can improve mAP performance by 2.08% when compared to the best 3D detection result known for KITTI dataset. The code is available at https://github.com/SNU-DRL/DRCPO.git
Short-term Traffic Prediction with Deep Neural Networks: A Survey
Aug 28, 2020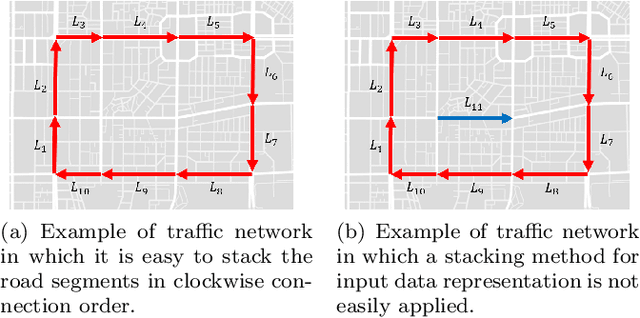
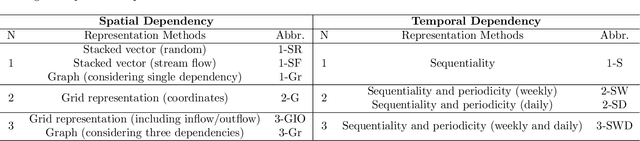
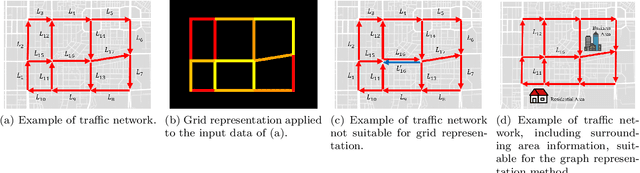
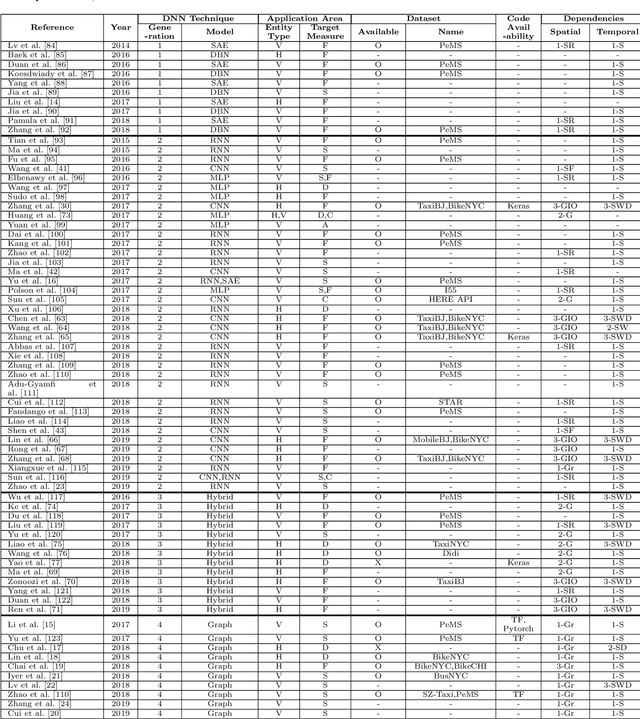
In modern transportation systems, an enormous amount of traffic data is generated every day. This has led to rapid progress in short-term traffic prediction (STTP), in which deep learning methods have recently been applied. In traffic networks with complex spatiotemporal relationships, deep neural networks (DNNs) often perform well because they are capable of automatically extracting the most important features and patterns. In this study, we survey recent STTP studies applying deep networks from four perspectives. 1) We summarize input data representation methods according to the number and type of spatial and temporal dependencies involved. 2) We briefly explain a wide range of DNN techniques from the earliest networks, including Restricted Boltzmann Machines, to the most recent, including graph-based and meta-learning networks. 3) We summarize previous STTP studies in terms of the type of DNN techniques, application area, dataset and code availability, and the type of the represented spatiotemporal dependencies. 4) We compile public traffic datasets that are popular and can be used as the standard benchmarks. Finally, we suggest challenging issues and possible future research directions in STTP.
Graph Convolutional Modules for Traffic Forecasting
May 29, 2019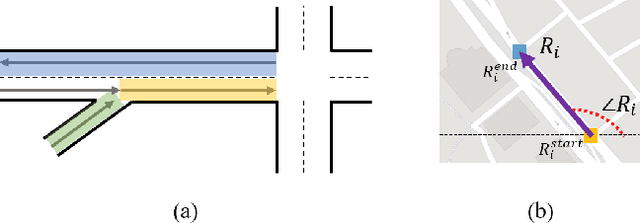
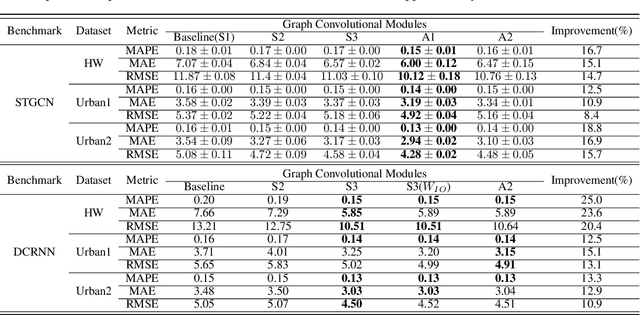
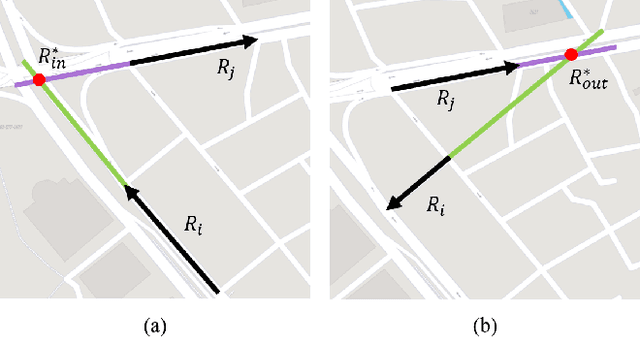
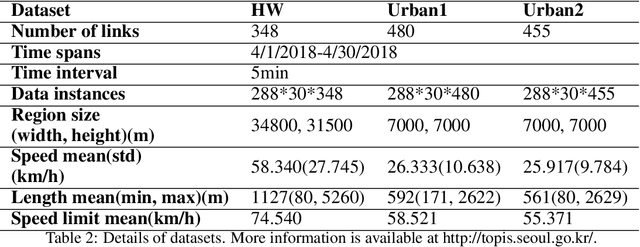
Graph convolutional network is a generalization of convolutional network for learning graph-structured data. In some of the recent works on traffic networks, a few graph convolutional blocks have been designed and shown to be useful. In this work, we extend the ideas and provide a systematic way of creating graph convolutional modules. The method consists of designing basic weighted adjacency matrices as the smallest building blocks, defining partition functions that can partition a weighted adjacency matrix into M matrices that can also serve as building blocks, and finally designing graph convolutional modules using the building blocks. We evaluate some of the designed modules by replacing the graph convolutional parts in STGCN and DCRNN, and find 8.4% to 25.0% reduction in speed estimation error.
On the Statistical and Information-theoretic Characteristics of Deep Network Representations
Nov 08, 2018
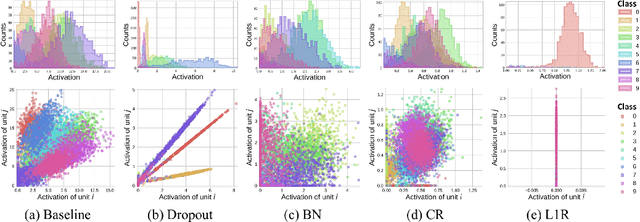
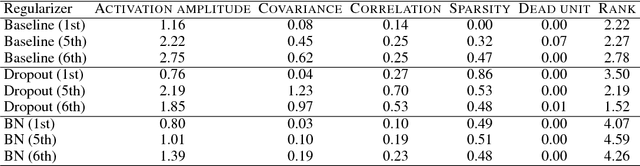
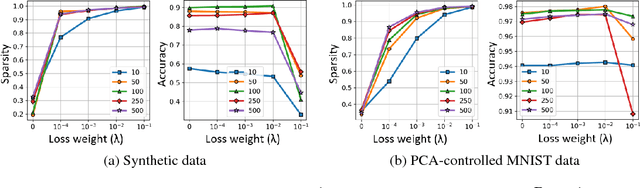
It has been common to argue or imply that a regularizer can be used to alter a statistical property of a hidden layer's representation and thus improve generalization or performance of deep networks. For instance, dropout has been known to improve performance by reducing co-adaptation, and representational sparsity has been argued as a good characteristic because many data-generation processes have a small number of factors that are independent. In this work, we analytically and empirically investigate the popular characteristics of learned representations, including correlation, sparsity, dead unit, rank, and mutual information, and disprove many of the \textit{conventional wisdom}. We first show that infinitely many Identical Output Networks (IONs) can be constructed for any deep network with a linear layer, where any invertible affine transformation can be applied to alter the layer's representation characteristics. The existence of ION proves that the correlation characteristics of representation is irrelevant to the performance. Extensions to ReLU layers are provided, too. Then, we consider sparsity, dead unit, and rank to show that only loose relationships exist among the three characteristics. It is shown that a higher sparsity or additional dead units do not imply a better or worse performance when the rank of representation is fixed. We also develop a rank regularizer and show that neither representation sparsity nor lower rank is helpful for improving performance even when the data-generation process has a small number of independent factors. Mutual information $I(\mathbf{z}_l;\mathbf{x})$ and $I(\mathbf{z}_l;\mathbf{y})$ are investigated, and we show that regularizers can affect $I(\mathbf{z}_l;\mathbf{x})$ and thus indirectly influence the performance. Finally, we explain how a rich set of regularizers can be used as a powerful tool for performance tuning.