 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Align While Search: Belief-Guided Exploratory Inference for World-Grounded Embodied Agents
Dec 30, 2025In this paper, we propose a test-time adaptive agent that performs exploratory inference through posterior-guided belief refinement without relying on gradient-based updates or additional training for LLM agent operating under partial observability. Our agent maintains an external structured belief over the environment state, iteratively updates it via action-conditioned observations, and selects actions by maximizing predicted information gain over the belief space. We estimate information gain using a lightweight LLM-based surrogate and assess world alignment through a novel reward that quantifies the consistency between posterior belief and ground-truth environment configuration. Experiments show that our method outperforms inference-time scaling baselines such as prompt-augmented or retrieval-enhanced LLMs, in aligning with latent world states with significantly lower integration overhead.
ARC: Leveraging Compositional Representations for Cross-Problem Learning on VRPs
Dec 21, 2025Vehicle Routing Problems (VRPs) with diverse real-world attributes have driven recent interest in cross-problem learning approaches that efficiently generalize across problem variants. We propose ARC (Attribute Representation via Compositional Learning), a cross-problem learning framework that learns disentangled attribute representations by decomposing them into two complementary components: an Intrinsic Attribute Embedding (IAE) for invariant attribute semantics and a Contextual Interaction Embedding (CIE) for attribute-combination effects. This disentanglement is achieved by enforcing analogical consistency in the embedding space to ensure the semantic transformation of adding an attribute (e.g., a length constraint) remains invariant across different problem contexts. This enables our model to reuse invariant semantics across trained variants and construct representations for unseen combinations. ARC achieves state-of-the-art performance across in-distribution, zero-shot generalization, few-shot adaptation, and real-world benchmarks.
ReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
Oct 02, 2025In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domain-specific context. However, existing benchmarks provide only raw data points without semantic context, overlooking rich textual metadata such as feature descriptions and domain knowledge that experts rely on in practice. This limitation restricts research flexibility and prevents models from fully leveraging domain knowledge for detection. ReTabAD addresses this gap by restoring textual semantics to enable context-aware tabular AD research. We provide (1) 20 carefully curated tabular datasets enriched with structured textual metadata, together with implementations of state-of-the-art AD algorithms including classical, deep learning, and LLM-based approaches, and (2) a zero-shot LLM framework that leverages semantic context without task-specific training, establishing a strong baseline for future research. Furthermore, this work provides insights into the role and utility of textual metadata in AD through experiments and analysis. Results show that semantic context improves detection performance and enhances interpretability by supporting domain-aware reasoning. These findings establish ReTabAD as a benchmark for systematic exploration of context-aware AD.
THEME : Enhancing Thematic Investing with Semantic Stock Representations and Temporal Dynamics
Aug 23, 2025Thematic investing aims to construct portfolios aligned with structural trends, yet selecting relevant stocks remains challenging due to overlapping sector boundaries and evolving market dynamics. To address this challenge, we construct the Thematic Representation Set (TRS), an extended dataset that begins with real-world thematic ETFs and expands upon them by incorporating industry classifications and financial news to overcome their coverage limitations. The final dataset contains both the explicit mapping of themes to their constituent stocks and the rich textual profiles for each. Building on this dataset, we introduce \textsc{THEME}, a hierarchical contrastive learning framework. By representing the textual profiles of themes and stocks as embeddings, \textsc{THEME} first leverages their hierarchical relationship to achieve semantic alignment. Subsequently, it refines these semantic embeddings through a temporal refinement stage that incorporates individual stock returns. The final stock representations are designed for effective retrieval of thematically aligned assets with strong return potential. Empirical results show that \textsc{THEME} outperforms strong baselines across multiple retrieval metrics and significantly improves performance in portfolio construction. By jointly modeling thematic relationships from text and market dynamics from returns, \textsc{THEME} provides a scalable and adaptive solution for navigating complex investment themes.
MultiTab: A Comprehensive Benchmark Suite for Multi-Dimensional Evaluation in Tabular Domains
May 20, 2025Despite the widespread use of tabular data in real-world applications, most benchmarks rely on average-case metrics, which fail to reveal how model behavior varies across diverse data regimes. To address this, we propose MultiTab, a benchmark suite and evaluation framework for multi-dimensional, data-aware analysis of tabular learning algorithms. Rather than comparing models only in aggregate, MultiTab categorizes 196 publicly available datasets along key data characteristics, including sample size, label imbalance, and feature interaction, and evaluates 13 representative models spanning a range of inductive biases. Our analysis shows that model performance is highly sensitive to such regimes: for example, models using sample-level similarity excel on datasets with large sample sizes or high inter-feature correlation, while models encoding inter-feature dependencies perform best with weakly correlated features. These findings reveal that inductive biases do not always behave as intended, and that regime-aware evaluation is essential for understanding and improving model behavior. MultiTab enables more principled model design and offers practical guidance for selecting models tailored to specific data characteristics. All datasets, code, and optimization logs are publicly available at https://huggingface.co/datasets/LGAI-DILab/Multitab.
MolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition
Dec 21, 2024



Vision Transformers (ViTs) have achieved remarkable success in various computer vision tasks. However, ViTs have a huge computational cost due to their inherent reliance on multi-head self-attention (MHSA), prompting efforts to accelerate ViTs for practical applications. To this end, recent works aim to reduce the number of tokens, mainly focusing on how to effectively prune or merge them. Nevertheless, since ViT tokens are generated from non-overlapping grid patches, they usually do not convey sufficient semantics, making it incompatible with efficient ViTs. To address this, we propose ImagePiece, a novel re-tokenization strategy for Vision Transformers. Following the MaxMatch strategy of NLP tokenization, ImagePiece groups semantically insufficient yet locally coherent tokens until they convey meaning. This simple retokenization is highly compatible with previous token reduction methods, being able to drastically narrow down relevant tokens, enhancing the inference speed of DeiT-S by 54% (nearly 1.5$\times$ faster) while achieving a 0.39% improvement in ImageNet classification accuracy. For hyper-speed inference scenarios (with 251% acceleration), our approach surpasses other baselines by an accuracy over 8%.
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
Dec 09, 2024



This technical report introduces the EXAONE 3.5 instruction-tuned language models, developed and released by LG AI Research. The EXAONE 3.5 language models are offered in three configurations: 32B, 7.8B, and 2.4B. These models feature several standout capabilities: 1) exceptional instruction following capabilities in real-world scenarios, achieving the highest scores across seven benchmarks, 2) outstanding long-context comprehension, attaining the top performance in four benchmarks, and 3) competitive results compared to state-of-the-art open models of similar sizes across nine general benchmarks. The EXAONE 3.5 language models are open to anyone for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE. For commercial use, please reach out to the official contact point of LG AI Research: contact_us@lgresearch.ai.
Diffusion based Semantic Outlier Generation via Nuisance Awareness for Out-of-Distribution Detection
Aug 27, 2024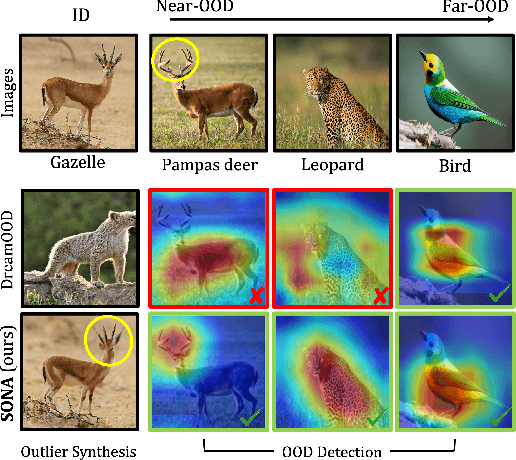
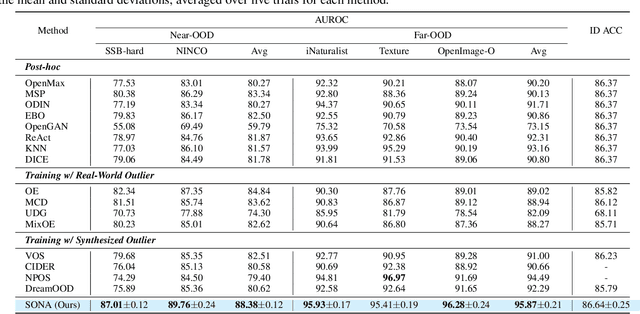
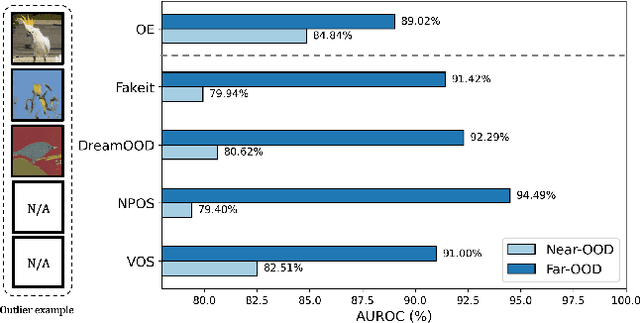
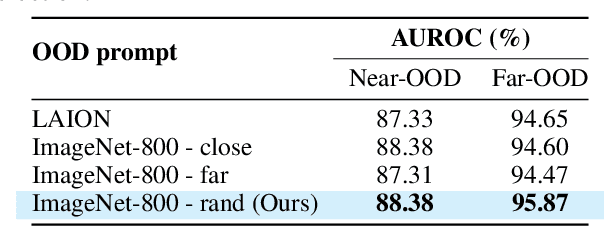
Out-of-distribution (OOD) detection, which determines whether a given sample is part of the in-distribution (ID), has recently shown promising results through training with synthetic OOD datasets. Nonetheless, existing methods often produce outliers that are considerably distant from the ID, showing limited efficacy for capturing subtle distinctions between ID and OOD. To address these issues, we propose a novel framework, Semantic Outlier generation via Nuisance Awareness (SONA), which notably produces challenging outliers by directly leveraging pixel-space ID samples through diffusion models. Our approach incorporates SONA guidance, providing separate control over semantic and nuisance regions of ID samples. Thereby, the generated outliers achieve two crucial properties: (i) they present explicit semantic-discrepant information, while (ii) maintaining various levels of nuisance resemblance with ID. Furthermore, the improved OOD detector training with SONA outliers facilitates learning with a focus on semantic distinctions. Extensive experiments demonstrate the effectiveness of our framework, achieving an impressive AUROC of 88% on near-OOD datasets, which surpasses the performance of baseline methods by a significant margin of approximately 6%.