 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Retrieval for Multivariate Time Series Forecasting
Apr 07, 2026Multivariate time series forecasting often struggles to capture long-range dependencies due to fixed lookback windows. Retrieval-augmented forecasting addresses this by retrieving historical segments from memory, but existing approaches rely on a channel-agnostic strategy that applies the same references to all variables. This neglects inter-variable heterogeneity, where different channels exhibit distinct periodicities and spectral profiles. We propose CRAFT (Channel-wise retrieval-augmented forecasting), a novel framework that performs retrieval independently for each channel. To ensure efficiency, CRAFT adopts a two-stage pipeline: a sparse relation graph constructed in the time domain prunes irrelevant candidates, and spectral similarity in the frequency domain ranks references, emphasizing dominant periodic components while suppressing noise. Experiments on seven public benchmarks demonstrate that CRAFT outperforms state-of-the-art forecasting baselines, achieving superior accuracy with practical inference efficiency.
Adaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
Can We Utilize Pre-trained Language Models within Causal Discovery Algorithms?
Nov 19, 2023Scaling laws have allowed Pre-trained Language Models (PLMs) into the field of causal reasoning. Causal reasoning of PLM relies solely on text-based descriptions, in contrast to causal discovery which aims to determine the causal relationships between variables utilizing data. Recently, there has been current research regarding a method that mimics causal discovery by aggregating the outcomes of repetitive causal reasoning, achieved through specifically designed prompts. It highlights the usefulness of PLMs in discovering cause and effect, which is often limited by a lack of data, especially when dealing with multiple variables. Conversely, the characteristics of PLMs which are that PLMs do not analyze data and they are highly dependent on prompt design leads to a crucial limitation for directly using PLMs in causal discovery. Accordingly, PLM-based causal reasoning deeply depends on the prompt design and carries out the risk of overconfidence and false predictions in determining causal relationships. In this paper, we empirically demonstrate the aforementioned limitations of PLM-based causal reasoning through experiments on physics-inspired synthetic data. Then, we propose a new framework that integrates prior knowledge obtained from PLM with a causal discovery algorithm. This is accomplished by initializing an adjacency matrix for causal discovery and incorporating regularization using prior knowledge. Our proposed framework not only demonstrates improved performance through the integration of PLM and causal discovery but also suggests how to leverage PLM-extracted prior knowledge with existing causal discovery algorithms.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022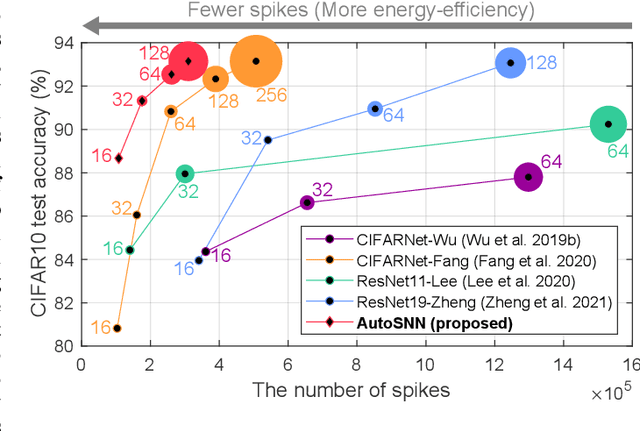
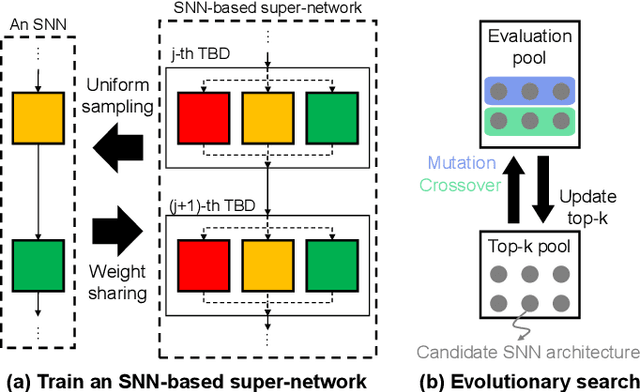
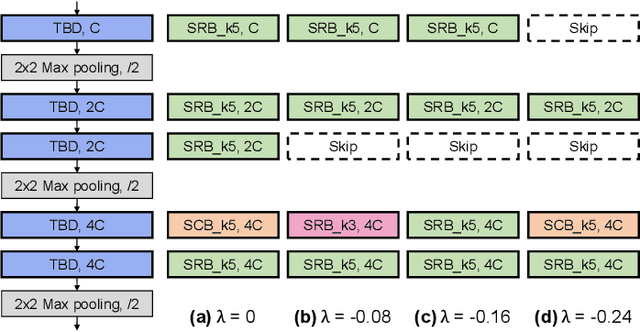
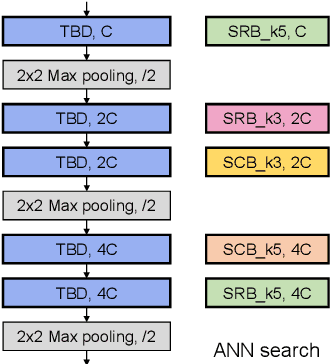
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
AdvRush: Searching for Adversarially Robust Neural Architectures
Aug 10, 2021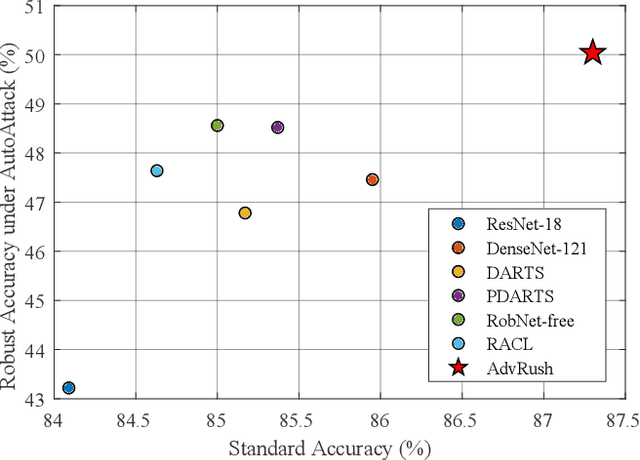
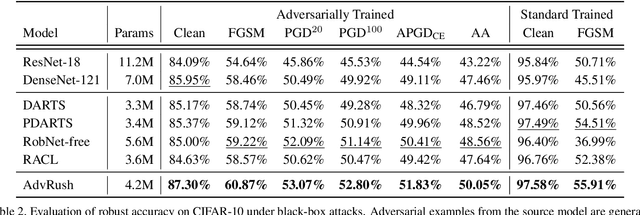
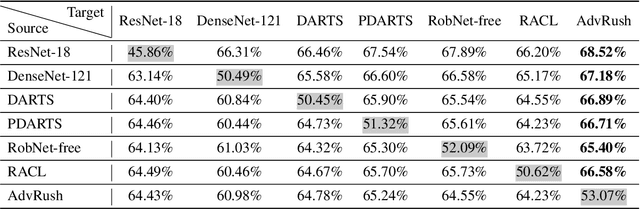
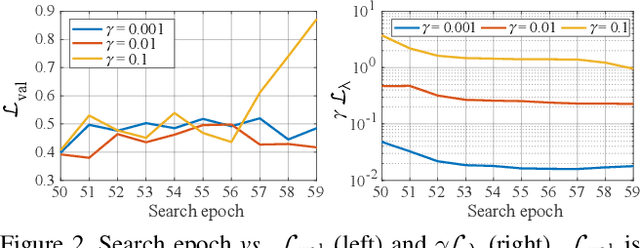
Deep neural networks continue to awe the world with their remarkable performance. Their predictions, however, are prone to be corrupted by adversarial examples that are imperceptible to humans. Current efforts to improve the robustness of neural networks against adversarial examples are focused on developing robust training methods, which update the weights of a neural network in a more robust direction. In this work, we take a step beyond training of the weight parameters and consider the problem of designing an adversarially robust neural architecture with high intrinsic robustness. We propose AdvRush, a novel adversarial robustness-aware neural architecture search algorithm, based upon a finding that independent of the training method, the intrinsic robustness of a neural network can be represented with the smoothness of its input loss landscape. Through a regularizer that favors a candidate architecture with a smoother input loss landscape, AdvRush successfully discovers an adversarially robust neural architecture. Along with a comprehensive theoretical motivation for AdvRush, we conduct an extensive amount of experiments to demonstrate the efficacy of AdvRush on various benchmark datasets. Notably, on CIFAR-10, AdvRush achieves 55.91% robust accuracy under FGSM attack after standard training and 50.04% robust accuracy under AutoAttack after 7-step PGD adversarial training.
Accelerating Neural Architecture Search via Proxy Data
Jun 09, 2021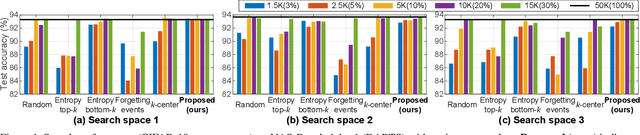
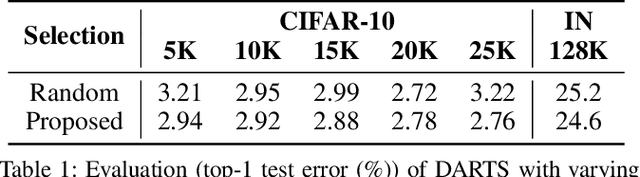

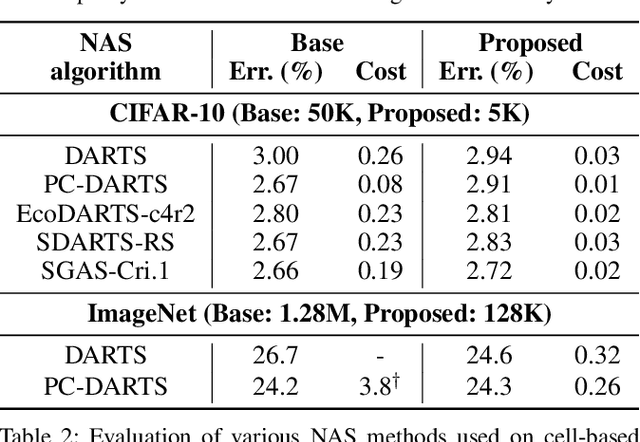
Despite the increasing interest in neural architecture search (NAS), the significant computational cost of NAS is a hindrance to researchers. Hence, we propose to reduce the cost of NAS using proxy data, i.e., a representative subset of the target data, without sacrificing search performance. Even though data selection has been used across various fields, our evaluation of existing selection methods for NAS algorithms offered by NAS-Bench-1shot1 reveals that they are not always appropriate for NAS and a new selection method is necessary. By analyzing proxy data constructed using various selection methods through data entropy, we propose a novel proxy data selection method tailored for NAS. To empirically demonstrate the effectiveness, we conduct thorough experiments across diverse datasets, search spaces, and NAS algorithms. Consequently, NAS algorithms with the proposed selection discover architectures that are competitive with those obtained using the entire dataset. It significantly reduces the search cost: executing DARTS with the proposed selection requires only 40 minutes on CIFAR-10 and 7.5 hours on ImageNet with a single GPU. Additionally, when the architecture searched on ImageNet using the proposed selection is inversely transferred to CIFAR-10, a state-of-the-art test error of 2.4\% is yielded. Our code is available at https://github.com/nabk89/NAS-with-Proxy-data.
Fast and Efficient Information Transmission with Burst Spikes in Deep Spiking Neural Networks
Sep 10, 2018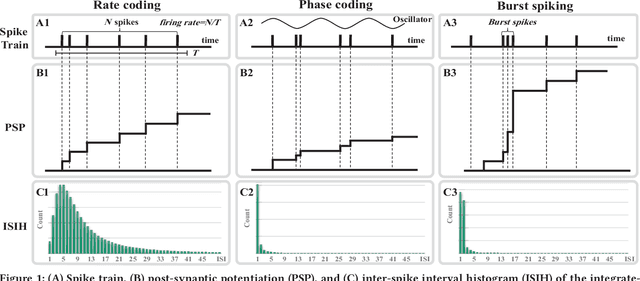
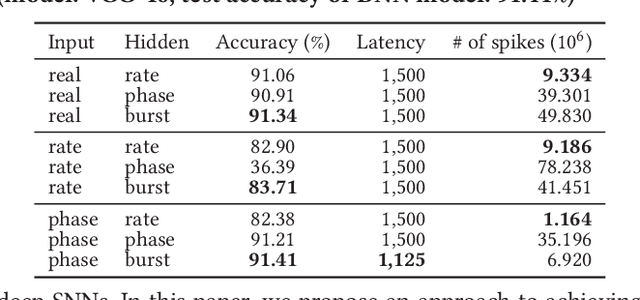
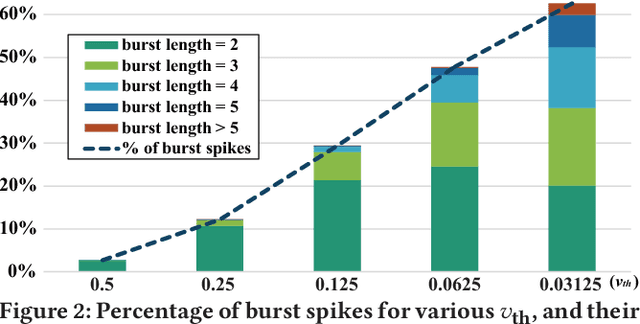
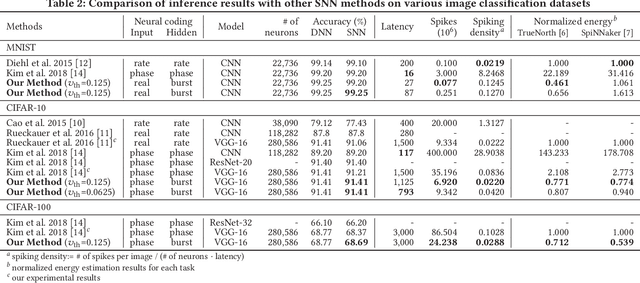
The spiking neural networks (SNNs), the 3rd generation of neural networks, are considered as one of the most promising artificial neural networks due to their energy-efficient computing capability. Despite their potential, the SNNs have a limited applicability owing to difficulties in training. Recently, conversion of a trained deep neural network (DNN) model to an SNN model has been extensively studied as an alternative approach. The result appears to be comparable to that of the DNN in image classification tasks. However, rate coding, one of the techniques used in modeling the SNNs, suffers from long latency due to its inability to transmit sufficient information to a subsequent neuron and this could have a catastrophic effect on a deeper SNN model. Another type of neural coding, called phase coding, also determines the amount of information being transmitted according to a global reference oscillator, and therefore, is inefficient in hidden layers where dynamics of neurons can change. In this paper, we propose a deep SNN model that can transmit information faster, and more efficiently between neurons by adopting a notion of burst spiking. Furthermore, we introduce a novel hybrid neural coding scheme that uses different neural coding schemes for different types of layers. Our experimental results for various image classification datasets, such as MNIST, CIFAR-10 and CIFAR-100, showed that the proposed methods can improve inference efficiency and shorten the latency while preserving high accuracy. Lastly, we validated the proposed methods through firing pattern analysis.
Near-Data Processing for Differentiable Machine Learning Models
Apr 28, 2017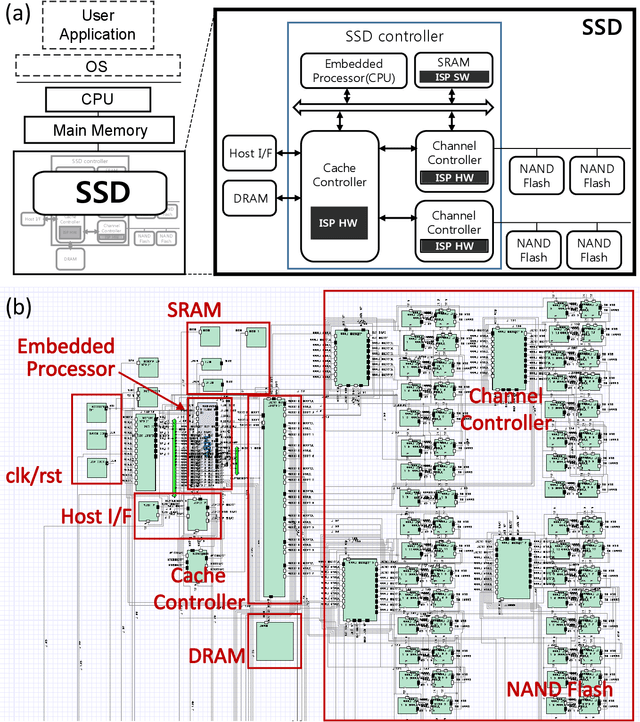

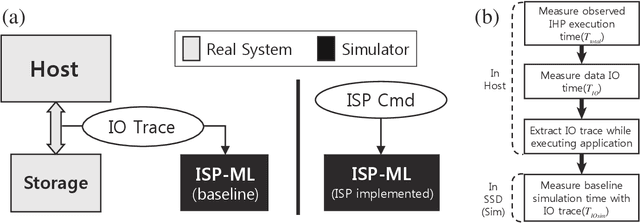
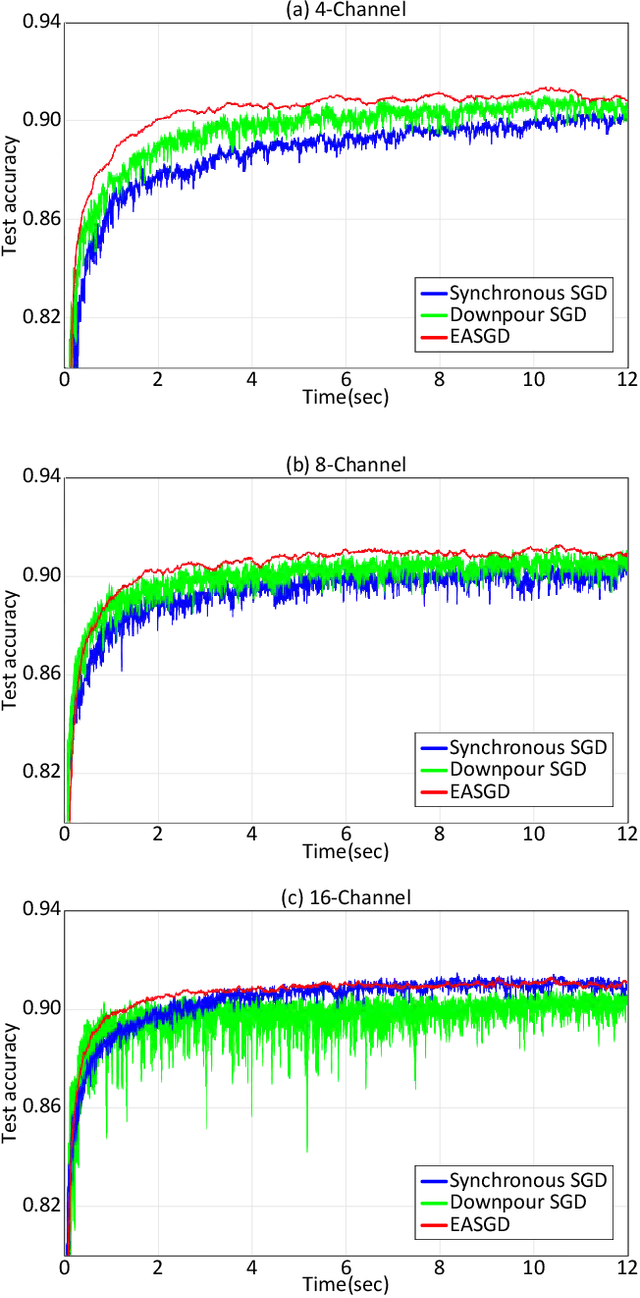
Near-data processing (NDP) refers to augmenting memory or storage with processing power. Despite its potential for acceleration computing and reducing power requirements, only limited progress has been made in popularizing NDP for various reasons. Recently, two major changes have occurred that have ignited renewed interest and caused a resurgence of NDP. The first is the success of machine learning (ML), which often demands a great deal of computation for training, requiring frequent transfers of big data. The second is the popularity of NAND flash-based solid-state drives (SSDs) containing multicore processors that can accommodate extra computation for data processing. In this paper, we evaluate the potential of NDP for ML using a new SSD platform that allows us to simulate instorage processing (ISP) of ML workloads. Our platform (named ISP-ML) is a full-fledged simulator of a realistic multi-channel SSD that can execute various ML algorithms using data stored in the SSD. To conduct a thorough performance analysis and an in-depth comparison with alternative techniques, we focus on a specific algorithm: stochastic gradient descent (SGD), which is the de facto standard for training differentiable models such as logistic regression and neural networks. We implement and compare three SGD variants (synchronous, Downpour, and elastic averaging) using ISP-ML, exploiting the multiple NAND channels to parallelize SGD. In addition, we compare the performance of ISP and that of conventional in-host processing, revealing the advantages of ISP. Based on the advantages and limitations identified through our experiments, we further discuss directions for future research on ISP for accelerating ML.