 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Memory-Augmented Neural Networks
Nov 10, 2017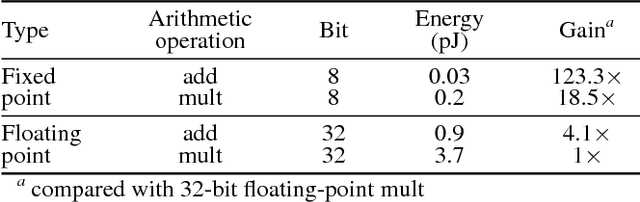

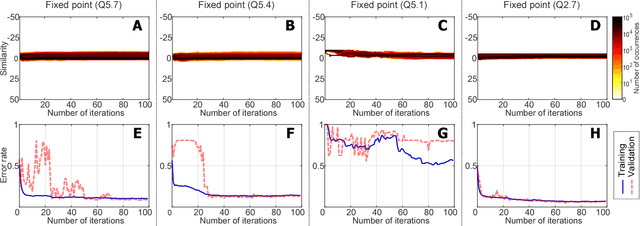
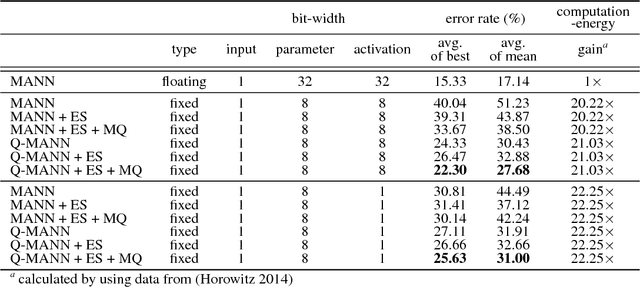
Memory-augmented neural networks (MANNs) refer to a class of neural network models equipped with external memory (such as neural Turing machines and memory networks). These neural networks outperform conventional recurrent neural networks (RNNs) in terms of learning long-term dependency, allowing them to solve intriguing AI tasks that would otherwise be hard to address. This paper concerns the problem of quantizing MANNs. Quantization is known to be effective when we deploy deep models on embedded systems with limited resources. Furthermore, quantization can substantially reduce the energy consumption of the inference procedure. These benefits justify recent developments of quantized multi layer perceptrons, convolutional networks, and RNNs. However, no prior work has reported the successful quantization of MANNs. The in-depth analysis presented here reveals various challenges that do not appear in the quantization of the other networks. Without addressing them properly, quantized MANNs would normally suffer from excessive quantization error which leads to degraded performance. In this paper, we identify memory addressing (specifically, content-based addressing) as the main reason for the performance degradation and propose a robust quantization method for MANNs to address the challenge. In our experiments, we achieved a computation-energy gain of 22x with 8-bit fixed-point and binary quantization compared to the floating-point implementation. Measured on the bAbI dataset, the resulting model, named the quantized MANN (Q-MANN), improved the error rate by 46% and 30% with 8-bit fixed-point and binary quantization, respectively, compared to the MANN quantized using conventional techniques.
Near-Data Processing for Differentiable Machine Learning Models
Apr 28, 2017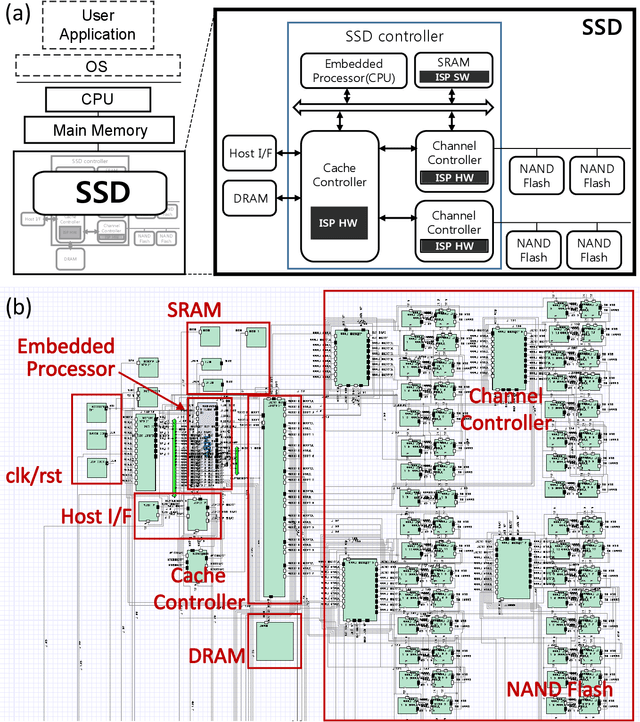

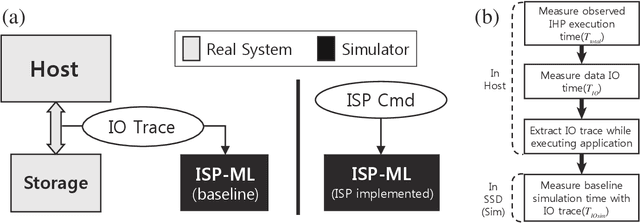
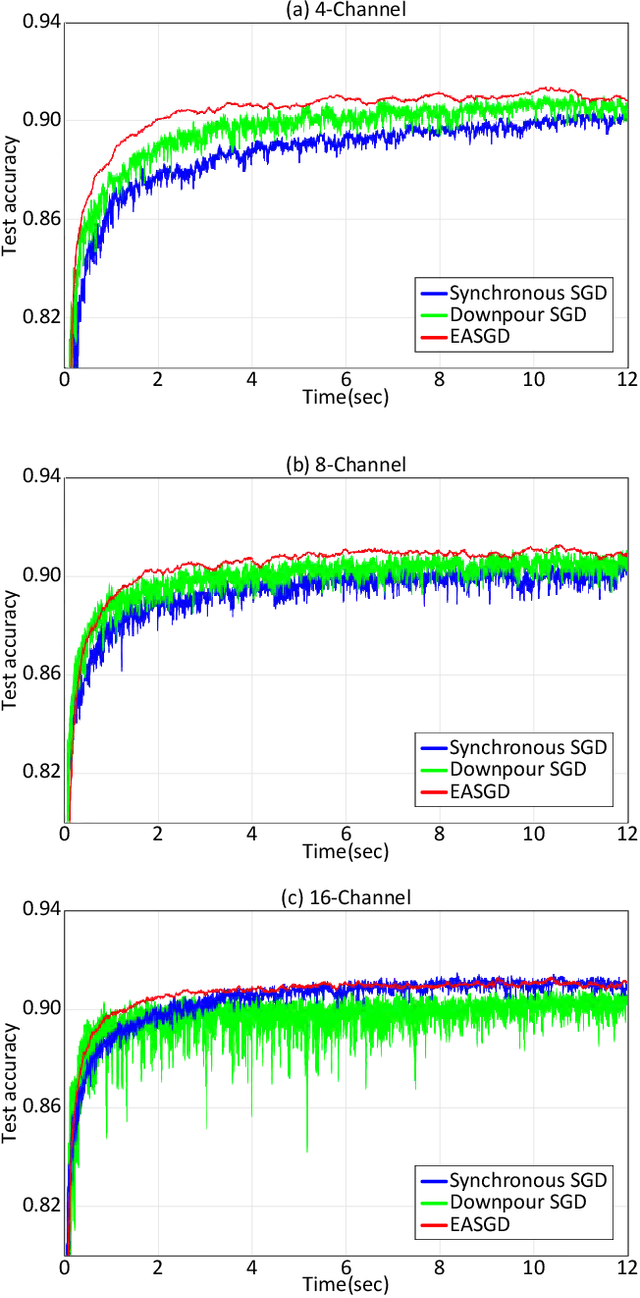
Near-data processing (NDP) refers to augmenting memory or storage with processing power. Despite its potential for acceleration computing and reducing power requirements, only limited progress has been made in popularizing NDP for various reasons. Recently, two major changes have occurred that have ignited renewed interest and caused a resurgence of NDP. The first is the success of machine learning (ML), which often demands a great deal of computation for training, requiring frequent transfers of big data. The second is the popularity of NAND flash-based solid-state drives (SSDs) containing multicore processors that can accommodate extra computation for data processing. In this paper, we evaluate the potential of NDP for ML using a new SSD platform that allows us to simulate instorage processing (ISP) of ML workloads. Our platform (named ISP-ML) is a full-fledged simulator of a realistic multi-channel SSD that can execute various ML algorithms using data stored in the SSD. To conduct a thorough performance analysis and an in-depth comparison with alternative techniques, we focus on a specific algorithm: stochastic gradient descent (SGD), which is the de facto standard for training differentiable models such as logistic regression and neural networks. We implement and compare three SGD variants (synchronous, Downpour, and elastic averaging) using ISP-ML, exploiting the multiple NAND channels to parallelize SGD. In addition, we compare the performance of ISP and that of conventional in-host processing, revealing the advantages of ISP. Based on the advantages and limitations identified through our experiments, we further discuss directions for future research on ISP for accelerating ML.