 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Former: Multi-Scale Patch Selection for Fine-Grained Visual Recognition
Aug 04, 2023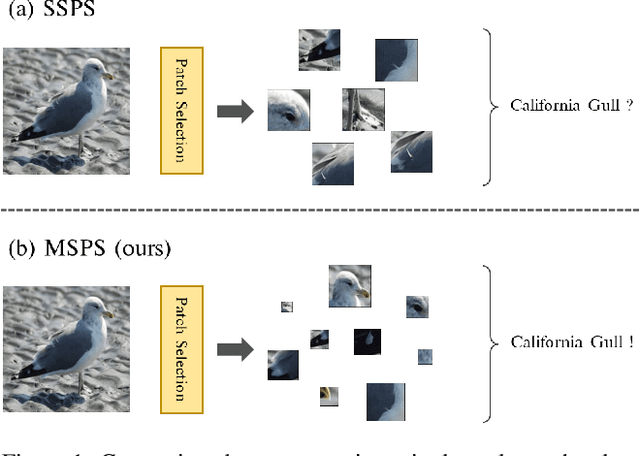
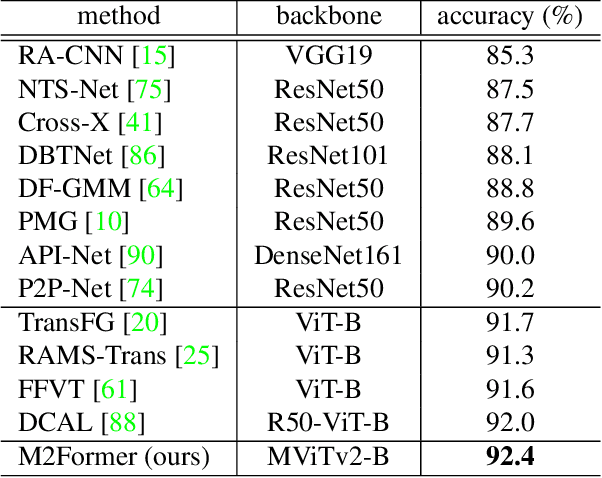
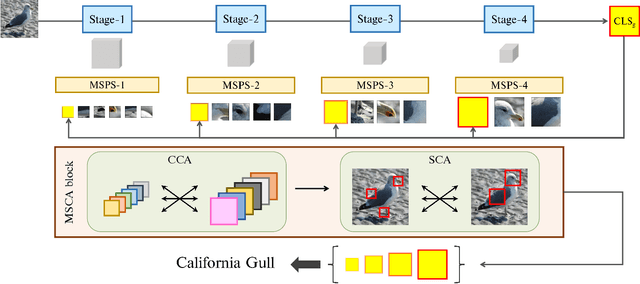
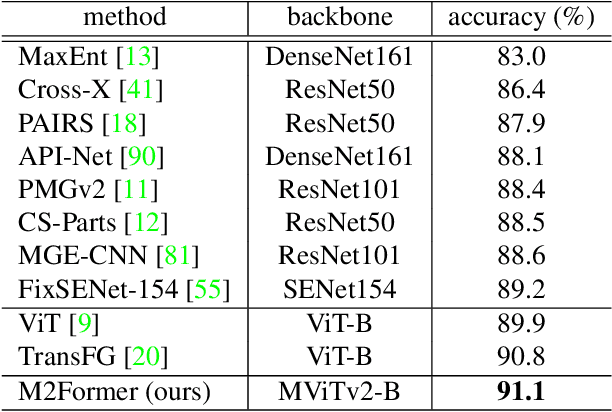
Recently, vision Transformers (ViTs) have been actively applied to fine-grained visual recognition (FGVR). ViT can effectively model the interdependencies between patch-divided object regions through an inherent self-attention mechanism. In addition, patch selection is used with ViT to remove redundant patch information and highlight the most discriminative object patches. However, existing ViT-based FGVR models are limited to single-scale processing, and their fixed receptive fields hinder representational richness and exacerbate vulnerability to scale variability. Therefore, we propose multi-scale patch selection (MSPS) to improve the multi-scale capabilities of existing ViT-based models. Specifically, MSPS selects salient patches of different scales at different stages of a multi-scale vision Transformer (MS-ViT). In addition, we introduce class token transfer (CTT) and multi-scale cross-attention (MSCA) to model cross-scale interactions between selected multi-scale patches and fully reflect them in model decisions. Compared to previous single-scale patch selection (SSPS), our proposed MSPS encourages richer object representations based on feature hierarchy and consistently improves performance from small-sized to large-sized objects. As a result, we propose M2Former, which outperforms CNN-/ViT-based models on several widely used FGVR benchmarks.
Gradient Scaling on Deep Spiking Neural Networks with Spike-Dependent Local Information
Aug 01, 2023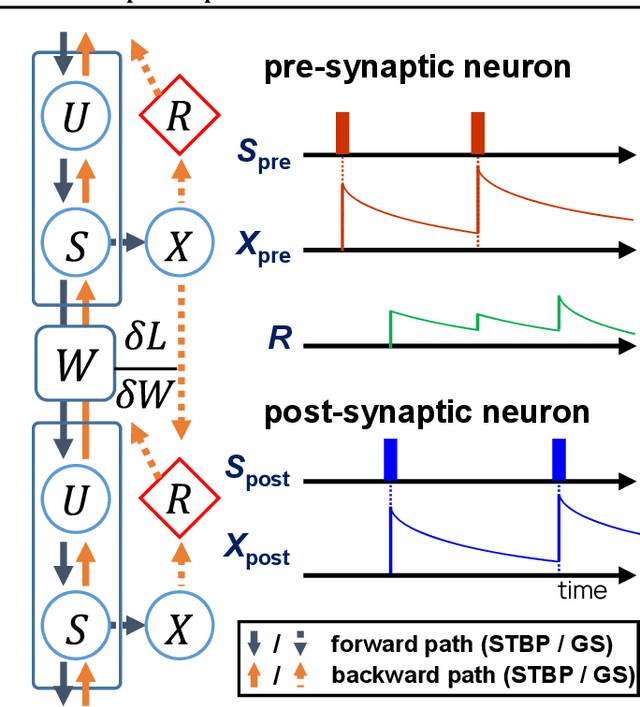
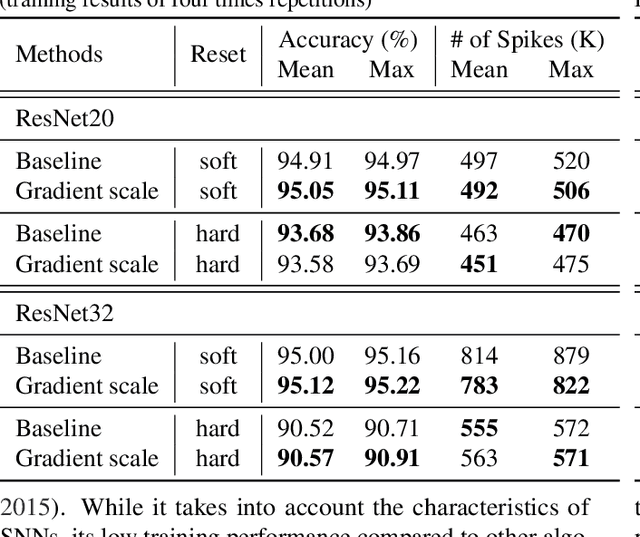
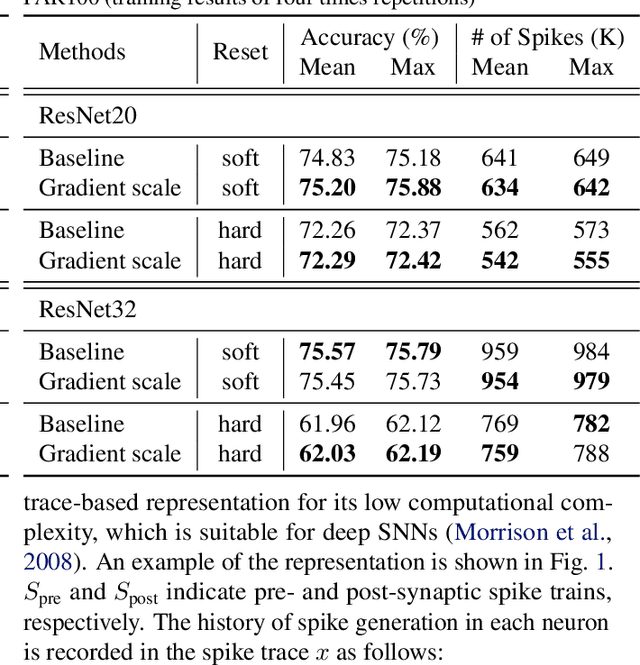
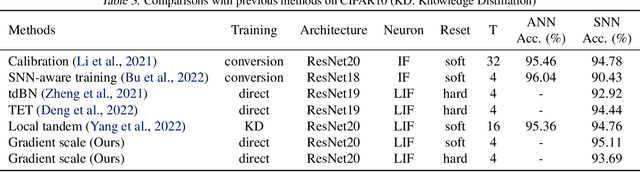
Deep spiking neural networks (SNNs) are promising neural networks for their model capacity from deep neural network architecture and energy efficiency from SNNs' operations. To train deep SNNs, recently, spatio-temporal backpropagation (STBP) with surrogate gradient was proposed. Although deep SNNs have been successfully trained with STBP, they cannot fully utilize spike information. In this work, we proposed gradient scaling with local spike information, which is the relation between pre- and post-synaptic spikes. Considering the causality between spikes, we could enhance the training performance of deep SNNs. According to our experiments, we could achieve higher accuracy with lower spikes by adopting the gradient scaling on image classification tasks, such as CIFAR10 and CIFAR100.
SimFLE: Simple Facial Landmark Encoding for Self-Supervised Facial Expression Recognition in the Wild
Mar 14, 2023One of the key issues in facial expression recognition in the wild (FER-W) is that curating large-scale labeled facial images is challenging due to the inherent complexity and ambiguity of facial images. Therefore, in this paper, we propose a self-supervised simple facial landmark encoding (SimFLE) method that can learn effective encoding of facial landmarks, which are important features for improving the performance of FER-W, without expensive labels. Specifically, we introduce novel FaceMAE module for this purpose. FaceMAE reconstructs masked facial images with elaborately designed semantic masking. Unlike previous random masking, semantic masking is conducted based on channel information processed in the backbone, so rich semantics of channels can be explored. Additionally, the semantic masking process is fully trainable, enabling FaceMAE to guide the backbone to learn spatial details and contextual properties of fine-grained facial landmarks. Experimental results on several FER-W benchmarks prove that the proposed SimFLE is superior in facial landmark localization and noticeably improved performance compared to the supervised baseline and other self-supervised methods.
E2V-SDE: From Asynchronous Events to Fast and Continuous Video Reconstruction via Neural Stochastic Differential Equations
Jun 15, 2022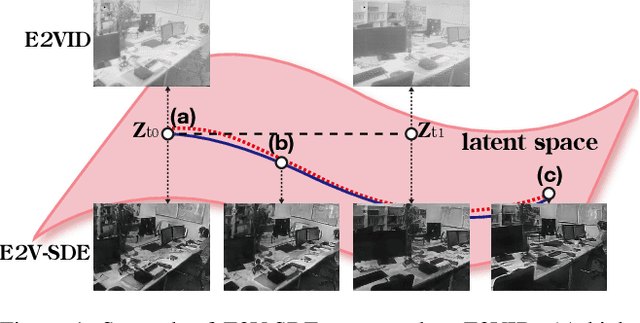
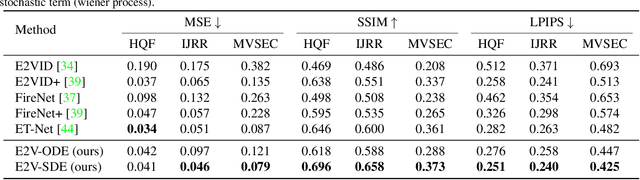
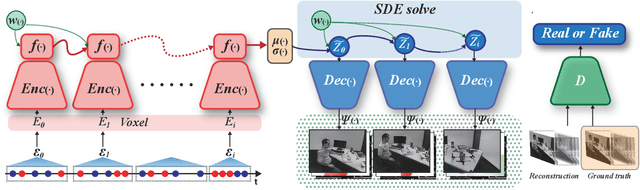
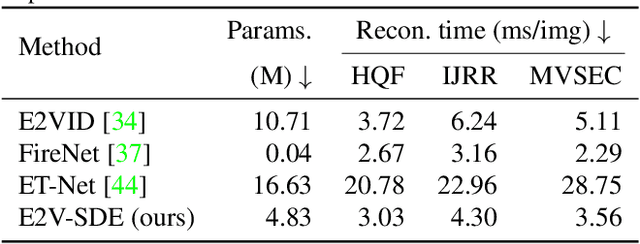
Event cameras respond to brightness changes in the scene asynchronously and independently for every pixel. Due to the properties, these cameras have distinct features: high dynamic range (HDR), high temporal resolution, and low power consumption. However, the results of event cameras should be processed into an alternative representation for computer vision tasks. Also, they are usually noisy and cause poor performance in areas with few events. In recent years, numerous researchers have attempted to reconstruct videos from events. However, they do not provide good quality videos due to a lack of temporal information from irregular and discontinuous data. To overcome these difficulties, we introduce an E2V-SDE whose dynamics are governed in a latent space by Stochastic differential equations (SDE). Therefore, E2V-SDE can rapidly reconstruct images at arbitrary time steps and make realistic predictions on unseen data. In addition, we successfully adopted a variety of image composition techniques for improving image clarity and temporal consistency. By conducting extensive experiments on simulated and real-scene datasets, we verify that our model outperforms state-of-the-art approaches under various video reconstruction settings. In terms of image quality, the LPIPS score improves by up to 12% and the reconstruction speed is 87% higher than that of ET-Net.
* 2022 CVPR oral
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022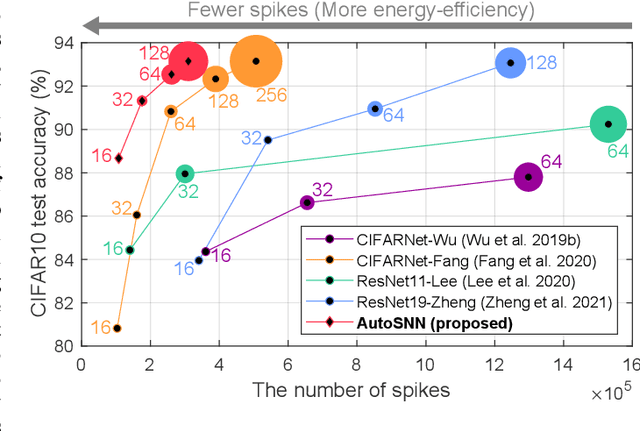
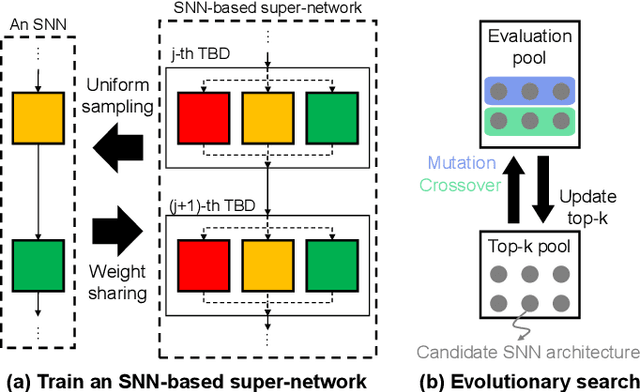
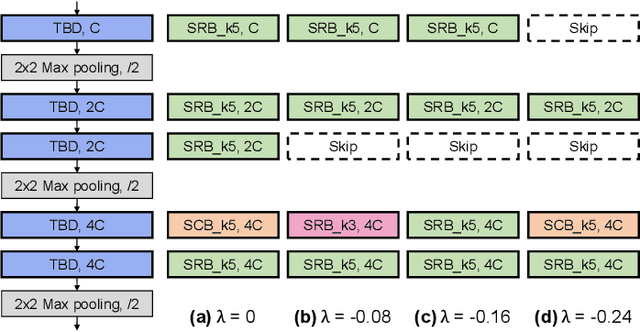
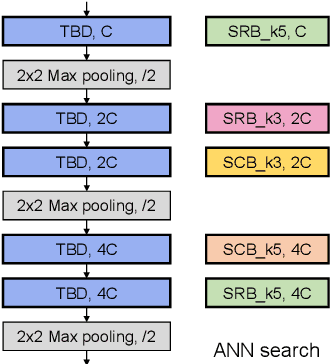
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Scalable Smartphone Cluster for Deep Learning
Oct 23, 2021
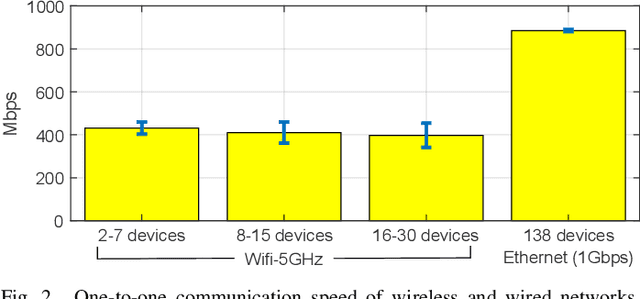

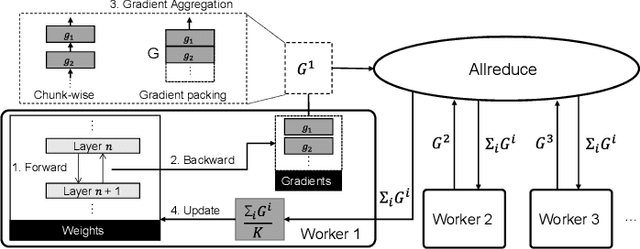
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.
Improving Sentence-Level Relation Extraction through Curriculum Learning
Aug 04, 2021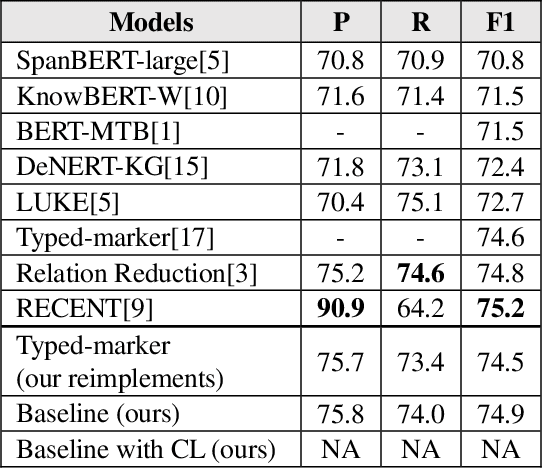
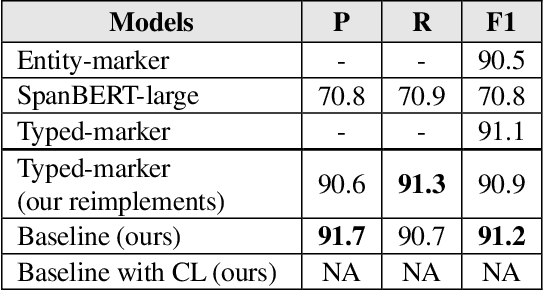
Sentence-level relation extraction mainly aims to classify the relation between two entities in a sentence. The sentence-level relation extraction corpus often contains data that are difficult for the model to infer or noise data. In this paper, we propose a curriculum learning-based relation extraction model that splits data by difficulty and utilizes them for learning. In the experiments with the representative sentence-level relation extraction datasets, TACRED and Re-TACRED, the proposed method obtained an F1-score of 75.0% and 91.4% respectively, which are the state-of-the-art performance.
Energy-efficient Knowledge Distillation for Spiking Neural Networks
Jun 14, 2021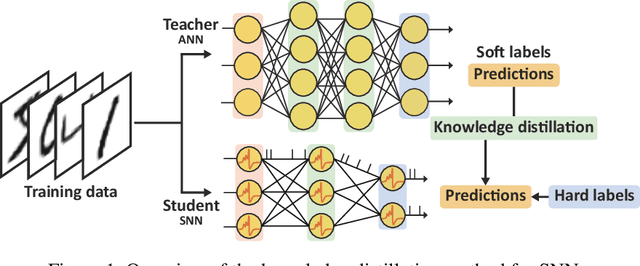
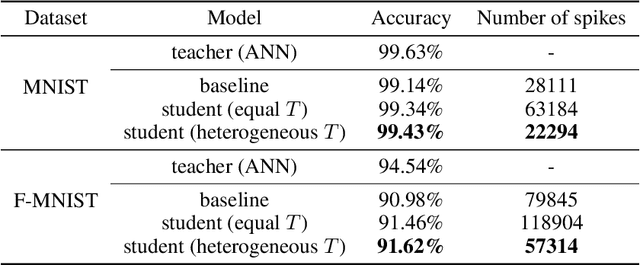
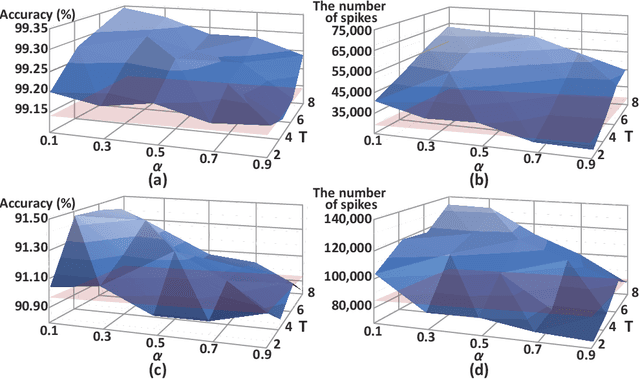
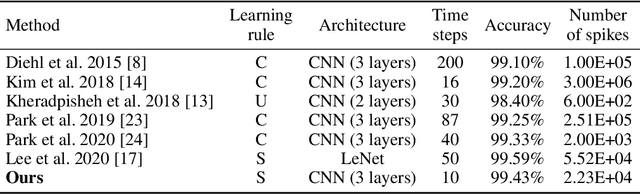
Spiking neural networks (SNNs) have been gaining interest as energy-efficient alternatives of conventional artificial neural networks (ANNs) due to their event-driven computation. Considering the future deployment of SNN models to constrained neuromorphic devices, many studies have applied techniques originally used for ANN model compression, such as network quantization, pruning, and knowledge distillation, to SNNs. Among them, existing works on knowledge distillation reported accuracy improvements of student SNN model. However, analysis on energy efficiency, which is also an important feature of SNN, was absent. In this paper, we thoroughly analyze the performance of the distilled SNN model in terms of accuracy and energy efficiency. In the process, we observe a substantial increase in the number of spikes, leading to energy inefficiency, when using the conventional knowledge distillation methods. Based on this analysis, to achieve energy efficiency, we propose a novel knowledge distillation method with heterogeneous temperature parameters. We evaluate our method on two different datasets and show that the resulting SNN student satisfies both accuracy improvement and reduction of the number of spikes. On MNIST dataset, our proposed student SNN achieves up to 0.09% higher accuracy and produces 65% less spikes compared to the student SNN trained with conventional knowledge distillation method. We also compare the results with other SNN compression techniques and training methods.
Training Energy-Efficient Deep Spiking Neural Networks with Time-to-First-Spike Coding
Jun 04, 2021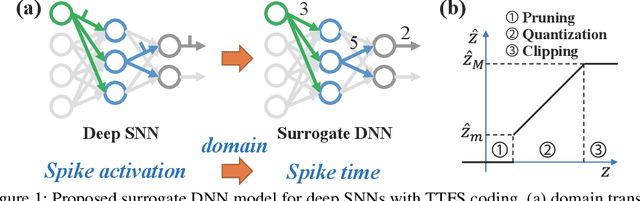



The tremendous energy consumption of deep neural networks (DNNs) has become a serious problem in deep learning. Spiking neural networks (SNNs), which mimic the operations in the human brain, have been studied as prominent energy-efficient neural networks. Due to their event-driven and spatiotemporally sparse operations, SNNs show possibilities for energy-efficient processing. To unlock their potential, deep SNNs have adopted temporal coding such as time-to-first-spike (TTFS)coding, which represents the information between neurons by the first spike time. With TTFS coding, each neuron generates one spike at most, which leads to a significant improvement in energy efficiency. Several studies have successfully introduced TTFS coding in deep SNNs, but they showed restricted efficiency improvement owing to the lack of consideration for efficiency during training. To address the aforementioned issue, this paper presents training methods for energy-efficient deep SNNs with TTFS coding. We introduce a surrogate DNN model to train the deep SNN in a feasible time and analyze the effect of the temporal kernel on training performance and efficiency. Based on the investigation, we propose stochastically relaxed activation and initial value-based regularization for the temporal kernel parameters. In addition, to reduce the number of spikes even further, we present temporal kernel-aware batch normalization. With the proposed methods, we could achieve comparable training results with significantly reduced spikes, which could lead to energy-efficient deep SNNs.
Noise-Robust Deep Spiking Neural Networks with Temporal Information
Apr 22, 2021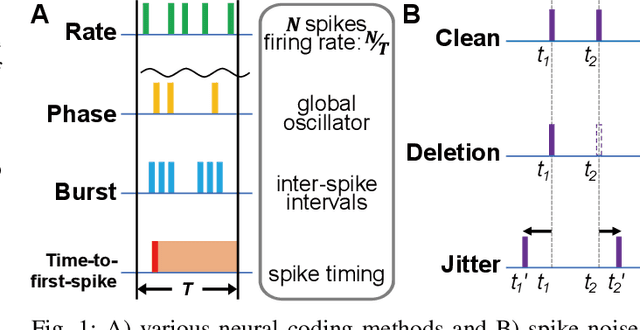
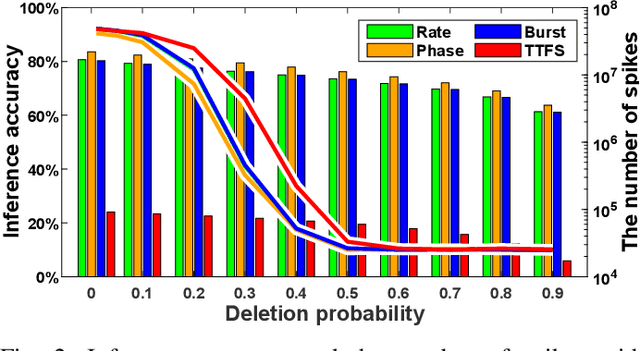
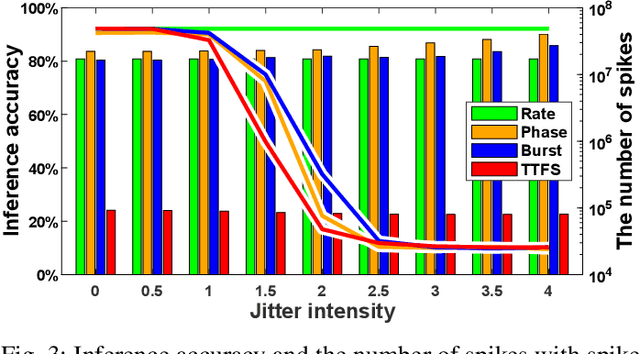
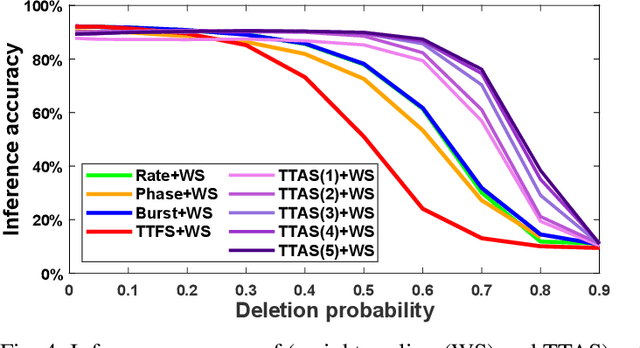
Spiking neural networks (SNNs) have emerged as energy-efficient neural networks with temporal information. SNNs have shown a superior efficiency on neuromorphic devices, but the devices are susceptible to noise, which hinders them from being applied in real-world applications. Several studies have increased noise robustness, but most of them considered neither deep SNNs nor temporal information. In this paper, we investigate the effect of noise on deep SNNs with various neural coding methods and present a noise-robust deep SNN with temporal information. With the proposed methods, we have achieved a deep SNN that is efficient and robust to spike deletion and jitter.