 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2V-SDE: From Asynchronous Events to Fast and Continuous Video Reconstruction via Neural Stochastic Differential Equations
Jun 15, 2022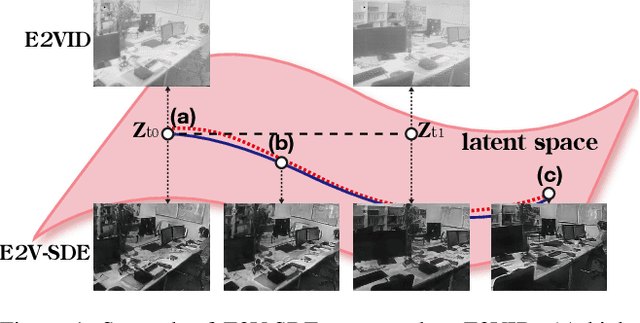
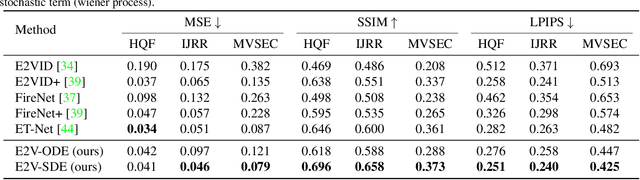
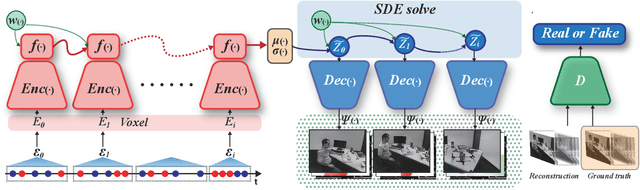
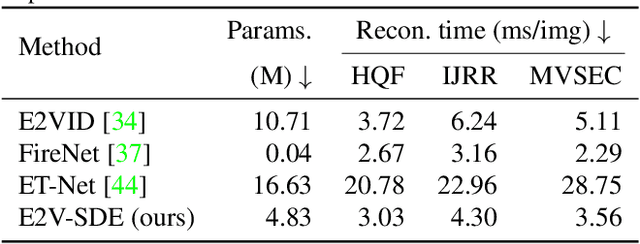
Event cameras respond to brightness changes in the scene asynchronously and independently for every pixel. Due to the properties, these cameras have distinct features: high dynamic range (HDR), high temporal resolution, and low power consumption. However, the results of event cameras should be processed into an alternative representation for computer vision tasks. Also, they are usually noisy and cause poor performance in areas with few events. In recent years, numerous researchers have attempted to reconstruct videos from events. However, they do not provide good quality videos due to a lack of temporal information from irregular and discontinuous data. To overcome these difficulties, we introduce an E2V-SDE whose dynamics are governed in a latent space by Stochastic differential equations (SDE). Therefore, E2V-SDE can rapidly reconstruct images at arbitrary time steps and make realistic predictions on unseen data. In addition, we successfully adopted a variety of image composition techniques for improving image clarity and temporal consistency. By conducting extensive experiments on simulated and real-scene datasets, we verify that our model outperforms state-of-the-art approaches under various video reconstruction settings. In terms of image quality, the LPIPS score improves by up to 12% and the reconstruction speed is 87% higher than that of ET-Net.
* 2022 CVPR oral
Demystifying the Neural Tangent Kernel from a Practical Perspective: Can it be trusted for Neural Architecture Search without training?
Mar 28, 2022
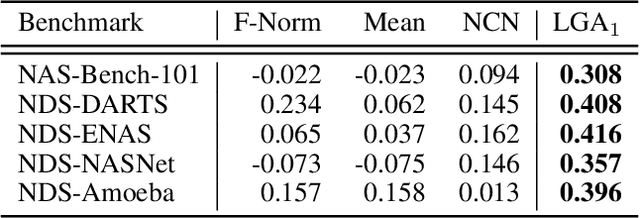
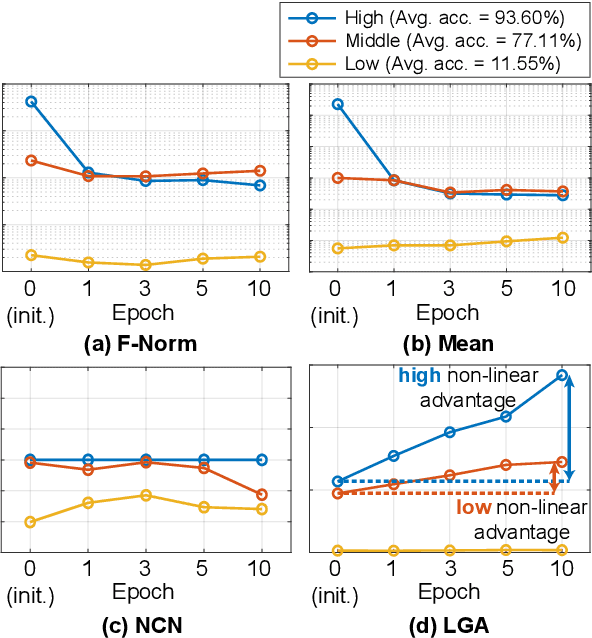
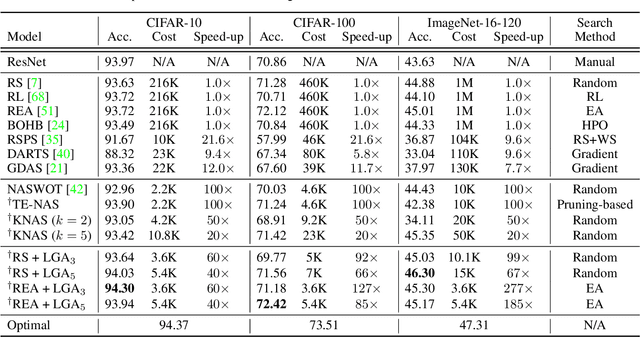
In Neural Architecture Search (NAS), reducing the cost of architecture evaluation remains one of the most crucial challenges. Among a plethora of efforts to bypass training of each candidate architecture to convergence for evaluation, the Neural Tangent Kernel (NTK) is emerging as a promising theoretical framework that can be utilized to estimate the performance of a neural architecture at initialization. In this work, we revisit several at-initialization metrics that can be derived from the NTK and reveal their key shortcomings. Then, through the empirical analysis of the time evolution of NTK, we deduce that modern neural architectures exhibit highly non-linear characteristics, making the NTK-based metrics incapable of reliably estimating the performance of an architecture without some amount of training. To take such non-linear characteristics into account, we introduce Label-Gradient Alignment (LGA), a novel NTK-based metric whose inherent formulation allows it to capture the large amount of non-linear advantage present in modern neural architectures. With minimal amount of training, LGA obtains a meaningful level of rank correlation with the post-training test accuracy of an architecture. Lastly, we demonstrate that LGA, complemented with few epochs of training, successfully guides existing search algorithms to achieve competitive search performances with significantly less search cost. The code is available at: https://github.com/nutellamok/DemystifyingNTK.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022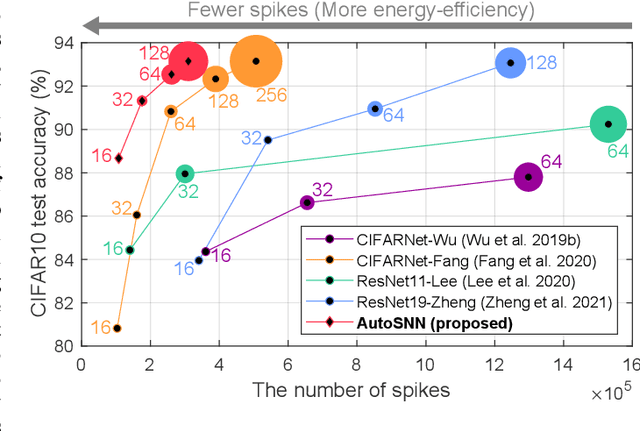
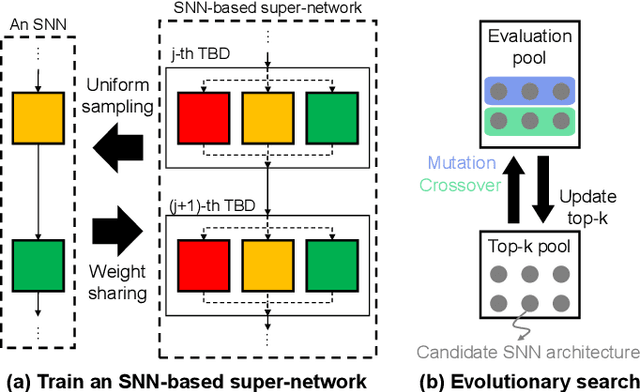
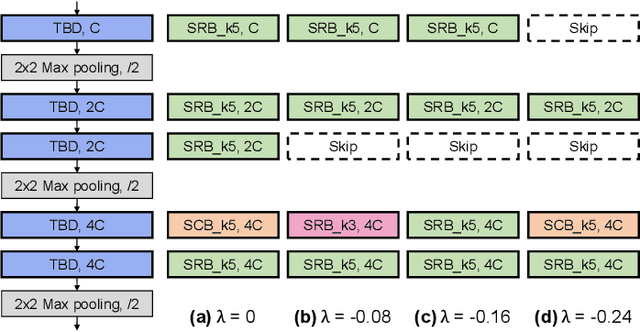
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Scalable Smartphone Cluster for Deep Learning
Oct 23, 2021
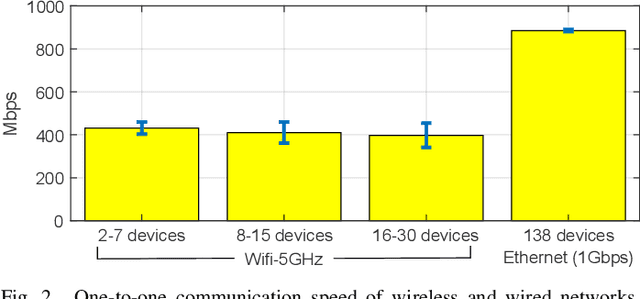

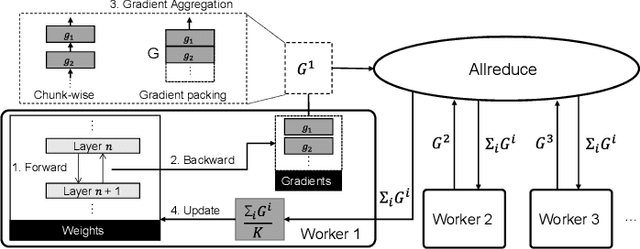
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.
AdvRush: Searching for Adversarially Robust Neural Architectures
Aug 10, 2021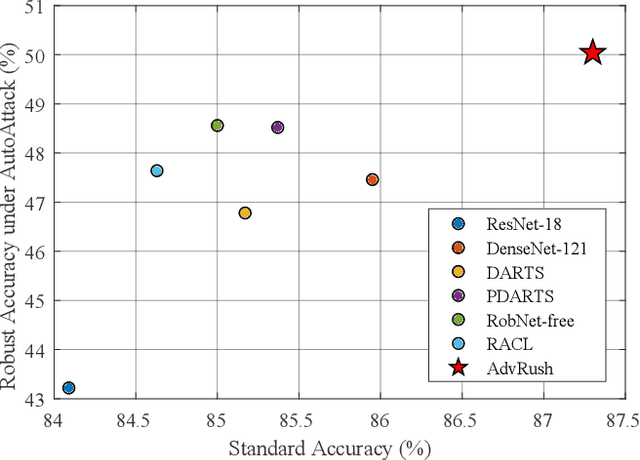
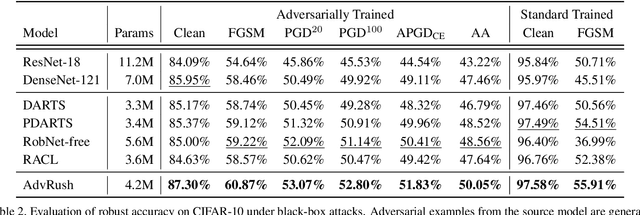
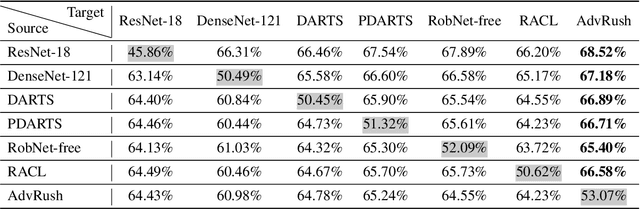
Deep neural networks continue to awe the world with their remarkable performance. Their predictions, however, are prone to be corrupted by adversarial examples that are imperceptible to humans. Current efforts to improve the robustness of neural networks against adversarial examples are focused on developing robust training methods, which update the weights of a neural network in a more robust direction. In this work, we take a step beyond training of the weight parameters and consider the problem of designing an adversarially robust neural architecture with high intrinsic robustness. We propose AdvRush, a novel adversarial robustness-aware neural architecture search algorithm, based upon a finding that independent of the training method, the intrinsic robustness of a neural network can be represented with the smoothness of its input loss landscape. Through a regularizer that favors a candidate architecture with a smoother input loss landscape, AdvRush successfully discovers an adversarially robust neural architecture. Along with a comprehensive theoretical motivation for AdvRush, we conduct an extensive amount of experiments to demonstrate the efficacy of AdvRush on various benchmark datasets. Notably, on CIFAR-10, AdvRush achieves 55.91% robust accuracy under FGSM attack after standard training and 50.04% robust accuracy under AutoAttack after 7-step PGD adversarial training.
Accelerating Neural Architecture Search via Proxy Data
Jun 09, 2021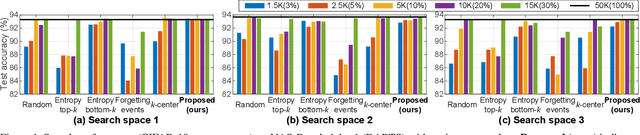
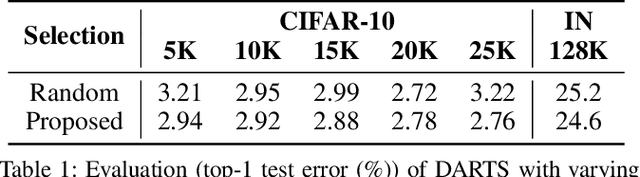

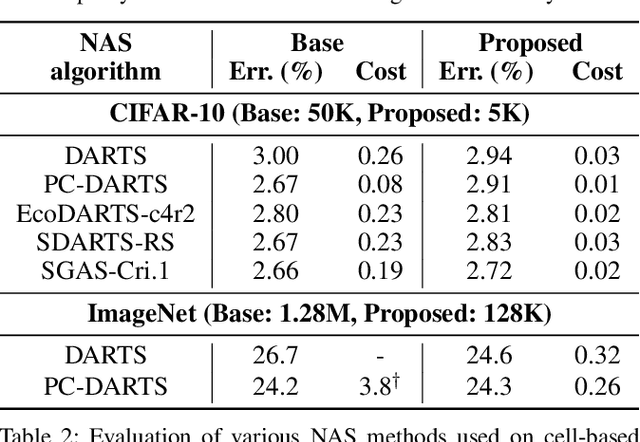
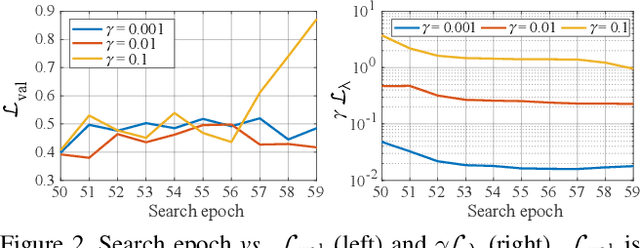
Despite the increasing interest in neural architecture search (NAS), the significant computational cost of NAS is a hindrance to researchers. Hence, we propose to reduce the cost of NAS using proxy data, i.e., a representative subset of the target data, without sacrificing search performance. Even though data selection has been used across various fields, our evaluation of existing selection methods for NAS algorithms offered by NAS-Bench-1shot1 reveals that they are not always appropriate for NAS and a new selection method is necessary. By analyzing proxy data constructed using various selection methods through data entropy, we propose a novel proxy data selection method tailored for NAS. To empirically demonstrate the effectiveness, we conduct thorough experiments across diverse datasets, search spaces, and NAS algorithms. Consequently, NAS algorithms with the proposed selection discover architectures that are competitive with those obtained using the entire dataset. It significantly reduces the search cost: executing DARTS with the proposed selection requires only 40 minutes on CIFAR-10 and 7.5 hours on ImageNet with a single GPU. Additionally, when the architecture searched on ImageNet using the proposed selection is inversely transferred to CIFAR-10, a state-of-the-art test error of 2.4\% is yielded. Our code is available at https://github.com/nabk89/NAS-with-Proxy-data.
T2FSNN: Deep Spiking Neural Networks with Time-to-first-spike Coding
Mar 26, 2020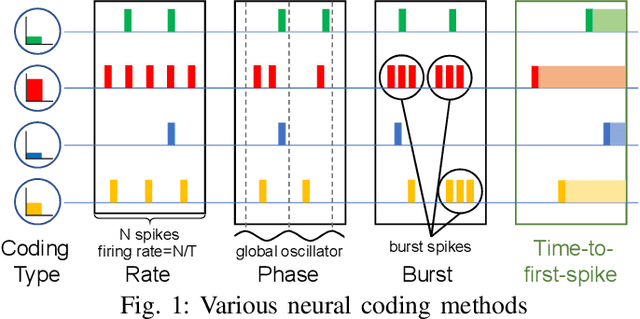
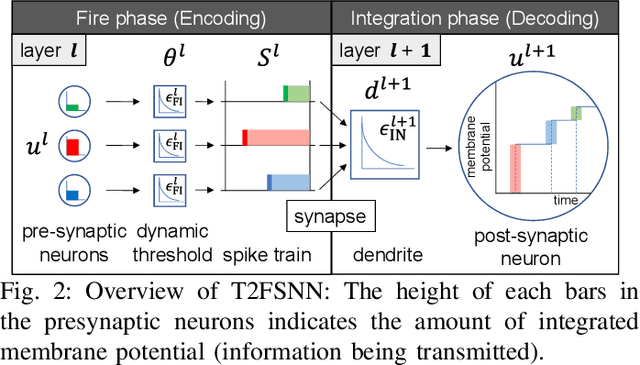
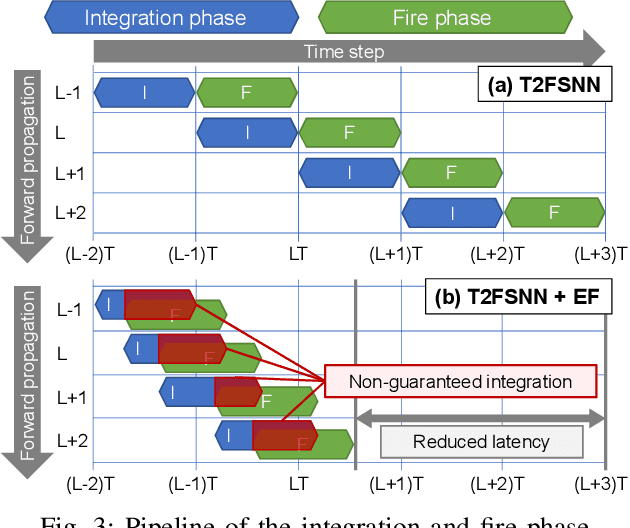
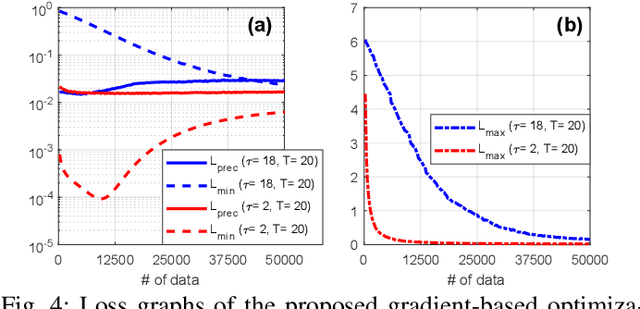
Spiking neural networks (SNNs) have gained considerable interest due to their energy-efficient characteristics, yet lack of a scalable training algorithm has restricted their applicability in practical machine learning problems. The deep neural network-to-SNN conversion approach has been widely studied to broaden the applicability of SNNs. Most previous studies, however, have not fully utilized spatio-temporal aspects of SNNs, which has led to inefficiency in terms of number of spikes and inference latency. In this paper, we present T2FSNN, which introduces the concept of time-to-first-spike coding into deep SNNs using the kernel-based dynamic threshold and dendrite to overcome the aforementioned drawback. In addition, we propose gradient-based optimization and early firing methods to further increase the efficiency of the T2FSNN. According to our results, the proposed methods can reduce inference latency and number of spikes to 22% and less than 1%, compared to those of burst coding, which is the state-of-the-art result on the CIFAR-100.
Spiking-YOLO: Spiking Neural Network for Real-time Object Detection
Mar 12, 2019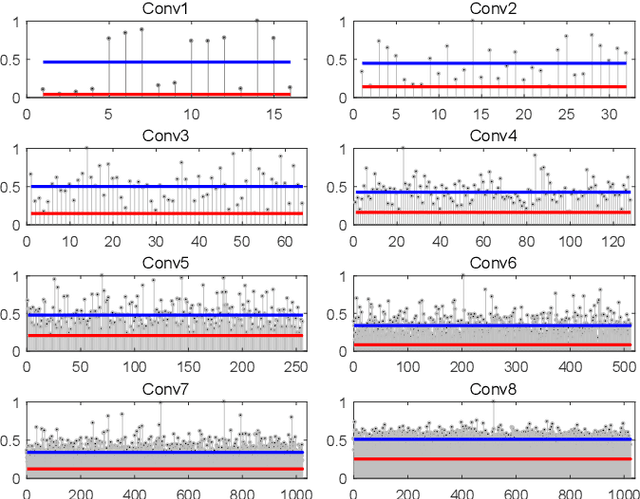
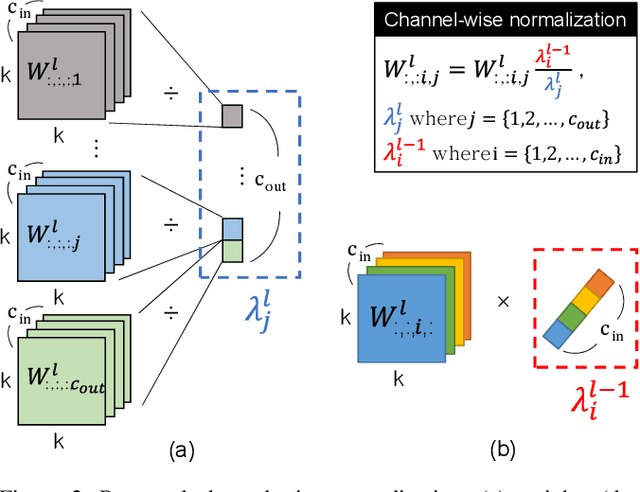
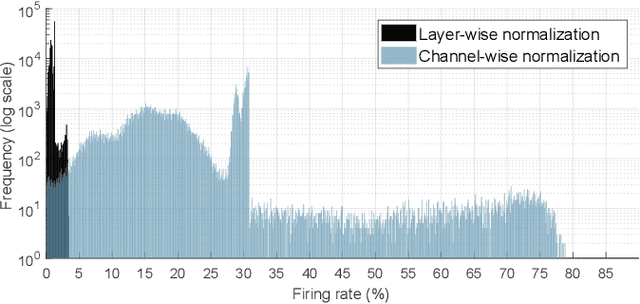
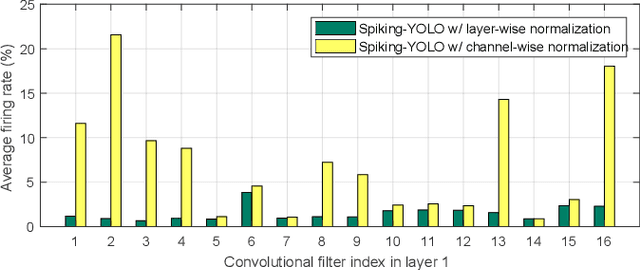
Over the past decade, deep neural networks (DNNs) have become a de-facto standard for solving machine learning problems. As we try to solve more advanced problems, growing demand for computing and power resources are inevitable, nearly impossible to employ DNNs on embedded systems, where available resources are limited. Given these circumstances, spiking neural networks (SNNs) are attracting widespread interest as the third generation of neural network, due to event-driven and low-powered nature. However, SNNs come at the cost of significant performance degradation largely due to complex dynamics of SNN neurons and non-differential spike operation. Thus, its application has been limited to relatively simple tasks such as image classification. In this paper, we investigate the performance degradation of SNNs in the much more challenging task of object detection. From our in-depth analysis, we introduce two novel methods to overcome a significant performance gap: channel-wise normalization and signed neuron with imbalanced threshold. Consequently, we present a spiked-based real-time object detection model, called Spiking-YOLO that provides near-lossless information transmission in a shorter period of time for deep SNN. Our experiments show that the Spiking-YOLO is able to achieve comparable results up to 97% of the original YOLO on a non-trivial dataset, PASCAL VOC.
DNA-Level Splice Junction Prediction using Deep Recurrent Neural Networks
Dec 16, 2015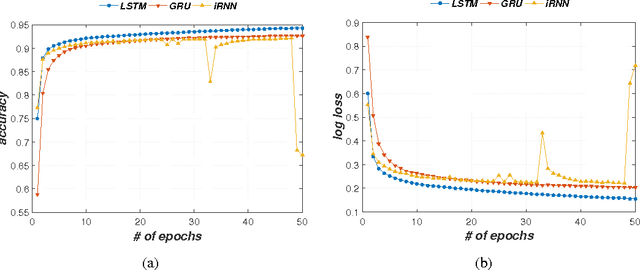

A eukaryotic gene consists of multiple exons (protein coding regions) and introns (non-coding regions), and a splice junction refers to the boundary between a pair of exon and intron. Precise identification of spice junctions on a gene is important for deciphering its primary structure, function, and interaction. Experimental techniques for determining exon/intron boundaries include RNA-seq, which is often accompanied by computational approaches. Canonical splicing signals are known, but computational junction prediction still remains challenging because of a large number of false positives and other complications. In this paper, we exploit deep recurrent neural networks (RNNs) to model DNA sequences and to detect splice junctions thereon. We test various RNN units and architectures including long short-term memory units, gated recurrent units, and recently proposed iRNN for in-depth design space exploration. According to our experimental results, the proposed approach significantly outperforms not only conventional machine learning-based methods but also a recent state-of-the-art deep belief network-based technique in terms of prediction accuracy.