 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Constant Acceleration Flow
Nov 01, 2024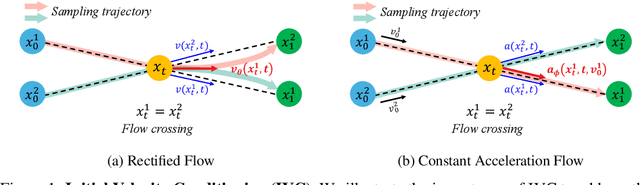
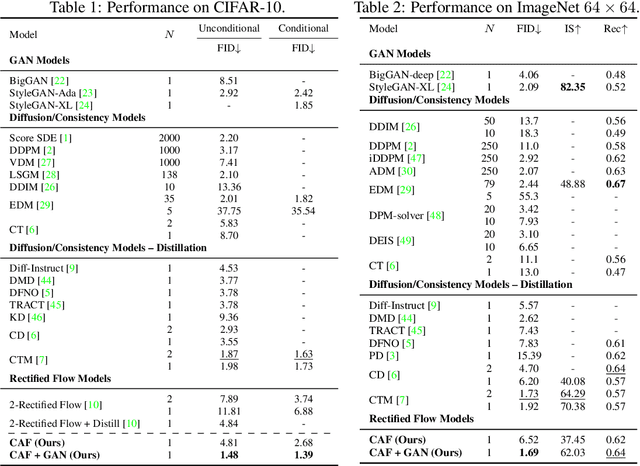
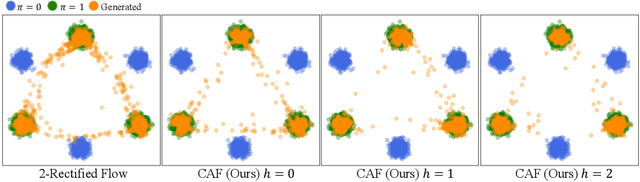
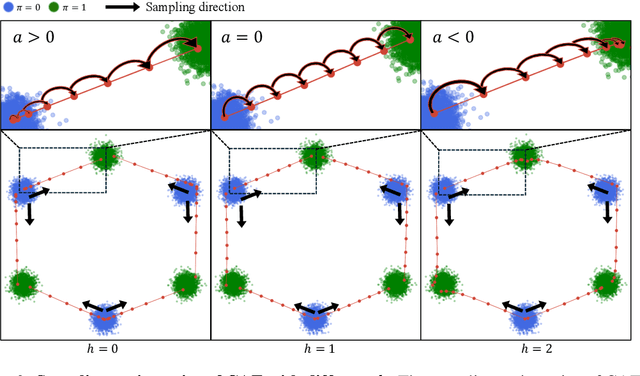
Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows. They operate under the assumption that image and noise pairs, known as couplings, can be approximated by straight trajectories with constant velocity. However, we observe that modeling with constant velocity and using reflow procedures have limitations in accurately learning straight trajectories between pairs, resulting in suboptimal performance in few-step generation. To address these limitations, we introduce Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. CAF introduces acceleration as an additional learnable variable, allowing for more expressive and accurate estimation of the ODE flow. Moreover, we propose two techniques to further improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comprehensive studies on toy datasets, CIFAR-10, and ImageNet 64x64 demonstrate that CAF outperforms state-of-the-art baselines for one-step generation. We also show that CAF dramatically improves few-step coupling preservation and inversion over Rectified flow. Code is available at \href{https://github.com/mlvlab/CAF}{https://github.com/mlvlab/CAF}.
DOO-RE: A dataset of ambient sensors in a meeting room for activity recognition
Jan 17, 2024With the advancement of IoT technology, recognizing user activities with machine learning methods is a promising way to provide various smart services to users. High-quality data with privacy protection is essential for deploying such services in the real world. Data streams from surrounding ambient sensors are well suited to the requirement. Existing ambient sensor datasets only support constrained private spaces and those for public spaces have yet to be explored despite growing interest in research on them. To meet this need, we build a dataset collected from a meeting room equipped with ambient sensors. The dataset, DOO-RE, includes data streams from various ambient sensor types such as Sound and Projector. Each sensor data stream is segmented into activity units and multiple annotators provide activity labels through a cross-validation annotation process to improve annotation quality. We finally obtain 9 types of activities. To our best knowledge, DOO-RE is the first dataset to support the recognition of both single and group activities in a real meeting room with reliable annotations.
Semi-orthogonal Embedding for Efficient Unsupervised Anomaly Segmentation
May 31, 2021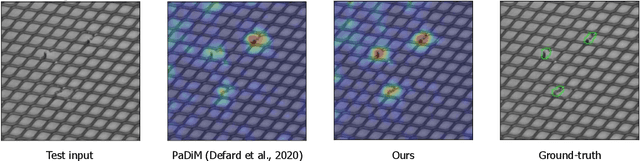
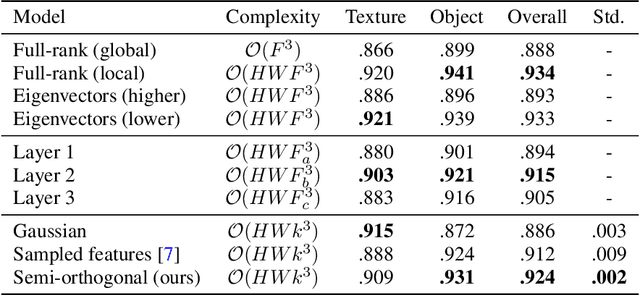
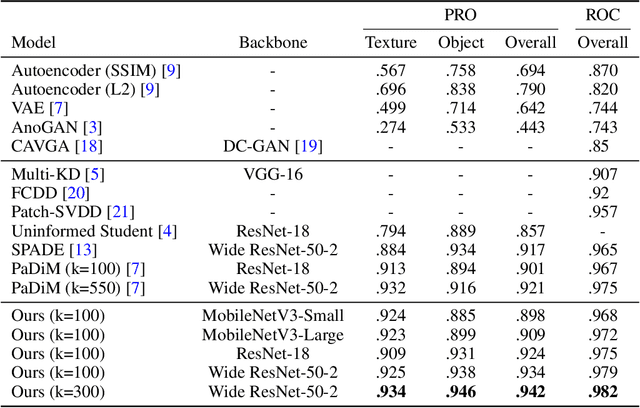
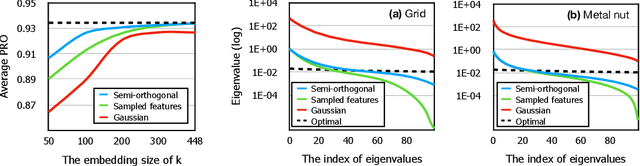
We present the efficiency of semi-orthogonal embedding for unsupervised anomaly segmentation. The multi-scale features from pre-trained CNNs are recently used for the localized Mahalanobis distances with significant performance. However, the increased feature size is problematic to scale up to the bigger CNNs, since it requires the batch-inverse of multi-dimensional covariance tensor. Here, we generalize an ad-hoc method, random feature selection, into semi-orthogonal embedding for robust approximation, cubically reducing the computational cost for the inverse of multi-dimensional covariance tensor. With the scrutiny of ablation studies, the proposed method achieves a new state-of-the-art with significant margins for the MVTec AD, KolektorSDD, KolektorSDD2, and mSTC datasets. The theoretical and empirical analyses offer insights and verification of our straightforward yet cost-effective approach.
Semi-supervised Learning with Deep Generative Models for Asset Failure Prediction
Sep 04, 2017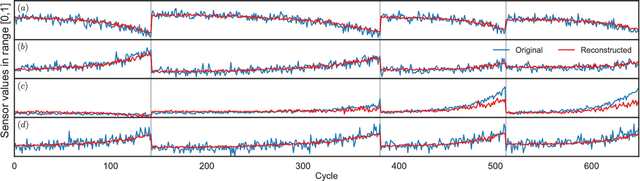
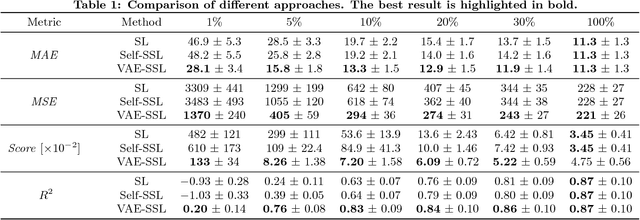
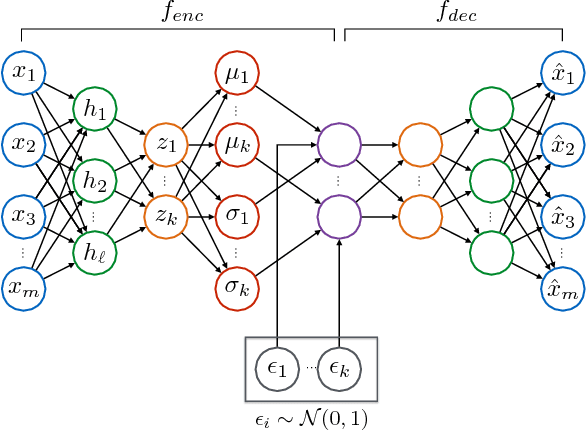
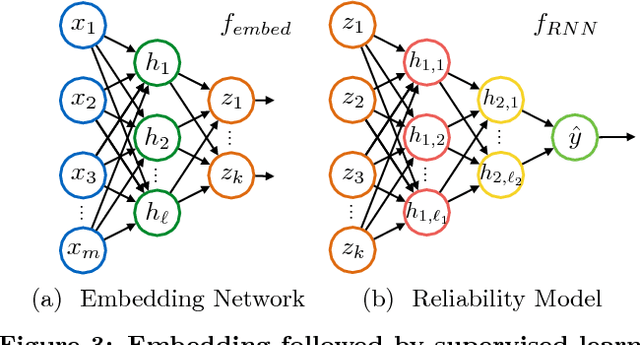
This work presents a novel semi-supervised learning approach for data-driven modeling of asset failures when health status is only partially known in historical data. We combine a generative model parameterized by deep neural networks with non-linear embedding technique. It allows us to build prognostic models with the limited amount of health status information for the precise prediction of future asset reliability. The proposed method is evaluated on a publicly available dataset for remaining useful life (RUL) estimation, which shows significant improvement even when a fraction of the data with known health status is as sparse as 1% of the total. Our study suggests that the non-linear embedding based on a deep generative model can efficiently regularize a complex model with deep architectures while achieving high prediction accuracy that is far less sensitive to the availability of health status information.
Regularization and Kernelization of the Maximin Correlation Approach
Mar 29, 2016

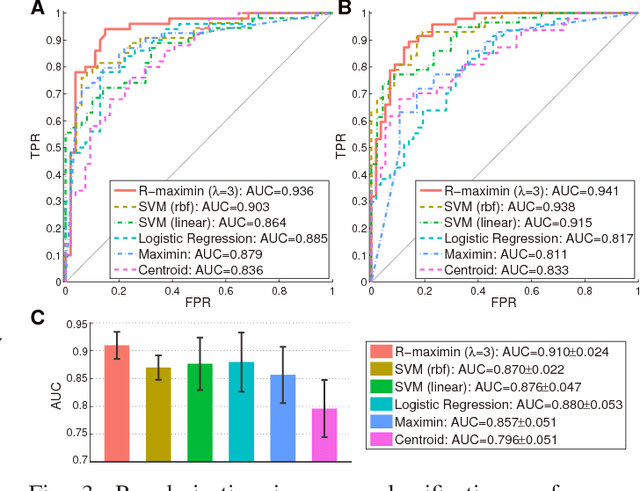
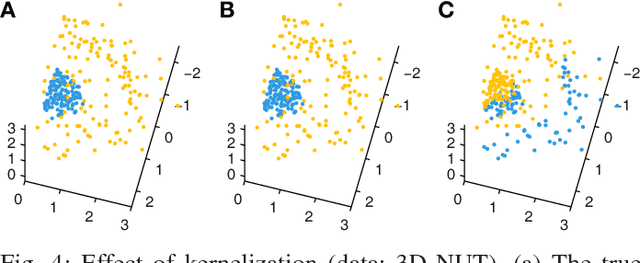
Robust classification becomes challenging when each class consists of multiple subclasses. Examples include multi-font optical character recognition and automated protein function prediction. In correlation-based nearest-neighbor classification, the maximin correlation approach (MCA) provides the worst-case optimal solution by minimizing the maximum misclassification risk through an iterative procedure. Despite the optimality, the original MCA has drawbacks that have limited its wide applicability in practice. That is, the MCA tends to be sensitive to outliers, cannot effectively handle nonlinearities in datasets, and suffers from having high computational complexity. To address these limitations, we propose an improved solution, named regularized maximin correlation approach (R-MCA). We first reformulate MCA as a quadratically constrained linear programming (QCLP) problem, incorporate regularization by introducing slack variables in the primal problem of the QCLP, and derive the corresponding Lagrangian dual. The dual formulation enables us to apply the kernel trick to R-MCA so that it can better handle nonlinearities. Our experimental results demonstrate that the regularization and kernelization make the proposed R-MCA more robust and accurate for various classification tasks than the original MCA. Furthermore, when the data size or dimensionality grows, R-MCA runs substantially faster by solving either the primal or dual (whichever has a smaller variable dimension) of the QCLP.
Manifold Regularized Deep Neural Networks using Adversarial Examples
Jan 14, 2016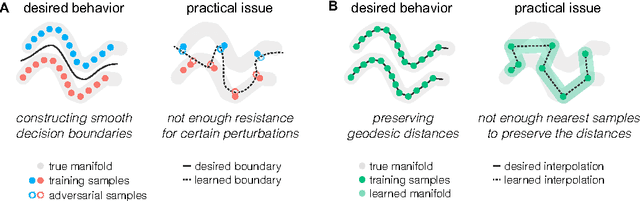
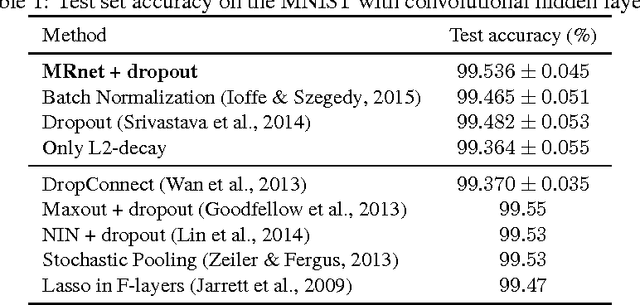

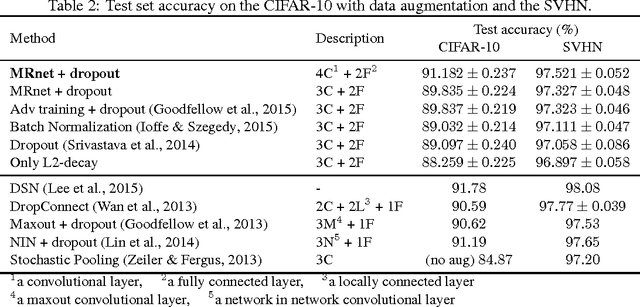
Learning meaningful representations using deep neural networks involves designing efficient training schemes and well-structured networks. Currently, the method of stochastic gradient descent that has a momentum with dropout is one of the most popular training protocols. Based on that, more advanced methods (i.e., Maxout and Batch Normalization) have been proposed in recent years, but most still suffer from performance degradation caused by small perturbations, also known as adversarial examples. To address this issue, we propose manifold regularized networks (MRnet) that utilize a novel training objective function that minimizes the difference between multi-layer embedding results of samples and those adversarial. Our experimental results demonstrated that MRnet is more resilient to adversarial examples and helps us to generalize representations on manifolds. Furthermore, combining MRnet and dropout allowed us to achieve competitive classification performances for three well-known benchmarks: MNIST, CIFAR-10, and SVHN.
DNA-Level Splice Junction Prediction using Deep Recurrent Neural Networks
Dec 16, 2015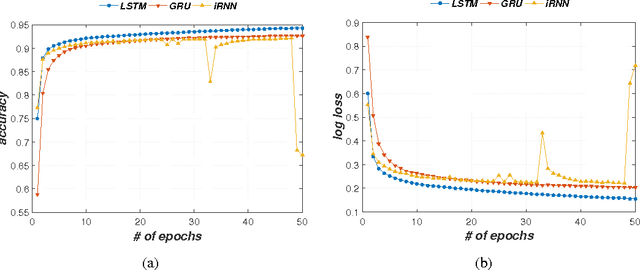

A eukaryotic gene consists of multiple exons (protein coding regions) and introns (non-coding regions), and a splice junction refers to the boundary between a pair of exon and intron. Precise identification of spice junctions on a gene is important for deciphering its primary structure, function, and interaction. Experimental techniques for determining exon/intron boundaries include RNA-seq, which is often accompanied by computational approaches. Canonical splicing signals are known, but computational junction prediction still remains challenging because of a large number of false positives and other complications. In this paper, we exploit deep recurrent neural networks (RNNs) to model DNA sequences and to detect splice junctions thereon. We test various RNN units and architectures including long short-term memory units, gated recurrent units, and recently proposed iRNN for in-depth design space exploration. According to our experimental results, the proposed approach significantly outperforms not only conventional machine learning-based methods but also a recent state-of-the-art deep belief network-based technique in terms of prediction accuracy.