 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainDecoder: Style-Based Visual Decoding of EEG Signals
Sep 09, 2024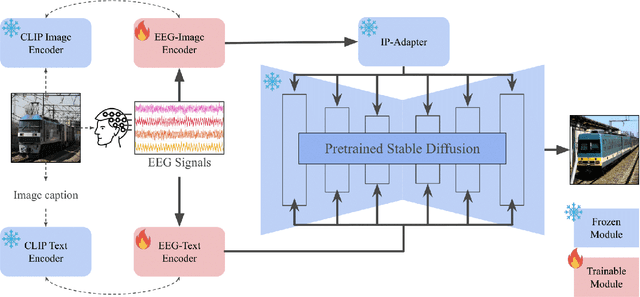



Decoding neural representations of visual stimuli from electroencephalography (EEG) offers valuable insights into brain activity and cognition. Recent advancements in deep learning have significantly enhanced the field of visual decoding of EEG, primarily focusing on reconstructing the semantic content of visual stimuli. In this paper, we present a novel visual decoding pipeline that, in addition to recovering the content, emphasizes the reconstruction of the style, such as color and texture, of images viewed by the subject. Unlike previous methods, this ``style-based'' approach learns in the CLIP spaces of image and text separately, facilitating a more nuanced extraction of information from EEG signals. We also use captions for text alignment simpler than previously employed, which we find work better. Both quantitative and qualitative evaluations show that our method better preserves the style of visual stimuli and extracts more fine-grained semantic information from neural signals. Notably, it achieves significant improvements in quantitative results and sets a new state-of-the-art on the popular Brain2Image dataset.
PixelSNE: Visualizing Fast with Just Enough Precision via Pixel-Aligned Stochastic Neighbor Embedding
Mar 03, 2017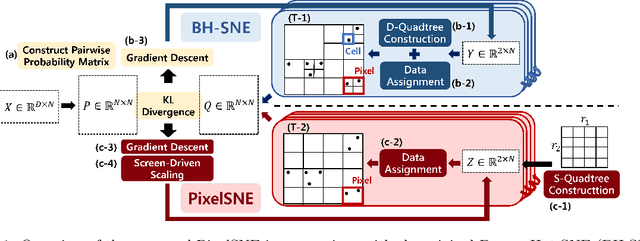
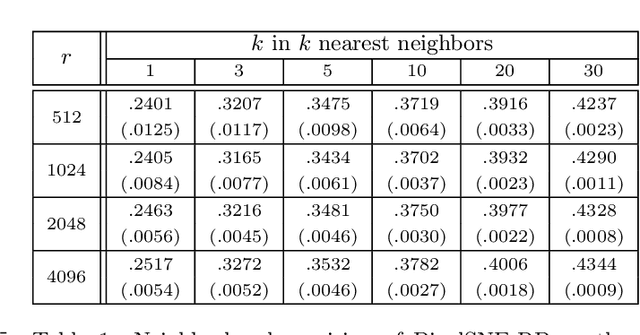
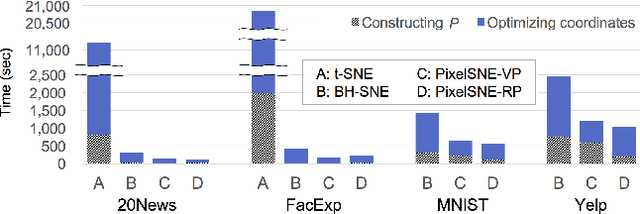
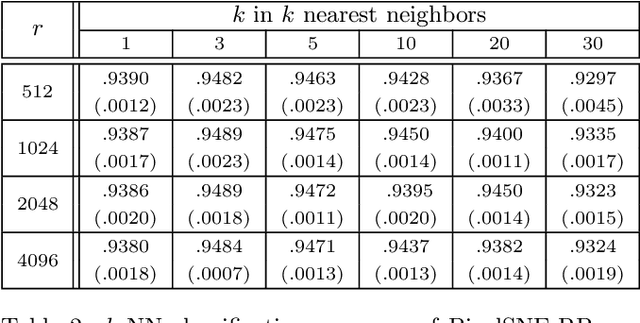
Embedding and visualizing large-scale high-dimensional data in a two-dimensional space is an important problem since such visualization can reveal deep insights out of complex data. Most of the existing embedding approaches, however, run on an excessively high precision, ignoring the fact that at the end, embedding outputs are converted into coarse-grained discrete pixel coordinates in a screen space. Motivated by such an observation and directly considering pixel coordinates in an embedding optimization process, we accelerate Barnes-Hut tree-based t-distributed stochastic neighbor embedding (BH-SNE), known as a state-of-the-art 2D embedding method, and propose a novel method called PixelSNE, a highly-efficient, screen resolution-driven 2D embedding method with a linear computational complexity in terms of the number of data items. Our experimental results show the significantly fast running time of PixelSNE by a large margin against BH-SNE, while maintaining the minimal degradation in the embedding quality. Finally, the source code of our method is publicly available at https://github.com/awesome-davian/PixelSNE
Manifold Regularized Deep Neural Networks using Adversarial Examples
Jan 14, 2016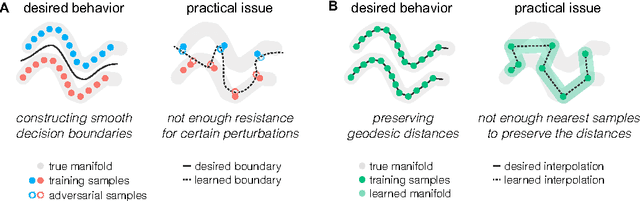
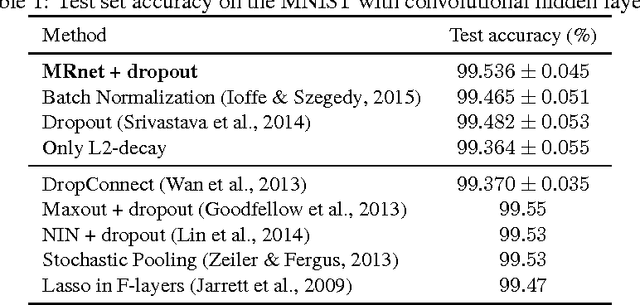

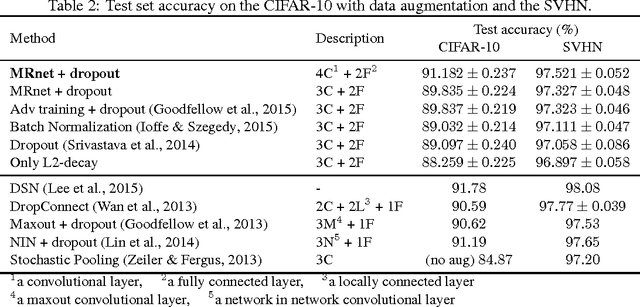
Learning meaningful representations using deep neural networks involves designing efficient training schemes and well-structured networks. Currently, the method of stochastic gradient descent that has a momentum with dropout is one of the most popular training protocols. Based on that, more advanced methods (i.e., Maxout and Batch Normalization) have been proposed in recent years, but most still suffer from performance degradation caused by small perturbations, also known as adversarial examples. To address this issue, we propose manifold regularized networks (MRnet) that utilize a novel training objective function that minimizes the difference between multi-layer embedding results of samples and those adversarial. Our experimental results demonstrated that MRnet is more resilient to adversarial examples and helps us to generalize representations on manifolds. Furthermore, combining MRnet and dropout allowed us to achieve competitive classification performances for three well-known benchmarks: MNIST, CIFAR-10, and SVHN.