 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly as Non-Conformity via Training-Free Graph Laplacian Energy Minimization
May 27, 2026Detecting subtle visual anomalies in images remains challenging, particularly when only normal samples are available a priori. Such unsupervised anomaly detection is typically solved by measuring feature similarity of a query patch to a memory of normal patches. However, similarity alone does not reveal how strongly a query patch violates the structure of the normal feature manifold. We propose a training-free Laplacian graph energy optimization formulation, named ANoCo that scores Anomaly by the cost of Non-Conformity of a query patch to align with a fixed normal manifold. For each query patch, we construct a bipartite query to normal graph weighted by cosine affinity, explicitly removing query-query and normal-normal edges to prevent evidence dilution. We formulate anomaly scoring as a convex Laplacian energy with anchored normal nodes, and solve in closed form. In particular, we do not use the optimized features themselves-the anomaly score is the magnitude of the update required to satisfy normality constraints, reframing the graph Laplacian as a non-conformity operator rather than a smoothing prior. The proposed method introduces no learnable parameters, message passing, or sampling, and has complexity comparable to a single linear solve. Across standard benchmarks, it delivers strong image-level AUROC, stable localization maps, and improved robustness over prior methods, demonstrating the effectiveness of using optimization-induced feature drift as anomaly measure.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Sparse Bayesian Message Passing under Structural Uncertainty
Jan 03, 2026Semi-supervised learning on real-world graphs is frequently challenged by heterophily, where the observed graph is unreliable or label-disassortative. Many existing graph neural networks either rely on a fixed adjacency structure or attempt to handle structural noise through regularization. In this work, we explicitly capture structural uncertainty by modeling a posterior distribution over signed adjacency matrices, allowing each edge to be positive, negative, or absent. We propose a sparse signed message passing network that is naturally robust to edge noise and heterophily, which can be interpreted from a Bayesian perspective. By combining (i) posterior marginalization over signed graph structures with (ii) sparse signed message aggregation, our approach offers a principled way to handle both edge noise and heterophily. Experimental results demonstrate that our method outperforms strong baseline models on heterophilic benchmarks under both synthetic and real-world structural noise.
Edge-boosted graph learning for functional brain connectivity analysis
Apr 21, 2025Predicting disease states from functional brain connectivity is critical for the early diagnosis of severe neurodegenerative diseases such as Alzheimer's Disease and Parkinson's Disease. Existing studies commonly employ Graph Neural Networks (GNNs) to infer clinical diagnoses from node-based brain connectivity matrices generated through node-to-node similarities of regionally averaged fMRI signals. However, recent neuroscience studies found that such node-based connectivity does not accurately capture ``functional connections" within the brain. This paper proposes a novel approach to brain network analysis that emphasizes edge functional connectivity (eFC), shifting the focus to inter-edge relationships. Additionally, we introduce a co-embedding technique to integrate edge functional connections effectively. Experimental results on the ADNI and PPMI datasets demonstrate that our method significantly outperforms state-of-the-art GNN methods in classifying functional brain networks.
Learning Covariance-Based Multi-Scale Representation of Neuroimaging Measures for Alzheimer Classification
Mar 03, 2025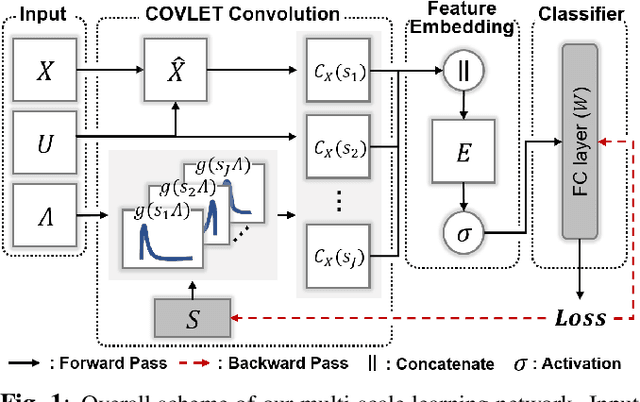
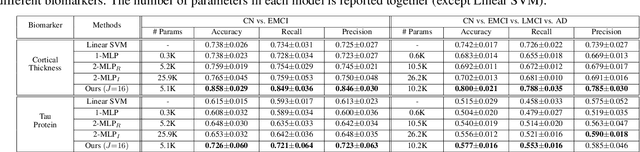

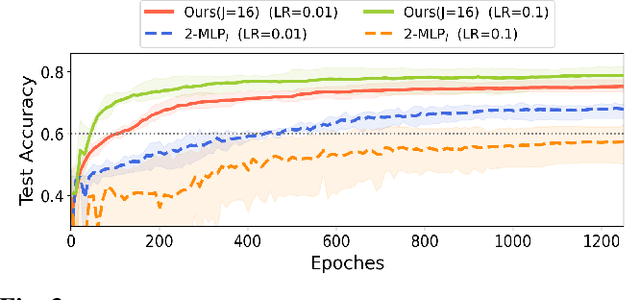
Stacking excessive layers in DNN results in highly underdetermined system when training samples are limited, which is very common in medical applications. In this regard, we present a framework capable of deriving an efficient high-dimensional space with reasonable increase in model size. This is done by utilizing a transform (i.e., convolution) that leverages scale-space theory with covariance structure. The overall model trains on this transform together with a downstream classifier (i.e., Fully Connected layer) to capture the optimal multi-scale representation of the original data which corresponds to task-specific components in a dual space. Experiments on neuroimaging measures from Alzheimer's Disease Neuroimaging Initiative (ADNI) study show that our model performs better and converges faster than conventional models even when the model size is significantly reduced. The trained model is made interpretable using gradient information over the multi-scale transform to delineate personalized AD-specific regions in the brain.
Modality-Agnostic Style Transfer for Holistic Feature Imputation
Mar 03, 2025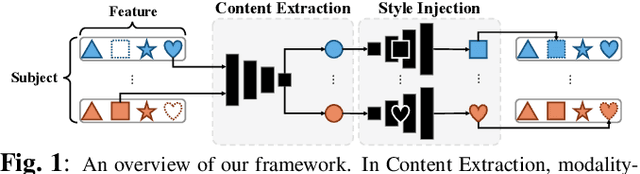
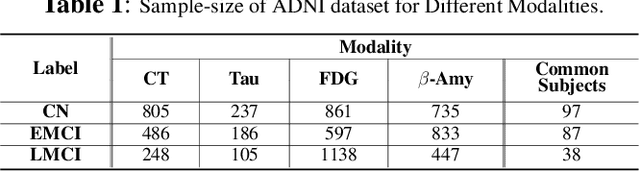
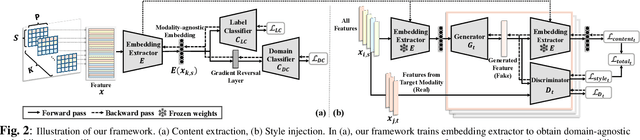
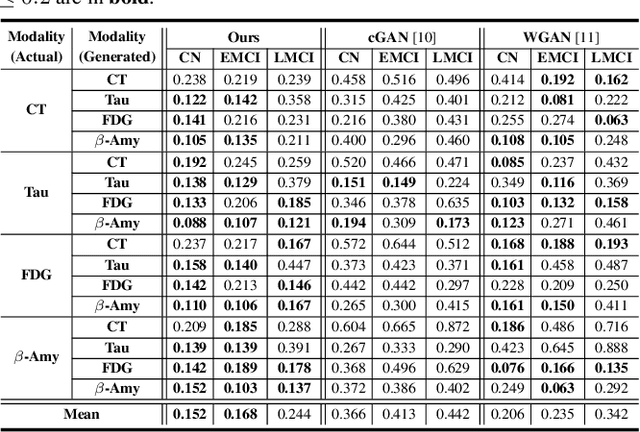
Characterizing a preclinical stage of Alzheimer's Disease (AD) via single imaging is difficult as its early symptoms are quite subtle. Therefore, many neuroimaging studies are curated with various imaging modalities, e.g., MRI and PET, however, it is often challenging to acquire all of them from all subjects and missing data become inevitable. In this regards, in this paper, we propose a framework that generates unobserved imaging measures for specific subjects using their existing measures, thereby reducing the need for additional examinations. Our framework transfers modality-specific style while preserving AD-specific content. This is done by domain adversarial training that preserves modality-agnostic but AD-specific information, while a generative adversarial network adds an indistinguishable modality-specific style. Our proposed framework is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ADNI) study and compared with other imputation methods in terms of generated data quality. Small average Cohen's $d$ $< 0.19$ between our generated measures and real ones suggests that the synthetic data are practically usable regardless of their modality type.
Building Trust Through Voice: How Vocal Tone Impacts User Perception of Attractiveness of Voice Assistants
Sep 27, 2024



Voice Assistants (VAs) are popular for simple tasks, but users are often hesitant to use them for complex activities like online shopping. We explored whether the vocal characteristics like the VA's vocal tone, can make VAs perceived as more attractive and trustworthy to users for complex tasks. Our findings show that the tone of the VA voice significantly impacts its perceived attractiveness and trustworthiness. Participants in our experiment were more likely to be attracted to VAs with positive or neutral tones and ultimately trusted the VAs they found more attractive. We conclude that VA's perceived trustworthiness can be enhanced through thoughtful voice design, incorporating a variety of vocal tones.
Re-Think and Re-Design Graph Neural Networks in Spaces of Continuous Graph Diffusion Functionals
Jul 01, 2023



Graph neural networks (GNNs) are widely used in domains like social networks and biological systems. However, the locality assumption of GNNs, which limits information exchange to neighboring nodes, hampers their ability to capture long-range dependencies and global patterns in graphs. To address this, we propose a new inductive bias based on variational analysis, drawing inspiration from the Brachistochrone problem. Our framework establishes a mapping between discrete GNN models and continuous diffusion functionals. This enables the design of application-specific objective functions in the continuous domain and the construction of discrete deep models with mathematical guarantees. To tackle over-smoothing in GNNs, we analyze the existing layer-by-layer graph embedding models and identify that they are equivalent to l2-norm integral functionals of graph gradients, which cause over-smoothing. Similar to edge-preserving filters in image denoising, we introduce total variation (TV) to align the graph diffusion pattern with global community topologies. Additionally, we devise a selective mechanism to address the trade-off between model depth and over-smoothing, which can be easily integrated into existing GNNs. Furthermore, we propose a novel generative adversarial network (GAN) that predicts spreading flows in graphs through a neural transport equation. To mitigate vanishing flows, we customize the objective function to minimize transportation within each community while maximizing inter-community flows. Our GNN models achieve state-of-the-art (SOTA) performance on popular graph learning benchmarks such as Cora, Citeseer, and Pubmed.
Enhancing Breast Cancer Risk Prediction by Incorporating Prior Images
Mar 28, 2023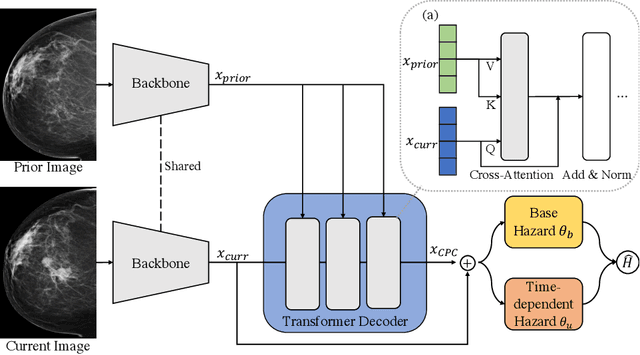
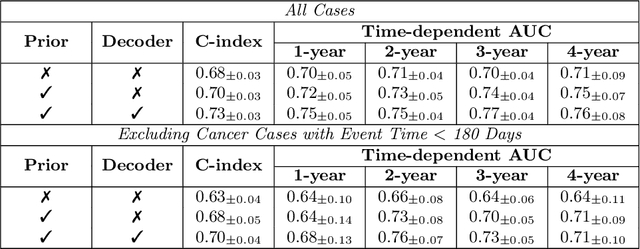
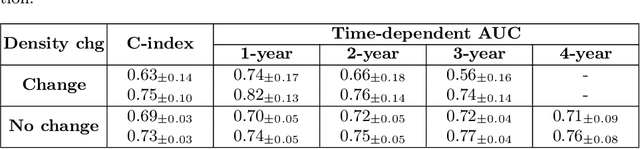
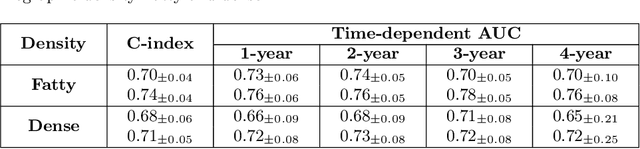
Recently, deep learning models have shown the potential to predict breast cancer risk and enable targeted screening strategies, but current models do not consider the change in the breast over time. In this paper, we present a new method, PRIME+, for breast cancer risk prediction that leverages prior mammograms using a transformer decoder, outperforming a state-of-the-art risk prediction method that only uses mammograms from a single time point. We validate our approach on a dataset with 16,113 exams and further demonstrate that it effectively captures patterns of changes from prior mammograms, such as changes in breast density, resulting in improved short-term and long-term breast cancer risk prediction. Experimental results show that our model achieves a statistically significant improvement in performance over the state-of-the-art based model, with a C-index increase from 0.68 to 0.73 (p < 0.05) on held-out test sets.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023

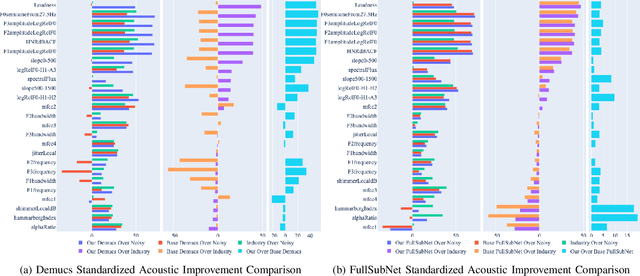

In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.