 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQ-Whisper: Speaker-Querying based Whisper Model for Target-Speaker ASR
Dec 07, 2024Benefiting from massive and diverse data sources, speech foundation models exhibit strong generalization and knowledge transfer capabilities to a wide range of downstream tasks. However, a limitation arises from their exclusive handling of single-speaker speech input, making them ineffective in recognizing multi-speaker overlapped speech, a common occurrence in real-world scenarios. In this study, we delve into the adaptation of speech foundation models to eliminate interfering speakers from overlapping speech and perform target-speaker automatic speech recognition (TS-ASR). Initially, we utilize the Whisper model as the foundation for adaptation and conduct a thorough comparison of its integration with existing target-speaker adaptation techniques. We then propose an innovative model termed Speaker-Querying Whisper (SQ-Whisper), which employs a set number of trainable queries to capture speaker prompts from overlapping speech based on target-speaker enrollment. These prompts serve to steer the model in extracting speaker-specific features and accurately recognizing target-speaker transcriptions. Experimental results demonstrate that our approach effectively adapts the pre-trained speech foundation model to TS-ASR. Compared with the robust TS-HuBERT model, the proposed SQ-Whisper significantly improves performance, yielding up to 15% and 10% relative reductions in word error rates (WERs) on the Libri2Mix and WSJ0-2Mix datasets, respectively. With data augmentation, we establish new state-of-the-art WERs of 14.6% on the Libri2Mix Test set and 4.4% on the WSJ0-2Mix Test set. Furthermore, we evaluate our model on the real-world AMI meeting dataset, which shows consistent improvement over other adaptation methods.
SynesLM: A Unified Approach for Audio-visual Speech Recognition and Translation via Language Model and Synthetic Data
Aug 01, 2024In this work, we present SynesLM, an unified model which can perform three multimodal language understanding tasks: audio-visual automatic speech recognition(AV-ASR) and visual-aided speech/machine translation(VST/VMT). Unlike previous research that focused on lip motion as visual cues for speech signals, our work explores more general visual information within entire frames, such as objects and actions. Additionally, we use synthetic image data to enhance the correlation between image and speech data. We benchmark SynesLM against the How2 dataset, demonstrating performance on par with state-of-the-art (SOTA) models dedicated to AV-ASR while maintaining our multitasking framework. Remarkably, for zero-shot AV-ASR, SynesLM achieved SOTA performance by lowering the Word Error Rate (WER) from 43.4% to 39.4% on the VisSpeech Dataset. Furthermore, our results in VST and VMT outperform the previous results, improving the BLEU score to 43.5 from 37.2 for VST, and to 54.8 from 54.4 for VMT.
The CHiME-8 DASR Challenge for Generalizable and Array Agnostic Distant Automatic Speech Recognition and Diarization
Jul 23, 2024



This paper presents the CHiME-8 DASR challenge which carries on from the previous edition CHiME-7 DASR (C7DASR) and the past CHiME-6 challenge. It focuses on joint multi-channel distant speech recognition (DASR) and diarization with one or more, possibly heterogeneous, devices. The main goal is to spur research towards meeting transcription approaches that can generalize across arbitrary number of speakers, diverse settings (formal vs. informal conversations), meeting duration, wide-variety of acoustic scenarios and different recording configurations. Novelties with respect to C7DASR include: i) the addition of NOTSOFAR-1, an additional office/corporate meeting scenario, ii) a manually corrected Mixer 6 development set, iii) a new track in which we allow the use of large-language models (LLM) iv) a jury award mechanism to encourage participants to explore also more practical and innovative solutions. To lower the entry barrier for participants, we provide a standalone toolkit for downloading and preparing such datasets as well as performing text normalization and scoring their submissions. Furthermore, this year we also provide two baseline systems, one directly inherited from C7DASR and based on ESPnet and another one developed on NeMo and based on NeMo team submission in last year C7DASR. Baseline system results suggest that the addition of the NOTSOFAR-1 scenario significantly increases the task's difficulty due to its high number of speakers and very short duration.
Towards Robust Speech Representation Learning for Thousands of Languages
Jul 02, 2024Self-supervised learning (SSL) has helped extend speech technologies to more languages by reducing the need for labeled data. However, models are still far from supporting the world's 7000+ languages. We propose XEUS, a Cross-lingual Encoder for Universal Speech, trained on over 1 million hours of data across 4057 languages, extending the language coverage of SSL models 4-fold. We combine 1 million hours of speech from existing publicly accessible corpora with a newly created corpus of 7400+ hours from 4057 languages, which will be publicly released. To handle the diverse conditions of multilingual speech data, we augment the typical SSL masked prediction approach with a novel dereverberation objective, increasing robustness. We evaluate XEUS on several benchmarks, and show that it consistently outperforms or achieves comparable results to state-of-the-art (SOTA) SSL models across a variety of tasks. XEUS sets a new SOTA on the ML-SUPERB benchmark: it outperforms MMS 1B and w2v-BERT 2.0 v2 by 0.8% and 4.4% respectively, despite having less parameters or pre-training data. Checkpoints, code, and data are found in https://www.wavlab.org/activities/2024/xeus/.
ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages, and Datasets
Jun 12, 2024



ML-SUPERB evaluates self-supervised learning (SSL) models on the tasks of language identification and automatic speech recognition (ASR). This benchmark treats the models as feature extractors and uses a single shallow downstream model, which can be fine-tuned for a downstream task. However, real-world use cases may require different configurations. This paper presents ML-SUPERB~2.0, which is a new benchmark for evaluating pre-trained SSL and supervised speech models across downstream models, fine-tuning setups, and efficient model adaptation approaches. We find performance improvements over the setup of ML-SUPERB. However, performance depends on the downstream model design. Also, we find large performance differences between languages and datasets, suggesting the need for more targeted approaches to improve multilingual ASR performance.
The Interspeech 2024 Challenge on Speech Processing Using Discrete Units
Jun 11, 2024



Representing speech and audio signals in discrete units has become a compelling alternative to traditional high-dimensional feature vectors. Numerous studies have highlighted the efficacy of discrete units in various applications such as speech compression and restoration, speech recognition, and speech generation. To foster exploration in this domain, we introduce the Interspeech 2024 Challenge, which focuses on new speech processing benchmarks using discrete units. It encompasses three pivotal tasks, namely multilingual automatic speech recognition, text-to-speech, and singing voice synthesis, and aims to assess the potential applicability of discrete units in these tasks. This paper outlines the challenge designs and baseline descriptions. We also collate baseline and selected submission systems, along with preliminary findings, offering valuable contributions to future research in this evolving field.
A Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
LV-CTC: Non-autoregressive ASR with CTC and latent variable models
Mar 28, 2024Non-autoregressive (NAR) models for automatic speech recognition (ASR) aim to achieve high accuracy and fast inference by simplifying the autoregressive (AR) generation process of conventional models. Connectionist temporal classification (CTC) is one of the key techniques used in NAR ASR models. In this paper, we propose a new model combining CTC and a latent variable model, which is one of the state-of-the-art models in the neural machine translation research field. A new neural network architecture and formulation specialized for ASR application are introduced. In the proposed model, CTC alignment is assumed to be dependent on the latent variables that are expected to capture dependencies between tokens. Experimental results on a 100 hours subset of Librispeech corpus showed the best recognition accuracy among CTC-based NAR models. On the TED-LIUM2 corpus, the best recognition accuracy is achieved including AR E2E models with faster inference speed.
TMT: Tri-Modal Translation between Speech, Image, and Text by Processing Different Modalities as Different Languages
Feb 25, 2024



The capability to jointly process multi-modal information is becoming an essential task. However, the limited number of paired multi-modal data and the large computational requirements in multi-modal learning hinder the development. We propose a novel Tri-Modal Translation (TMT) model that translates between arbitrary modalities spanning speech, image, and text. We introduce a novel viewpoint, where we interpret different modalities as different languages, and treat multi-modal translation as a well-established machine translation problem. To this end, we tokenize speech and image data into discrete tokens, which provide a unified interface across modalities and significantly decrease the computational cost. In the proposed TMT, a multi-modal encoder-decoder conducts the core translation, whereas modality-specific processing is conducted only within the tokenization and detokenization stages. We evaluate the proposed TMT on all six modality translation tasks. TMT outperforms single model counterparts consistently, demonstrating that unifying tasks is beneficial not only for practicality but also for performance.
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Jan 30, 2024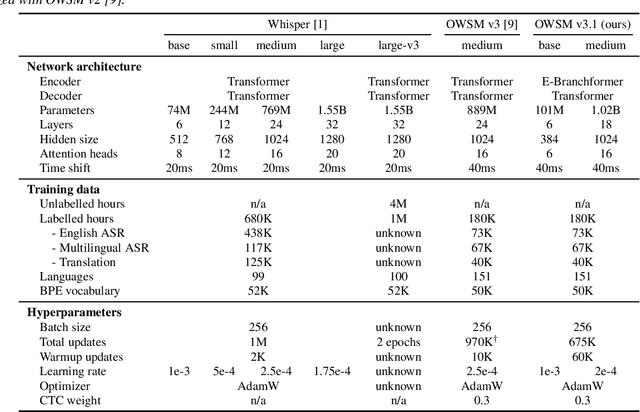
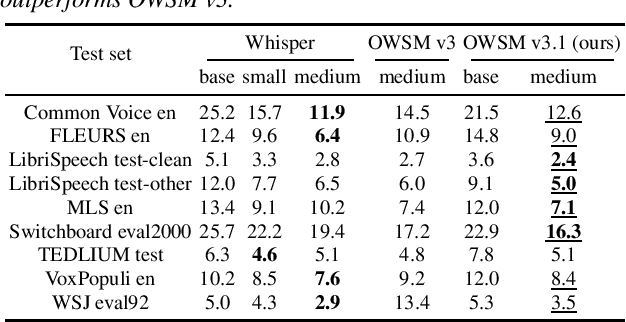
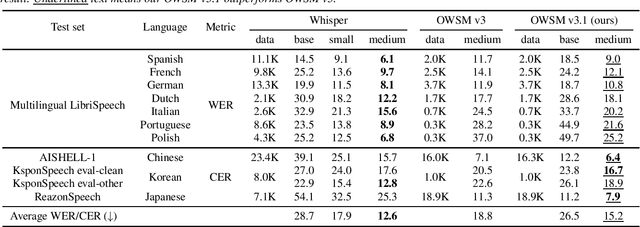
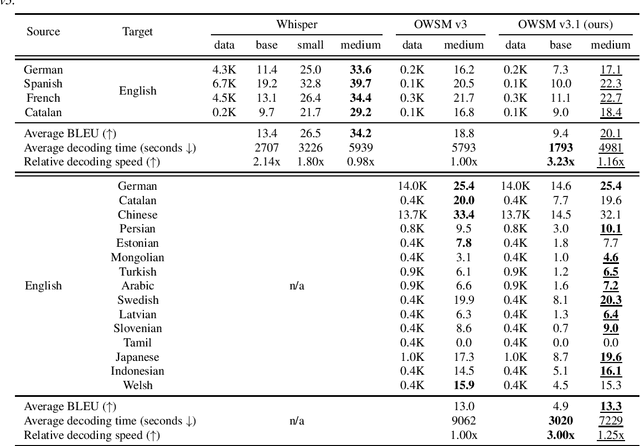
Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed. We publicly release the data preparation scripts, pre-trained models and training logs.