 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Paper and Code
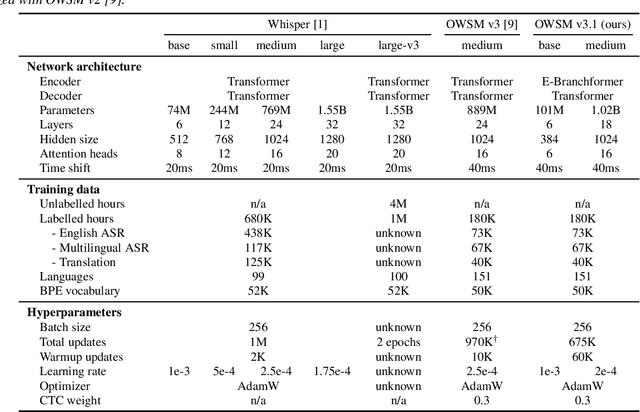
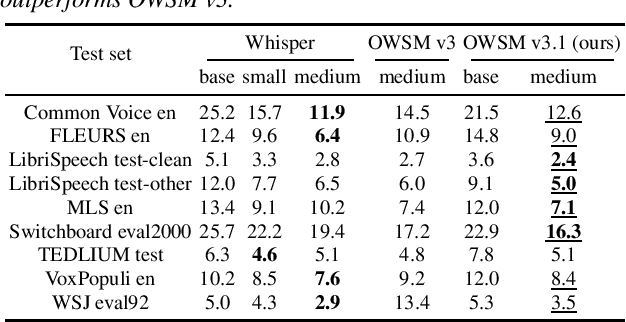
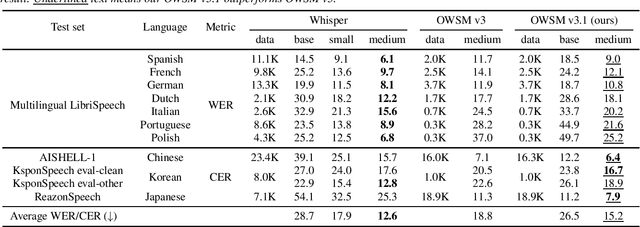
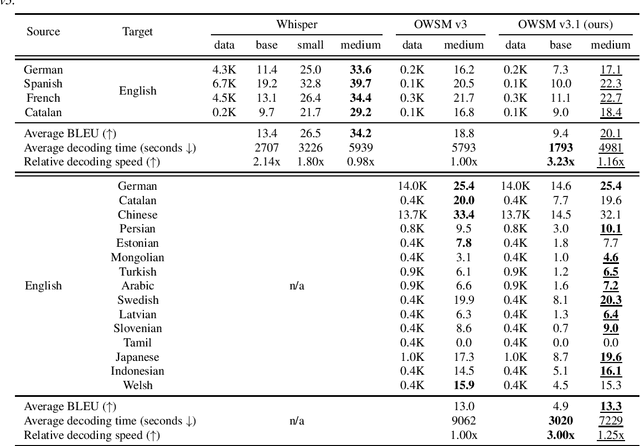
Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed. We publicly release the data preparation scripts, pre-trained models and training logs.