 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Optimizing Conversational Quality in Spoken Dialogue Systems with Reinforcement Learning from AI Feedback
Jan 27, 2026Reinforcement learning from human or AI feedback (RLHF/RLAIF) for speech-in/speech-out dialogue systems (SDS) remains underexplored, with prior work largely limited to single semantic rewards applied at the utterance level. Such setups overlook the multi-dimensional and multi-modal nature of conversational quality, which encompasses semantic coherence, audio naturalness, speaker consistency, emotion alignment, and turn-taking behavior. Moreover, they are fundamentally mismatched with duplex spoken dialogue systems that generate responses incrementally, where agents must make decisions based on partial utterances. We address these limitations with the first multi-reward RLAIF framework for SDS, combining semantic, audio-quality, and emotion-consistency rewards. To align utterance-level preferences with incremental, blockwise decoding in duplex models, we apply turn-level preference sampling and aggregate per-block log-probabilities within a single DPO objective. We present the first systematic study of preference learning for improving SDS quality in both multi-turn Chain-of-Thought and blockwise duplex models, and release a multi-reward DPO dataset to support reproducible research. Experiments show that single-reward RLAIF selectively improves its targeted metric, while joint multi-reward training yields consistent gains across semantic quality and audio naturalness. These results highlight the importance of holistic, multi-reward alignment for practical conversational SDS.
Do Neural Codecs Generalize? A Controlled Study Across Unseen Languages and Non-Speech Tasks
Jan 18, 2026This paper investigates three crucial yet underexplored aspects of the generalization capabilities of neural audio codecs (NACs): (i) whether NACs can generalize to unseen languages during pre-training, (ii) whether speech-only pre-trained NACs can effectively generalize to non-speech applications such as environmental sounds, music, and animal vocalizations, and (iii) whether incorporating non-speech data during pre-training can improve performance on both speech and non-speech tasks. Existing studies typically rely on off-the-shelf NACs for comparison, which limits insight due to variations in implementation. In this work, we train NACs from scratch using strictly controlled configurations and carefully curated pre-training data to enable fair comparisons. We conduct a comprehensive evaluation of NAC performance on both signal reconstruction quality and downstream applications using 11 metrics. Our results show that NACs can generalize to unseen languages during pre-training, speech-only pre-trained NACs exhibit degraded performance on non-speech tasks, and incorporating non-speech data during pre-training improves performance on non-speech tasks while maintaining comparable performance on speech tasks.
IKFST: IOO and KOO Algorithms for Accelerated and Precise WFST-based End-to-End Automatic Speech Recognition
Jan 01, 2026End-to-end automatic speech recognition has become the dominant paradigm in both academia and industry. To enhance recognition performance, the Weighted Finite-State Transducer (WFST) is widely adopted to integrate acoustic and language models through static graph composition, providing robust decoding and effective error correction. However, WFST decoding relies on a frame-by-frame autoregressive search over CTC posterior probabilities, which severely limits inference efficiency. Motivated by establishing a more principled compatibility between WFST decoding and CTC modeling, we systematically study the two fundamental components of CTC outputs, namely blank and non-blank frames, and identify a key insight: blank frames primarily encode positional information, while non-blank frames carry semantic content. Building on this observation, we introduce Keep-Only-One and Insert-Only-One, two decoding algorithms that explicitly exploit the structural roles of blank and non-blank frames to achieve significantly faster WFST-based inference without compromising recognition accuracy. Experiments on large-scale in-house, AISHELL-1, and LibriSpeech datasets demonstrate state-of-the-art recognition accuracy with substantially reduced decoding latency, enabling truly efficient and high-performance WFST decoding in modern speech recognition systems.
BSCodec: A Band-Split Neural Codec for High-Quality Universal Audio Reconstruction
Nov 08, 2025



Neural audio codecs have recently enabled high-fidelity reconstruction at high compression rates, especially for speech. However, speech and non-speech audio exhibit fundamentally different spectral characteristics: speech energy concentrates in narrow bands around pitch harmonics (80-400 Hz), while non-speech audio requires faithful reproduction across the full spectrum, particularly preserving higher frequencies that define timbre and texture. This poses a challenge: speech-optimized neural codecs suffer degradation on music or sound. Treating the full spectrum holistically is suboptimal: frequency bands have vastly different information density and perceptual importance by content type, yet full-band approaches apply uniform capacity across frequencies without accounting for these acoustic structures. To address this gap, we propose BSCodec (Band-Split Codec), a novel neural audio codec architecture that splits the spectral dimension into separate bands and compresses each band independently. Experimental results demonstrate that BSCodec achieves superior reconstruction over baselines across sound and music, while maintaining competitive quality in the speech domain, when trained on the same combined dataset of speech, music and sound. Downstream benchmark tasks further confirm that BSCodec shows strong potential for use in downstream applications.
Full-Duplex-Bench-v2: A Multi-Turn Evaluation Framework for Duplex Dialogue Systems with an Automated Examiner
Oct 09, 2025While full-duplex speech agents enable natural, low-latency interaction by speaking and listening simultaneously, their consistency and task performance in multi-turn settings remain underexplored. We introduce Full-Duplex-Bench-v2 (FDB-v2), a streaming framework that integrates with an automated examiner that enforces staged goals under two pacing setups (Fast vs. Slow). FDB-v2 covers four task families: daily, correction, entity tracking, and safety. We report turn-taking fluency, multi-turn instruction following, and task-specific competence. The framework is extensible, supporting both commercial APIs and open source models. When we test full-duplex systems with FDB-v2, they often get confused when people talk at the same time, struggle to handle corrections smoothly, and sometimes lose track of who or what is being talked about. Through an open-sourced, standardized streaming protocol and a task set, FDB-v2 makes it easy to extend to new task families, allowing the community to tailor and accelerate evaluation of multi-turn full-duplex systems.
Chain-of-Thought Reasoning in Streaming Full-Duplex End-to-End Spoken Dialogue Systems
Oct 02, 2025Most end-to-end (E2E) spoken dialogue systems (SDS) rely on voice activity detection (VAD) for turn-taking, but VAD fails to distinguish between pauses and turn completions. Duplex SDS models address this by predicting output continuously, including silence tokens, thus removing the need for explicit VAD. However, they often have complex dual-channel architecture and lag behind cascaded models in semantic reasoning. To overcome these challenges, we propose SCoT: a Streaming Chain-of-Thought (CoT) framework for Duplex SDS, alternating between processing fixed-duration user input and generating responses in a blockwise manner. Using frame-level alignments, we create intermediate targets-aligned user transcripts and system responses for each block. Experiments show that our approach produces more coherent and interpretable responses than existing duplex methods while supporting lower-latency and overlapping interactions compared to turn-by-turn systems.
SingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025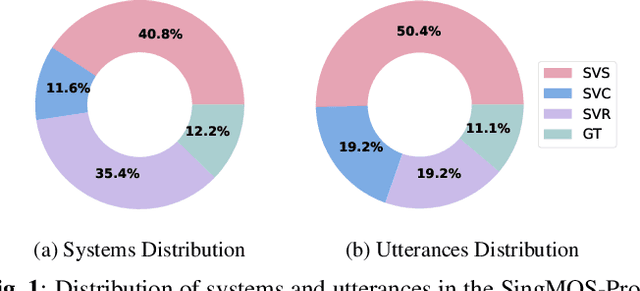

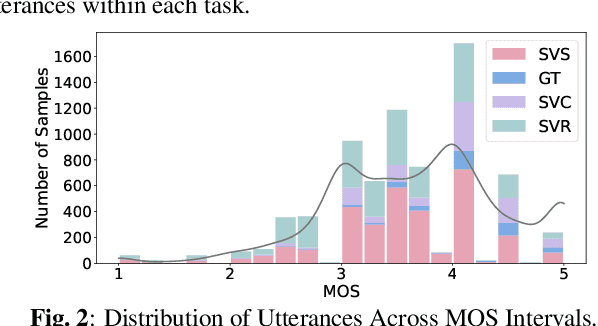

Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
The Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
The ML-SUPERB 2.0 Challenge: Towards Inclusive ASR Benchmarking for All Language Varieties
Sep 08, 2025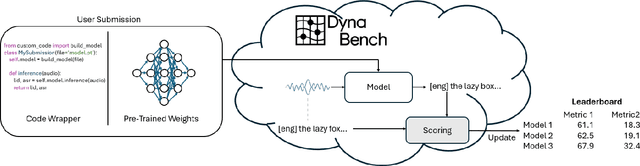
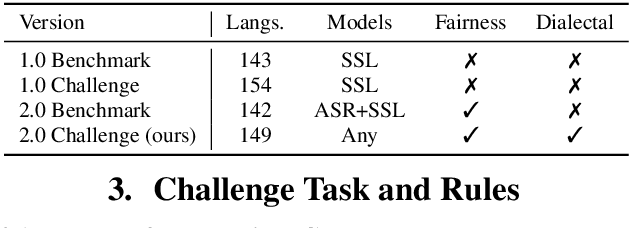
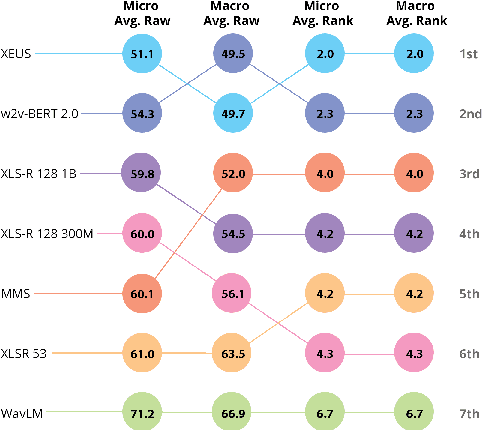
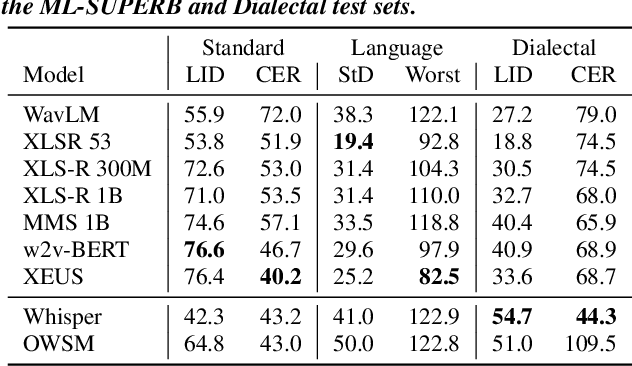
Recent improvements in multilingual ASR have not been equally distributed across languages and language varieties. To advance state-of-the-art (SOTA) ASR models, we present the Interspeech 2025 ML-SUPERB 2.0 Challenge. We construct a new test suite that consists of data from 200+ languages, accents, and dialects to evaluate SOTA multilingual speech models. The challenge also introduces an online evaluation server based on DynaBench, allowing for flexibility in model design and architecture for participants. The challenge received 5 submissions from 3 teams, all of which outperformed our baselines. The best-performing submission achieved an absolute improvement in LID accuracy of 23% and a reduction in CER of 18% when compared to the best baseline on a general multilingual test set. On accented and dialectal data, the best submission obtained 30.2% lower CER and 15.7% higher LID accuracy, showing the importance of community challenges in making speech technologies more inclusive.