 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Mar 11, 2025



Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
When Large Language Models Meet Speech: A Survey on Integration Approaches
Feb 26, 2025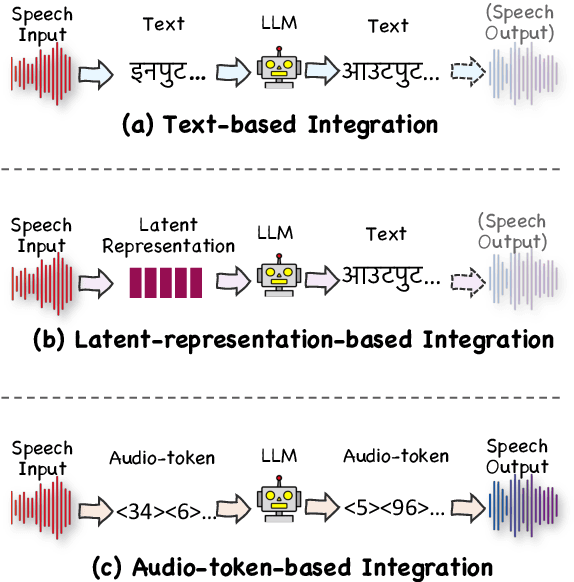
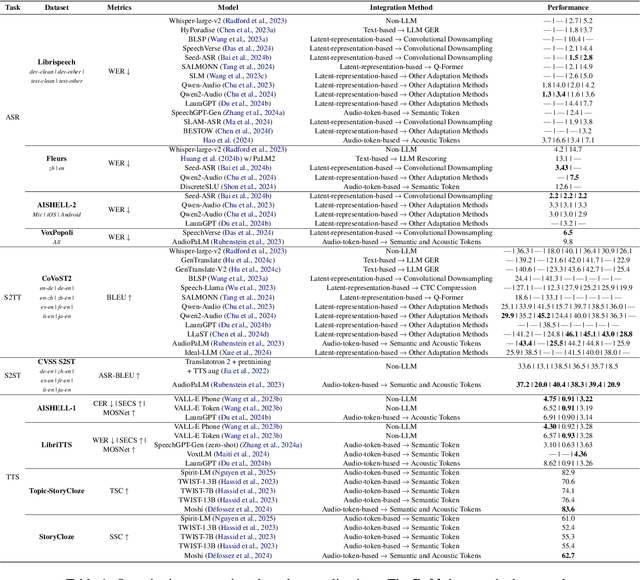
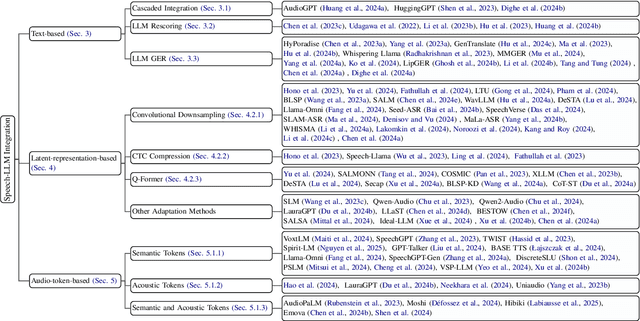
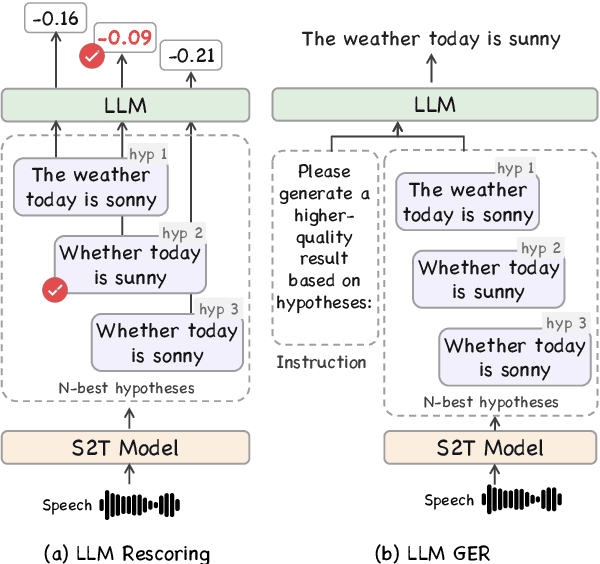
Recent advancements in large language models (LLMs) have spurred interest in expanding their application beyond text-based tasks. A large number of studies have explored integrating other modalities with LLMs, notably speech modality, which is naturally related to text. This paper surveys the integration of speech with LLMs, categorizing the methodologies into three primary approaches: text-based, latent-representation-based, and audio-token-based integration. We also demonstrate how these methods are applied across various speech-related applications and highlight the challenges in this field to offer inspiration for
MELD-ST: An Emotion-aware Speech Translation Dataset
May 21, 2024Emotion plays a crucial role in human conversation. This paper underscores the significance of considering emotion in speech translation. We present the MELD-ST dataset for the emotion-aware speech translation task, comprising English-to-Japanese and English-to-German language pairs. Each language pair includes about 10,000 utterances annotated with emotion labels from the MELD dataset. Baseline experiments using the SeamlessM4T model on the dataset indicate that fine-tuning with emotion labels can enhance translation performance in some settings, highlighting the need for further research in emotion-aware speech translation systems.
SlideAVSR: A Dataset of Paper Explanation Videos for Audio-Visual Speech Recognition
Jan 18, 2024



Audio-visual speech recognition (AVSR) is a multimodal extension of automatic speech recognition (ASR), using video as a complement to audio. In AVSR, considerable efforts have been directed at datasets for facial features such as lip-readings, while they often fall short in evaluating the image comprehension capabilities in broader contexts. In this paper, we construct SlideAVSR, an AVSR dataset using scientific paper explanation videos. SlideAVSR provides a new benchmark where models transcribe speech utterances with texts on the slides on the presentation recordings. As technical terminologies that are frequent in paper explanations are notoriously challenging to transcribe without reference texts, our SlideAVSR dataset spotlights a new aspect of AVSR problems. As a simple yet effective baseline, we propose DocWhisper, an AVSR model that can refer to textual information from slides, and confirm its effectiveness on SlideAVSR.
Video-Helpful Multimodal Machine Translation
Oct 31, 2023Existing multimodal machine translation (MMT) datasets consist of images and video captions or instructional video subtitles, which rarely contain linguistic ambiguity, making visual information ineffective in generating appropriate translations. Recent work has constructed an ambiguous subtitles dataset to alleviate this problem but is still limited to the problem that videos do not necessarily contribute to disambiguation. We introduce EVA (Extensive training set and Video-helpful evaluation set for Ambiguous subtitles translation), an MMT dataset containing 852k Japanese-English (Ja-En) parallel subtitle pairs, 520k Chinese-English (Zh-En) parallel subtitle pairs, and corresponding video clips collected from movies and TV episodes. In addition to the extensive training set, EVA contains a video-helpful evaluation set in which subtitles are ambiguous, and videos are guaranteed helpful for disambiguation. Furthermore, we propose SAFA, an MMT model based on the Selective Attention model with two novel methods: Frame attention loss and Ambiguity augmentation, aiming to use videos in EVA for disambiguation fully. Experiments on EVA show that visual information and the proposed methods can boost translation performance, and our model performs significantly better than existing MMT models. The EVA dataset and the SAFA model are available at: https://github.com/ku-nlp/video-helpful-MMT.git.
Towards Speech Dialogue Translation Mediating Speakers of Different Languages
May 22, 2023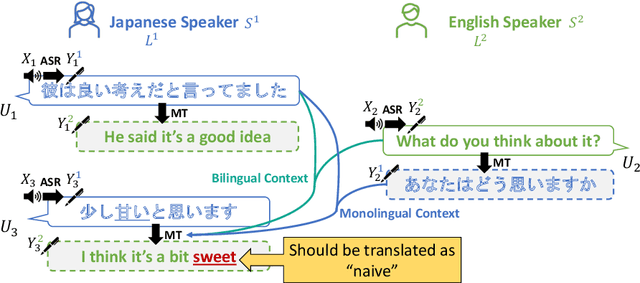
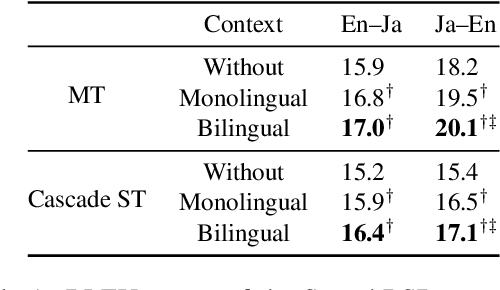


We present a new task, speech dialogue translation mediating speakers of different languages. We construct the SpeechBSD dataset for the task and conduct baseline experiments. Furthermore, we consider context to be an important aspect that needs to be addressed in this task and propose two ways of utilizing context, namely monolingual context and bilingual context. We conduct cascaded speech translation experiments using Whisper and mBART, and show that bilingual context performs better in our settings.
VISA: An Ambiguous Subtitles Dataset for Visual Scene-Aware Machine Translation
Jan 21, 2022


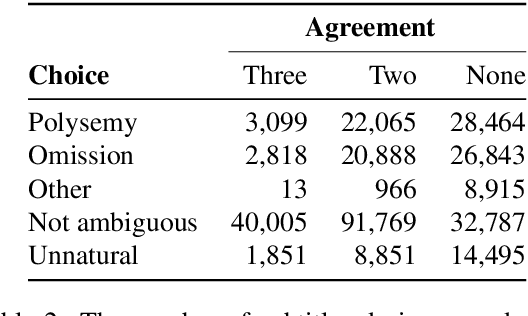
Existing multimodal machine translation (MMT) datasets consist of images and video captions or general subtitles, which rarely contain linguistic ambiguity, making visual information not so effective to generate appropriate translations. We introduce VISA, a new dataset that consists of 40k Japanese-English parallel sentence pairs and corresponding video clips with the following key features: (1) the parallel sentences are subtitles from movies and TV episodes; (2) the source subtitles are ambiguous, which means they have multiple possible translations with different meanings; (3) we divide the dataset into Polysemy and Omission according to the cause of ambiguity. We show that VISA is challenging for the latest MMT system, and we hope that the dataset can facilitate MMT research.