 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Speech-to-Speech Translation Models
Jun 02, 2026Speech-to-speech translation (S2ST) has advanced rapidly, but offline evaluation lacks a unified protocol: studies report non-overlapping metric subsets, preventing direct comparisons. We introduce COMPASS, a unified and reproducible benchmarking framework integrating 46 metrics across eight dimensions, and deploy it on 1,248 model-language configurations from FLEURS and CVSS, spanning cascaded and end-to-end architectures over ten language pairs. Architectures exhibit complementary strengths: best-vs-worst gaps exceed 30\% on naturalness and speaker preservation but remain within a few points on translation quality, so single-metric rankings systematically misrepresent system quality. Correlation filtering reduces 46 metrics to 10 per direction, with three axes requiring different metrics across X$\to$EN and EN$\to$X (e.g., TER/UTMOS vs. ChrF++/NISQA-MOS); these subsets preserve rankings (Spearman's $ρ>0.80$) while cutting evaluation time by $\approx 2.5\times$. Human validation across dubbing, podcasts, and medical domains shows standalone MOS predictors fail to predict listener preference, while top domain-specific metrics correlate with human judgment ($ρ\geq 0.90$). We release COMPASS as a foundation for domain-aware S2ST evaluation.
DialogueSidon: Recovering Full-Duplex Dialogue Tracks from In-the-Wild Dialogue Audio
Apr 13, 2026Full-duplex dialogue audio, in which each speaker is recorded on a separate track, is an important resource for spoken dialogue research, but is difficult to collect at scale. Most in-the-wild two-speaker dialogue is available only as degraded monaural mixtures, making it unsuitable for systems requiring clean speaker-wise signals. We propose DialogueSidon, a model for joint restoration and separation of degraded monaural two-speaker dialogue audio. DialogueSidon combines a variational autoencoder (VAE) operates on the speech self-supervised learning (SSL) model feature, which compresses SSL model features into a compact latent space, with a diffusion-based latent predictor that recovers speaker-wise latent representations from the degraded mixture. Experiments on English, multilingual, and in-the-wild dialogue datasets show that DialogueSidon substantially improves intelligibility and separation quality over a baseline, while also achieving much faster inference.
Optimizing Conversational Quality in Spoken Dialogue Systems with Reinforcement Learning from AI Feedback
Jan 27, 2026Reinforcement learning from human or AI feedback (RLHF/RLAIF) for speech-in/speech-out dialogue systems (SDS) remains underexplored, with prior work largely limited to single semantic rewards applied at the utterance level. Such setups overlook the multi-dimensional and multi-modal nature of conversational quality, which encompasses semantic coherence, audio naturalness, speaker consistency, emotion alignment, and turn-taking behavior. Moreover, they are fundamentally mismatched with duplex spoken dialogue systems that generate responses incrementally, where agents must make decisions based on partial utterances. We address these limitations with the first multi-reward RLAIF framework for SDS, combining semantic, audio-quality, and emotion-consistency rewards. To align utterance-level preferences with incremental, blockwise decoding in duplex models, we apply turn-level preference sampling and aggregate per-block log-probabilities within a single DPO objective. We present the first systematic study of preference learning for improving SDS quality in both multi-turn Chain-of-Thought and blockwise duplex models, and release a multi-reward DPO dataset to support reproducible research. Experiments show that single-reward RLAIF selectively improves its targeted metric, while joint multi-reward training yields consistent gains across semantic quality and audio naturalness. These results highlight the importance of holistic, multi-reward alignment for practical conversational SDS.
Chain-of-Thought Reasoning in Streaming Full-Duplex End-to-End Spoken Dialogue Systems
Oct 02, 2025Most end-to-end (E2E) spoken dialogue systems (SDS) rely on voice activity detection (VAD) for turn-taking, but VAD fails to distinguish between pauses and turn completions. Duplex SDS models address this by predicting output continuously, including silence tokens, thus removing the need for explicit VAD. However, they often have complex dual-channel architecture and lag behind cascaded models in semantic reasoning. To overcome these challenges, we propose SCoT: a Streaming Chain-of-Thought (CoT) framework for Duplex SDS, alternating between processing fixed-duration user input and generating responses in a blockwise manner. Using frame-level alignments, we create intermediate targets-aligned user transcripts and system responses for each block. Experiments show that our approach produces more coherent and interpretable responses than existing duplex methods while supporting lower-latency and overlapping interactions compared to turn-by-turn systems.
LibriTTS-VI: A Public Corpus and Novel Methods for Efficient Voice Impression Control
Sep 19, 2025Fine-grained control over voice impressions (e.g., making a voice brighter or calmer) is a key frontier for creating more controllable text-to-speech. However, this nascent field faces two key challenges. The first is the problem of impression leakage, where the synthesized voice is undesirably influenced by the speaker's reference audio, rather than the separately specified target impression, and the second is the lack of a public, annotated corpus. To mitigate impression leakage, we propose two methods: 1) a training strategy that separately uses an utterance for speaker identity and another utterance of the same speaker for target impression, and 2) a novel reference-free model that generates a speaker embedding solely from the target impression, achieving the benefits of improved robustness against the leakage and the convenience of reference-free generation. Objective and subjective evaluations demonstrate a significant improvement in controllability. Our best method reduced the mean squared error of 11-dimensional voice impression vectors from 0.61 to 0.41 objectively and from 1.15 to 0.92 subjectively, while maintaining high fidelity. To foster reproducible research, we introduce LibriTTS-VI, the first public voice impression dataset released with clear annotation standards, built upon the LibriTTS-R corpus.
Scheduled Interleaved Speech-Text Training for Speech-to-Speech Translation with LLMs
Jun 12, 2025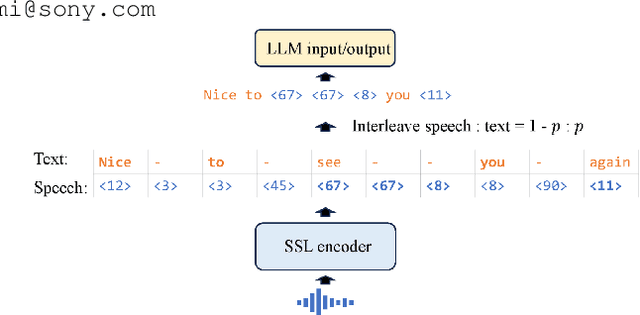

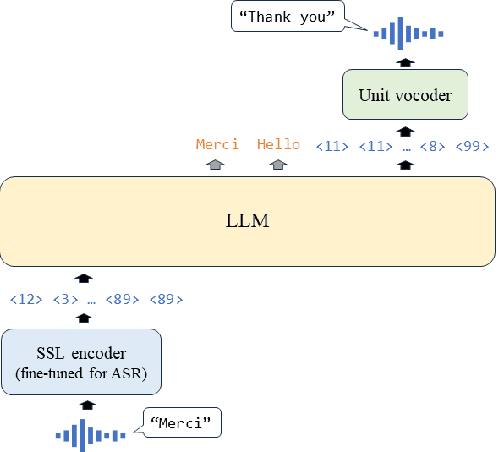
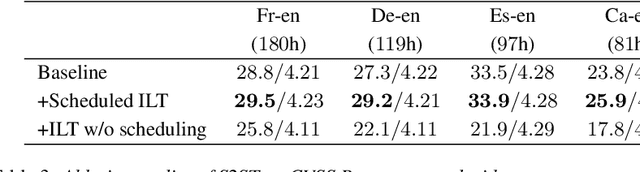
Speech-to-speech translation (S2ST) has been advanced with large language models (LLMs), which are fine-tuned on discrete speech units. In such approaches, modality adaptation from text to speech has been an issue. LLMs are trained on text-only data, which presents challenges to adapt them to speech modality with limited speech-to-speech data. To address the training difficulty, we propose scheduled interleaved speech--text training in this study. We use interleaved speech--text units instead of speech units during training, where aligned text tokens are interleaved at the word level. We gradually decrease the ratio of text as training progresses, to facilitate progressive modality adaptation from text to speech. We conduct experimental evaluations by fine-tuning LLaMA3.2-1B for S2ST on the CVSS dataset. We show that the proposed method consistently improves the translation performances, especially for languages with limited training data.
Differentiable K-means for Fully-optimized Discrete Token-based ASR
May 22, 2025Recent studies have highlighted the potential of discrete tokens derived from self-supervised learning (SSL) models for various speech-related tasks. These tokens serve not only as substitutes for text in language modeling but also as intermediate representations for tasks such as automatic speech recognition (ASR). However, discrete tokens are typically obtained via k-means clustering of SSL features independently of downstream tasks, making them suboptimal for specific applications. This paper proposes the use of differentiable k-means, enabling the joint optimization of tokenization and downstream tasks. This approach enables the fine-tuning of the SSL parameters and learning weights for outputs from multiple SSL layers. Experiments were conducted with ASR as a downstream task. ASR accuracy successfully improved owing to the optimized tokens. The acquired tokens also exhibited greater purity of phonetic information, which were found to be useful even in speech resynthesis.
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Mar 11, 2025



Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
Causal Speech Enhancement with Predicting Semantics based on Quantized Self-supervised Learning Features
Dec 26, 2024Real-time speech enhancement (SE) is essential to online speech communication. Causal SE models use only the previous context while predicting future information, such as phoneme continuation, may help performing causal SE. The phonetic information is often represented by quantizing latent features of self-supervised learning (SSL) models. This work is the first to incorporate SSL features with causality into an SE model. The causal SSL features are encoded and combined with spectrogram features using feature-wise linear modulation to estimate a mask for enhancing the noisy input speech. Simultaneously, we quantize the causal SSL features using vector quantization to represent phonetic characteristics as semantic tokens. The model not only encodes SSL features but also predicts the future semantic tokens in multi-task learning (MTL). The experimental results using VoiceBank + DEMAND dataset show that our proposed method achieves 2.88 in PESQ, especially with semantic prediction MTL, in which we confirm that the semantic prediction played an important role in causal SE.
Task Arithmetic for Language Expansion in Speech Translation
Sep 17, 2024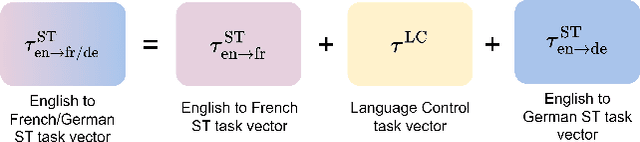
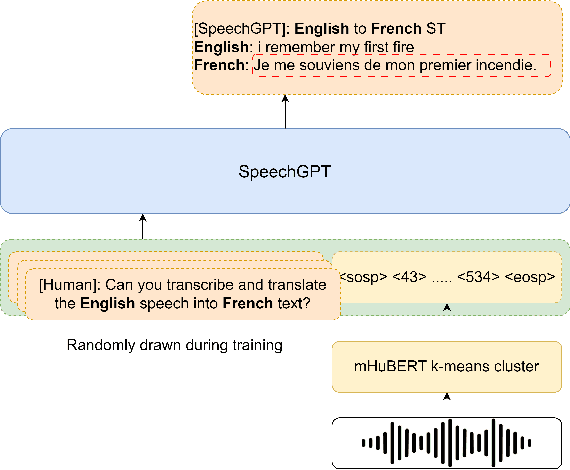


Recent advances in large language models (LLMs) have gained interest in speech-text multimodal foundation models, achieving strong performance on instruction-based speech translation (ST). However, expanding language pairs from an existing instruction-tuned ST system is costly due to the necessity of re-training on a combination of new and previous datasets. We propose to expand new language pairs by merging the model trained on new language pairs and the existing model, using task arithmetic. We find that the direct application of task arithmetic for ST causes the merged model to fail to follow instructions; thus, generating translation in incorrect languages. To eliminate language confusion, we propose an augmented task arithmetic method that merges an additional language control model. It is trained to generate the correct target language token following the instructions. Our experiments demonstrate that our proposed language control model can achieve language expansion by eliminating language confusion. In our MuST-C and CoVoST-2 experiments, it shows up to 4.66 and 4.92 BLEU scores improvement, respectively. In addition, we demonstrate the use of our task arithmetic framework can expand to a language pair where neither paired ST training data nor a pre-trained ST model is available. We first synthesize the ST system from machine translation (MT) systems via task analogy, then merge the synthesized ST system to the existing ST model.