 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibriTTS-VI: A Public Corpus and Novel Methods for Efficient Voice Impression Control
Sep 19, 2025Fine-grained control over voice impressions (e.g., making a voice brighter or calmer) is a key frontier for creating more controllable text-to-speech. However, this nascent field faces two key challenges. The first is the problem of impression leakage, where the synthesized voice is undesirably influenced by the speaker's reference audio, rather than the separately specified target impression, and the second is the lack of a public, annotated corpus. To mitigate impression leakage, we propose two methods: 1) a training strategy that separately uses an utterance for speaker identity and another utterance of the same speaker for target impression, and 2) a novel reference-free model that generates a speaker embedding solely from the target impression, achieving the benefits of improved robustness against the leakage and the convenience of reference-free generation. Objective and subjective evaluations demonstrate a significant improvement in controllability. Our best method reduced the mean squared error of 11-dimensional voice impression vectors from 0.61 to 0.41 objectively and from 1.15 to 0.92 subjectively, while maintaining high fidelity. To foster reproducible research, we introduce LibriTTS-VI, the first public voice impression dataset released with clear annotation standards, built upon the LibriTTS-R corpus.
Evaluation of Instruction-Following Ability for Large Language Models on Story-Ending Generation
Jun 24, 2024Instruction-tuned Large Language Models (LLMs) have achieved remarkable performance across various benchmark tasks. While providing instructions to LLMs for guiding their generations is user-friendly, assessing their instruction-following capabilities is still unclarified due to a lack of evaluation metrics. In this paper, we focus on evaluating the instruction-following ability of LLMs in the context of story-ending generation, which requires diverse and context-specific instructions. We propose an automatic evaluation pipeline that utilizes a machine reading comprehension (MRC) model to determine whether the generated story-ending reflects instruction. Our findings demonstrate that our proposed metric aligns with human evaluation. Furthermore, our experiments confirm that recent open-source LLMs can achieve instruction-following performance close to GPT-3.5, as assessed through automatic evaluation.
SQ-VAE: Variational Bayes on Discrete Representation with Self-annealed Stochastic Quantization
May 16, 2022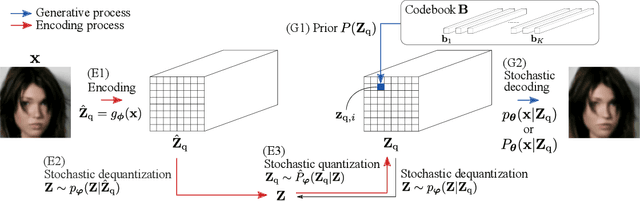

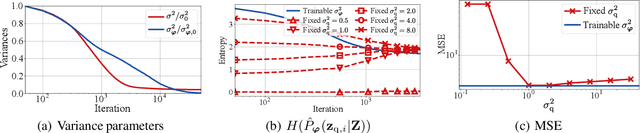
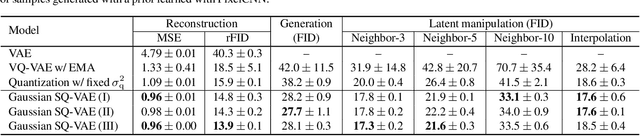
One noted issue of vector-quantized variational autoencoder (VQ-VAE) is that the learned discrete representation uses only a fraction of the full capacity of the codebook, also known as codebook collapse. We hypothesize that the training scheme of VQ-VAE, which involves some carefully designed heuristics, underlies this issue. In this paper, we propose a new training scheme that extends the standard VAE via novel stochastic dequantization and quantization, called stochastically quantized variational autoencoder (SQ-VAE). In SQ-VAE, we observe a trend that the quantization is stochastic at the initial stage of the training but gradually converges toward a deterministic quantization, which we call self-annealing. Our experiments show that SQ-VAE improves codebook utilization without using common heuristics. Furthermore, we empirically show that SQ-VAE is superior to VAE and VQ-VAE in vision- and speech-related tasks.
Context-Aware Dialog Re-Ranking for Task-Oriented Dialog Systems
Nov 28, 2018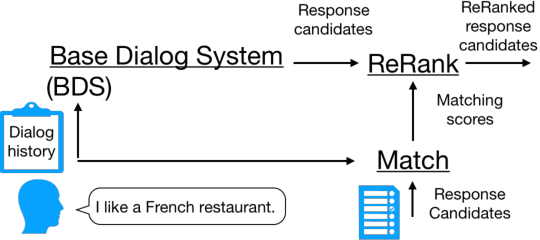

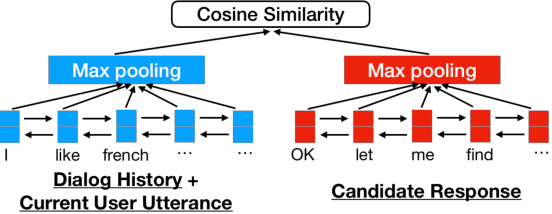

Dialog response ranking is used to rank response candidates by considering their relation to the dialog history. Although researchers have addressed this concept for open-domain dialogs, little attention has been focused on task-oriented dialogs. Furthermore, no previous studies have analyzed whether response ranking can improve the performance of existing dialog systems in real human-computer dialogs with speech recognition errors. In this paper, we propose a context-aware dialog response re-ranking system. Our system reranks responses in two steps: (1) it calculates matching scores for each candidate response and the current dialog context; (2) it combines the matching scores and a probability distribution of the candidates from an existing dialog system for response re-ranking. By using neural word embedding-based models and handcrafted or logistic regression-based ensemble models, we have improved the performance of a recently proposed end-to-end task-oriented dialog system on real dialogs with speech recognition errors.