 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPE: Visualise Pretty-much Everything
Oct 16, 2023Figurative and non-literal expressions are profoundly integrated in human communication. Visualising such expressions allow us to convey our creative thoughts, and evoke nuanced emotions. Recent text-to-image models like Stable Diffusion, on the other hand, struggle to depict non-literal expressions. Recent works primarily deal with this issue by compiling humanly annotated datasets on a small scale, which not only demands specialised expertise but also proves highly inefficient. To address this issue, we introduce ViPE: Visualise Pretty-much Everything. ViPE offers a series of lightweight and robust language models that have been trained on a large-scale set of lyrics with noisy visual descriptions that represent their implicit meaning. The synthetic visual descriptions are generated by GPT3.5 relying on neither human annotations nor images. ViPE effectively expresses any arbitrary piece of text into a visualisable description, enabling meaningful and high-quality image generation. We provide compelling evidence that ViPE is more robust than GPT3.5 in synthesising visual elaborations. ViPE also exhibits an understanding of figurative expressions comparable to human experts, providing a powerful and open-source backbone to many downstream applications such as music video and caption generation.
Visual Grounding of Inter-lingual Word-Embeddings
Sep 08, 2022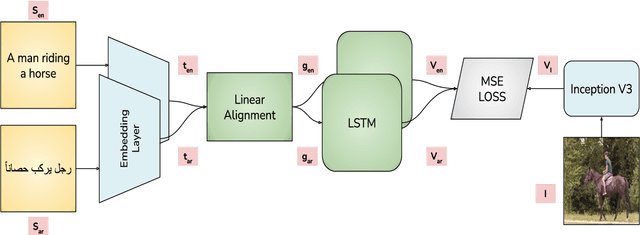
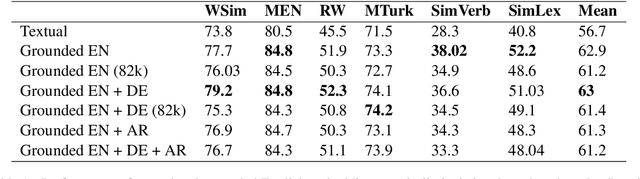
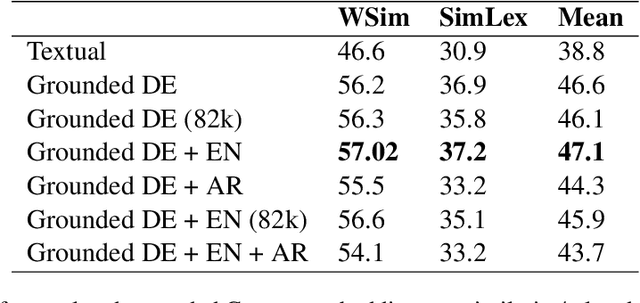
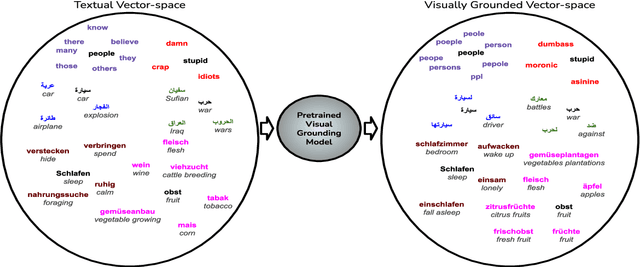
Visual grounding of Language aims at enriching textual representations of language with multiple sources of visual knowledge such as images and videos. Although visual grounding is an area of intense research, inter-lingual aspects of visual grounding have not received much attention. The present study investigates the inter-lingual visual grounding of word embeddings. We propose an implicit alignment technique between the two spaces of vision and language in which inter-lingual textual information interacts in order to enrich pre-trained textual word embeddings. We focus on three languages in our experiments, namely, English, Arabic, and German. We obtained visually grounded vector representations for these languages and studied whether visual grounding on one or multiple languages improved the performance of embeddings on word similarity and categorization benchmarks. Our experiments suggest that inter-lingual knowledge improves the performance of grounded embeddings in similar languages such as German and English. However, inter-lingual grounding of German or English with Arabic led to a slight degradation in performance on word similarity benchmarks. On the other hand, we observed an opposite trend on categorization benchmarks where Arabic had the most improvement on English. In the discussion section, several reasons for those findings are laid out. We hope that our experiments provide a baseline for further research on inter-lingual visual grounding.
Visual grounding of abstract and concrete words: A response to Günther et al. (2020)
Jun 30, 2022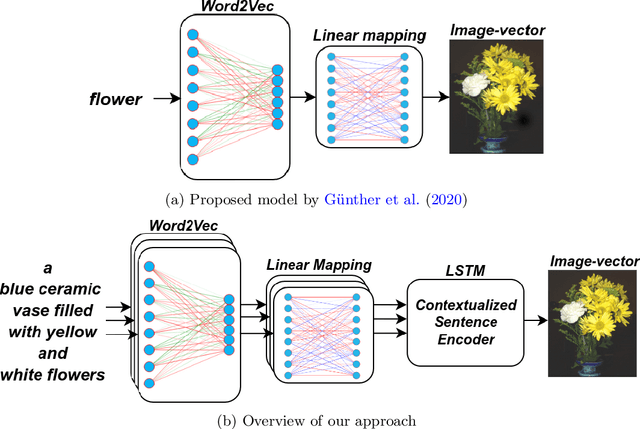

Current computational models capturing words' meaning mostly rely on textual corpora. While these approaches have been successful over the last decades, their lack of grounding in the real world is still an ongoing problem. In this paper, we focus on visual grounding of word embeddings and target two important questions. First, how can language benefit from vision in the process of visual grounding? And second, is there a link between visual grounding and abstract concepts? We investigate these questions by proposing a simple yet effective approach where language benefits from vision specifically with respect to the modeling of both concrete and abstract words. Our model aligns word embeddings with their corresponding visual representation without deteriorating the knowledge captured by textual distributional information. We apply our model to a behavioral experiment reported by G\"unther et al. (2020), which addresses the plausibility of having visual mental representations for abstract words. Our evaluation results show that: (1) It is possible to predict human behaviour to a large degree using purely textual embeddings. (2) Our grounded embeddings model human behavior better compared to their textual counterparts. (3) Abstract concepts benefit from visual grounding implicitly through their connections to concrete concepts, rather than from having corresponding visual representations.
Language with Vision: a Study on Grounded Word and Sentence Embeddings
Jun 17, 2022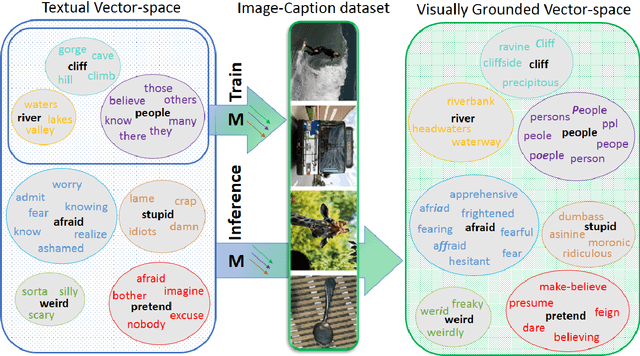
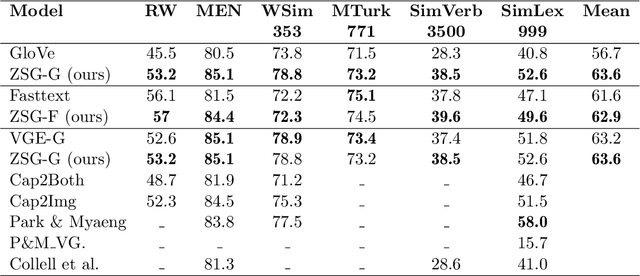
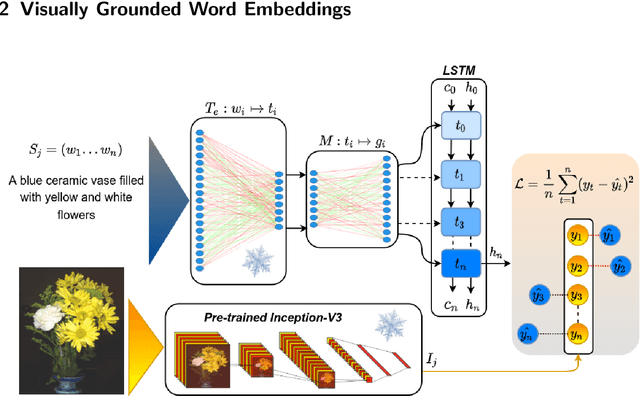

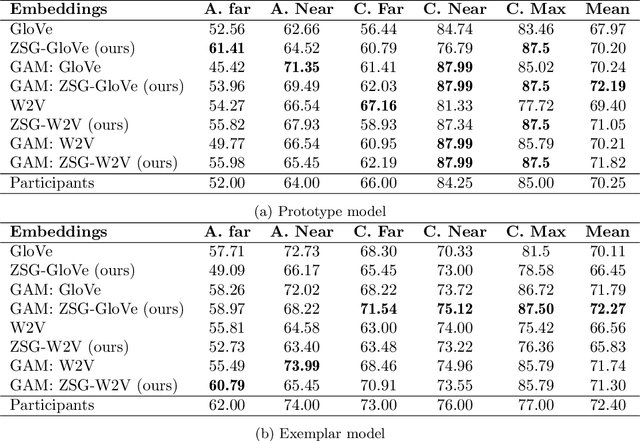
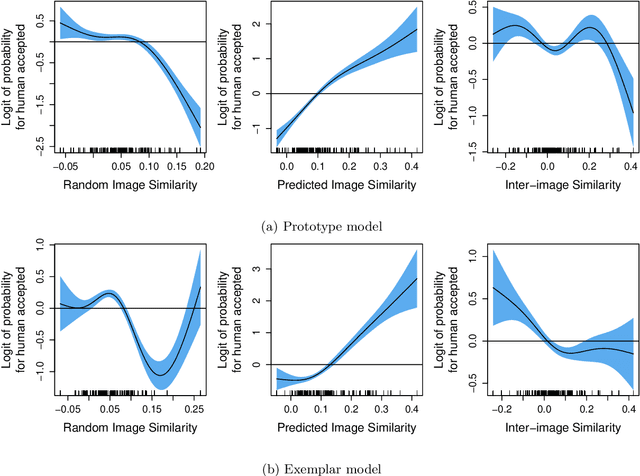
Language grounding to vision is an active field of research aiming to enrich text-based representations of word meanings by leveraging perceptual knowledge from vision. Despite many attempts at language grounding, it is still unclear how to effectively inject visual knowledge into the word embeddings of a language in such a way that a proper balance of textual and visual knowledge is maintained. Some common concerns are the following. Is visual grounding beneficial for abstract words or is its contribution only limited to concrete words? What is the optimal way of bridging the gap between text and vision? How much do we gain by visually grounding textual embeddings? The present study addresses these questions by proposing a simple yet very effective grounding approach for pre-trained word embeddings. Our model aligns textual embeddings with vision while largely preserving the distributional statistics that characterize word use in text corpora. By applying a learned alignment, we are able to generate visually grounded embeddings for unseen words, including abstract words. A series of evaluations on word similarity benchmarks shows that visual grounding is beneficial not only for concrete words, but also for abstract words. We also show that our method for visual grounding offers advantages for contextualized embeddings, but only when these are trained on corpora of relatively modest size. Code and grounded embeddings for English are available at https://github.com/Hazel1994/Visually_Grounded_Word_Embeddings_2.
Learning Zero-Shot Multifaceted Visually Grounded Word Embeddingsvia Multi-Task Training
Apr 15, 2021



Language grounding aims at linking the symbolic representation of language (e.g., words) into the rich perceptual knowledge of the outside world. The general approach is to embed both textual and visual information into a common space -the grounded space-confined by an explicit relationship between both modalities. We argue that this approach sacrifices the abstract knowledge obtained from linguistic co-occurrence statistics in the process of acquiring perceptual information. The focus of this paper is to solve this issue by implicitly grounding the word embeddings. Rather than learning two mappings into a joint space, our approach integrates modalities by determining a reversible grounded mapping between the textual and the grounded space by means of multi-task learning. Evaluations on intrinsic and extrinsic tasks show that our embeddings are highly beneficial for both abstract and concrete words. They are strongly correlated with human judgments and outperform previous works on a wide range of benchmarks. Our grounded embeddings are publicly available here.