 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistorical and psycholinguistic perspectives on morphological productivity: A sketch of an integrative approach
May 17, 2025In this study, we approach morphological productivity from two perspectives: a cognitive-computational perspective, and a diachronic perspective zooming in on an actual speaker, Thomas Mann. For developing the first perspective, we make use of a cognitive computational model of the mental lexicon, the discriminative lexicon model. For computational mappings between form and meaning to be productive, in the sense that novel, previously unencountered words, can be understood and produced, there must be systematicities between the form space and the semantic space. If the relation between form and meaning would be truly arbitrary, a model could memorize form and meaning pairings, but there is no way in which the model would be able to generalize to novel test data. For Finnish nominal inflection, Malay derivation, and English compounding, we explore, using the Discriminative Lexicon Model as a computational tool, to trace differences in the degree to which inflectional and word formation patterns are productive. We show that the DLM tends to associate affix-like sublexical units with the centroids of the embeddings of the words with a given affix. For developing the second perspective, we study how the intake and output of one prolific writer, Thomas Mann, changes over time. We show by means of an examination of what Thomas Mann is likely to have read, and what he wrote, that the rate at which Mann produces novel derived words is extremely low. There are far more novel words in his input than in his output. We show that Thomas Mann is less likely to produce a novel derived word with a given suffix the greater the average distance is of the embeddings of all derived words to the corresponding centroid, and discuss the challenges of using speaker-specific embeddings for low-frequency and novel words.
Visual grounding of abstract and concrete words: A response to Günther et al. (2020)
Jun 30, 2022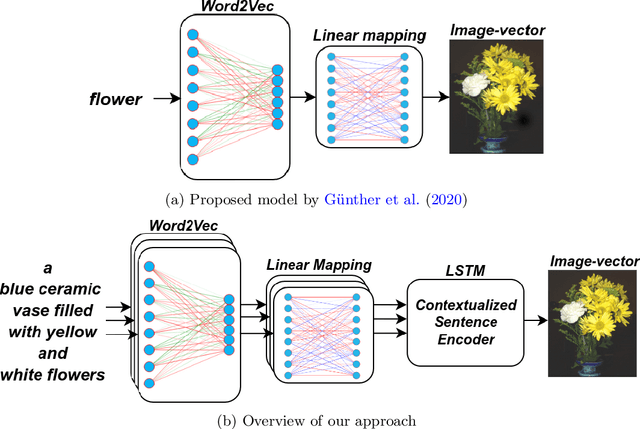

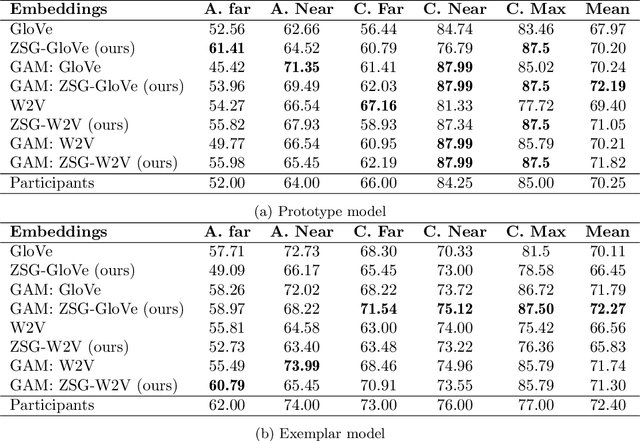
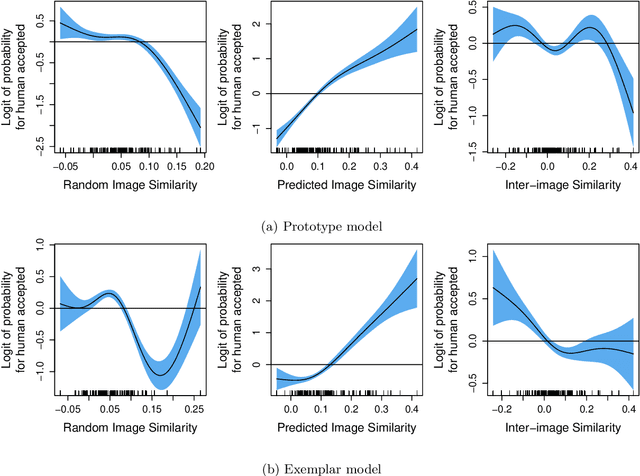
Current computational models capturing words' meaning mostly rely on textual corpora. While these approaches have been successful over the last decades, their lack of grounding in the real world is still an ongoing problem. In this paper, we focus on visual grounding of word embeddings and target two important questions. First, how can language benefit from vision in the process of visual grounding? And second, is there a link between visual grounding and abstract concepts? We investigate these questions by proposing a simple yet effective approach where language benefits from vision specifically with respect to the modeling of both concrete and abstract words. Our model aligns word embeddings with their corresponding visual representation without deteriorating the knowledge captured by textual distributional information. We apply our model to a behavioral experiment reported by G\"unther et al. (2020), which addresses the plausibility of having visual mental representations for abstract words. Our evaluation results show that: (1) It is possible to predict human behaviour to a large degree using purely textual embeddings. (2) Our grounded embeddings model human behavior better compared to their textual counterparts. (3) Abstract concepts benefit from visual grounding implicitly through their connections to concrete concepts, rather than from having corresponding visual representations.
Language with Vision: a Study on Grounded Word and Sentence Embeddings
Jun 17, 2022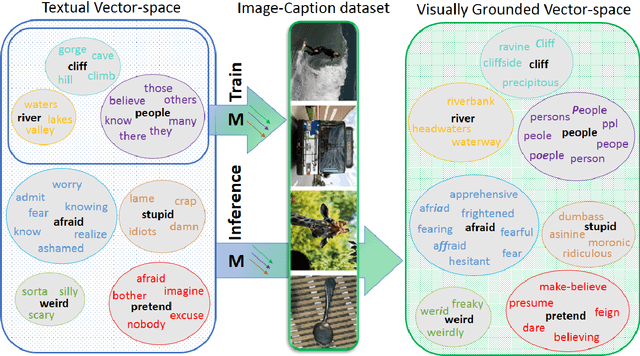
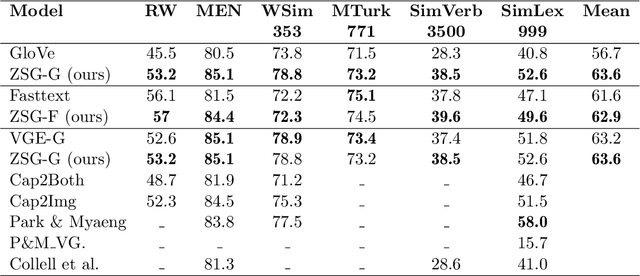
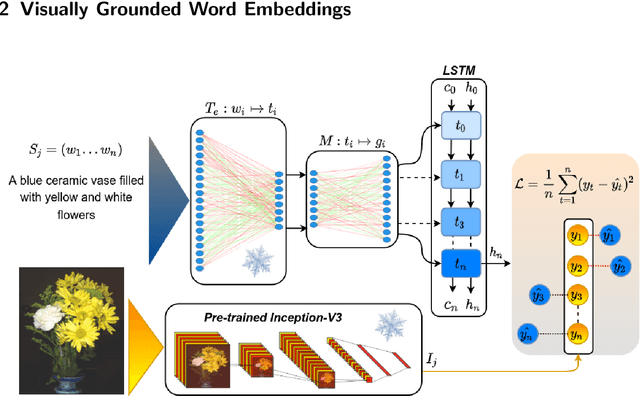

Language grounding to vision is an active field of research aiming to enrich text-based representations of word meanings by leveraging perceptual knowledge from vision. Despite many attempts at language grounding, it is still unclear how to effectively inject visual knowledge into the word embeddings of a language in such a way that a proper balance of textual and visual knowledge is maintained. Some common concerns are the following. Is visual grounding beneficial for abstract words or is its contribution only limited to concrete words? What is the optimal way of bridging the gap between text and vision? How much do we gain by visually grounding textual embeddings? The present study addresses these questions by proposing a simple yet very effective grounding approach for pre-trained word embeddings. Our model aligns textual embeddings with vision while largely preserving the distributional statistics that characterize word use in text corpora. By applying a learned alignment, we are able to generate visually grounded embeddings for unseen words, including abstract words. A series of evaluations on word similarity benchmarks shows that visual grounding is beneficial not only for concrete words, but also for abstract words. We also show that our method for visual grounding offers advantages for contextualized embeddings, but only when these are trained on corpora of relatively modest size. Code and grounded embeddings for English are available at https://github.com/Hazel1994/Visually_Grounded_Word_Embeddings_2.
Estimating Lexical Priors for Low-Frequency Syncretic Forms
Apr 24, 1995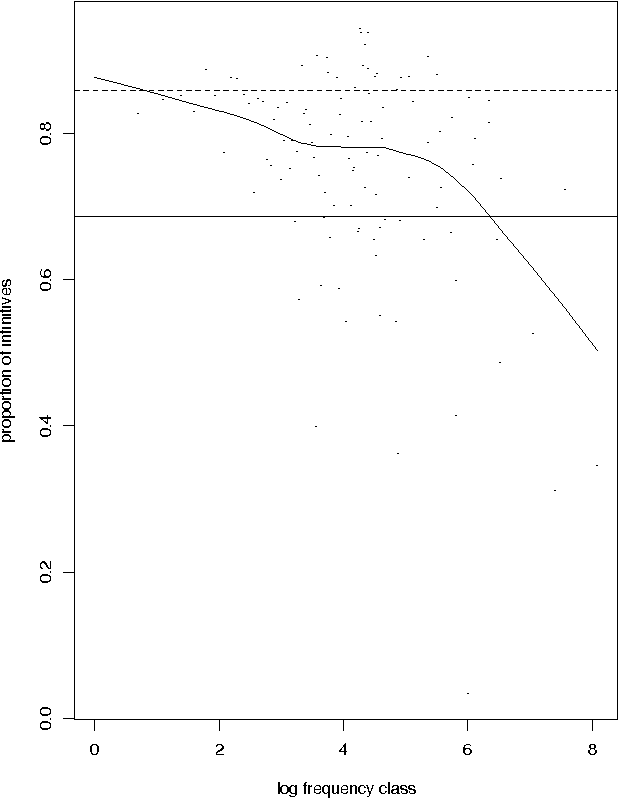
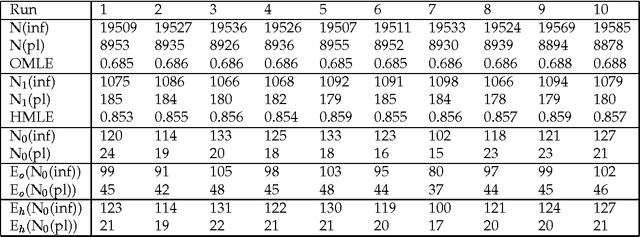
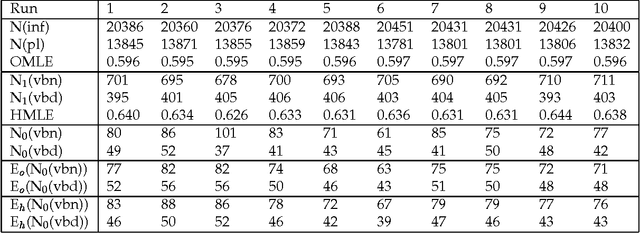
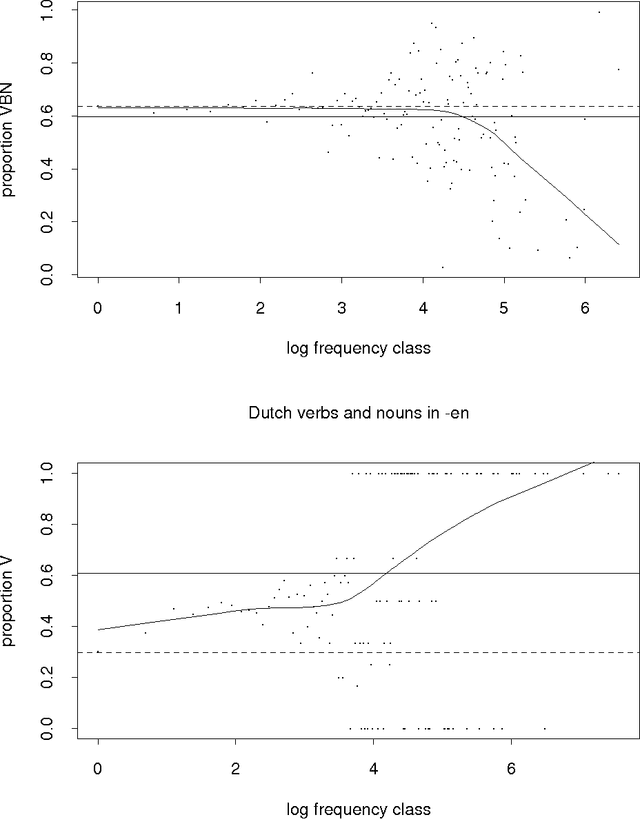
Given a previously unseen form that is morphologically n-ways ambiguous, what is the best estimator for the lexical prior probabilities for the various functions of the form? We argue that the best estimator is provided by computing the relative frequencies of the various functions among the hapax legomena --- the forms that occur exactly once in a corpus. This result has important implications for the development of stochastic morphological taggers, especially when some initial hand-tagging of a corpus is required: For predicting lexical priors for very low-frequency morphologically ambiguous types (most of which would not occur in any given corpus) one should concentrate on tagging a good representative sample of the hapax legomena, rather than extensively tagging words of all frequency ranges.