 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Lexical Priors for Low-Frequency Syncretic Forms
Paper and Code
Apr 24, 1995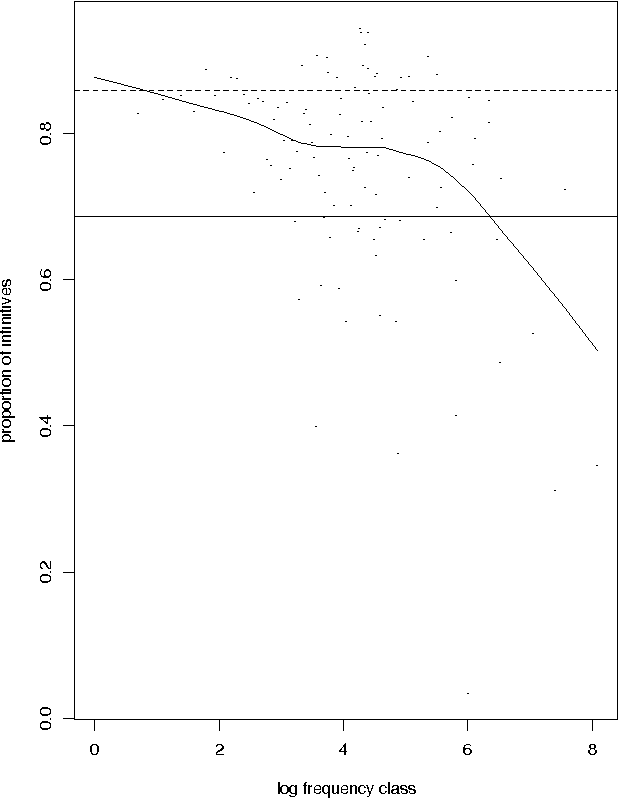
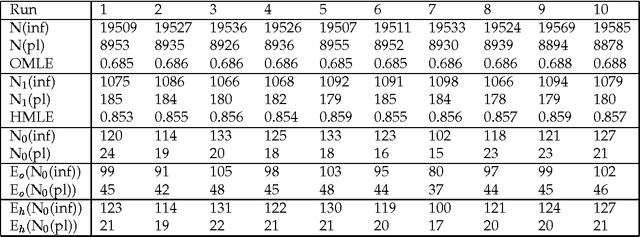
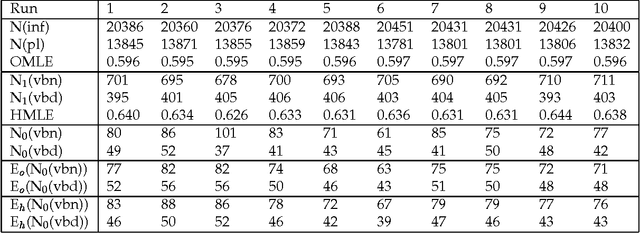
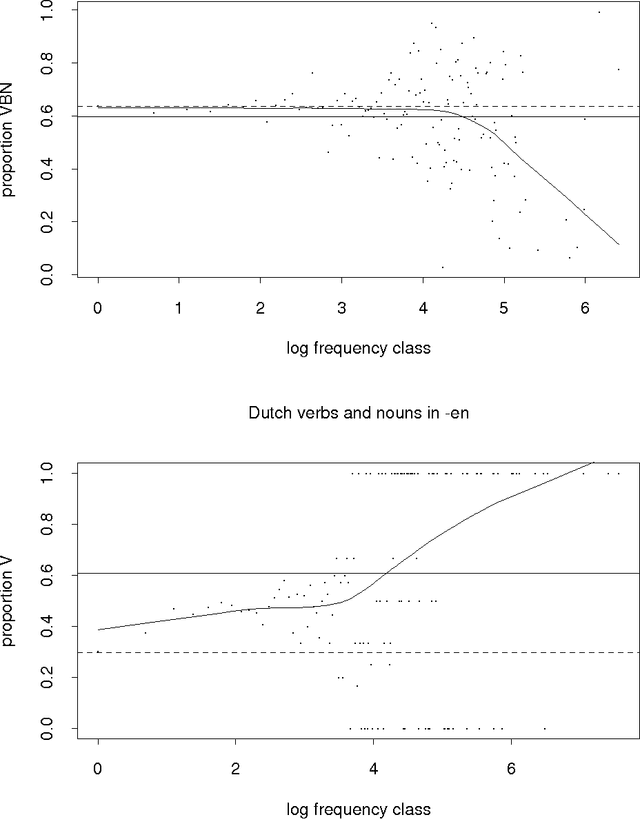
Given a previously unseen form that is morphologically n-ways ambiguous, what is the best estimator for the lexical prior probabilities for the various functions of the form? We argue that the best estimator is provided by computing the relative frequencies of the various functions among the hapax legomena --- the forms that occur exactly once in a corpus. This result has important implications for the development of stochastic morphological taggers, especially when some initial hand-tagging of a corpus is required: For predicting lexical priors for very low-frequency morphologically ambiguous types (most of which would not occur in any given corpus) one should concentrate on tagging a good representative sample of the hapax legomena, rather than extensively tagging words of all frequency ranges.