 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKamonBench: A Grammar-Based Dataset for Evaluating Compositional Factor Recovery in Vision-Language Models
May 13, 2026Kamon (family crests) are an important part of Japanese culture and a natural test case for compositional visual recognition: each crest combines a small number of symbolic choices, but the space of possible descriptions is sparse. We introduce KamonBench, a grammar-based image-to-structure benchmark with 20,000 synthetic composite crests and auxiliary component examples. Each composite crest is paired with a formal kamon description language - "kamon yōgo" - description, a segmented Japanese analysis, an English translation, and a non-linguistic program code. Because each synthetic crest is generated from known factors, namely container, modifier, and motif, KamonBench supports evaluation beyond caption-level accuracy: direct program-code factor metrics, controlled factor-pair recombination splits, counterfactual motif-sensitivity groups under fixed container-modifier contexts, and linear probes of factor accessibility. We include baseline results for a ViT encoder/Transformer decoder and two VGG n-gram decoders, with and without learned positional masks. KamonBench therefore provides a controlled testbed for sparse compositional visual recognition and factor recovery in vision-language models.
RePo: Language Models with Context Re-Positioning
Dec 16, 2025



In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_φ$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo.
BiPhone: Modeling Inter Language Phonetic Influences in Text
Jul 06, 2023A large number of people are forced to use the Web in a language they have low literacy in due to technology asymmetries. Written text in the second language (L2) from such users often contains a large number of errors that are influenced by their native language (L1). We propose a method to mine phoneme confusions (sounds in L2 that an L1 speaker is likely to conflate) for pairs of L1 and L2. These confusions are then plugged into a generative model (Bi-Phone) for synthetically producing corrupted L2 text. Through human evaluations, we show that Bi-Phone generates plausible corruptions that differ across L1s and also have widespread coverage on the Web. We also corrupt the popular language understanding benchmark SuperGLUE with our technique (FunGLUE for Phonetically Noised GLUE) and show that SoTA language understating models perform poorly. We also introduce a new phoneme prediction pre-training task which helps byte models to recover performance close to SuperGLUE. Finally, we also release the FunGLUE benchmark to promote further research in phonetically robust language models. To the best of our knowledge, FunGLUE is the first benchmark to introduce L1-L2 interactions in text.
Lenient Evaluation of Japanese Speech Recognition: Modeling Naturally Occurring Spelling Inconsistency
Jun 07, 2023


Word error rate (WER) and character error rate (CER) are standard metrics in Speech Recognition (ASR), but one problem has always been alternative spellings: If one's system transcribes adviser whereas the ground truth has advisor, this will count as an error even though the two spellings really represent the same word. Japanese is notorious for ``lacking orthography'': most words can be spelled in multiple ways, presenting a problem for accurate ASR evaluation. In this paper we propose a new lenient evaluation metric as a more defensible CER measure for Japanese ASR. We create a lattice of plausible respellings of the reference transcription, using a combination of lexical resources, a Japanese text-processing system, and a neural machine translation model for reconstructing kanji from hiragana or katakana. In a manual evaluation, raters rated 95.4% of the proposed spelling variants as plausible. ASR results show that our method, which does not penalize the system for choosing a valid alternate spelling of a word, affords a 2.4%-3.1% absolute reduction in CER depending on the task.
Beyond Arabic: Software for Perso-Arabic Script Manipulation
Jan 26, 2023



This paper presents an open-source software library that provides a set of finite-state transducer (FST) components and corresponding utilities for manipulating the writing systems of languages that use the Perso-Arabic script. The operations include various levels of script normalization, including visual invariance-preserving operations that subsume and go beyond the standard Unicode normalization forms, as well as transformations that modify the visual appearance of characters in accordance with the regional orthographies for eleven contemporary languages from diverse language families. The library also provides simple FST-based romanization and transliteration. We additionally attempt to formalize the typology of Perso-Arabic characters by providing one-to-many mappings from Unicode code points to the languages that use them. While our work focuses on the Arabic script diaspora rather than Arabic itself, this approach could be adopted for any language that uses the Arabic script, thus providing a unified framework for treating a script family used by close to a billion people.
Helpful Neighbors: Leveraging Neighbors in Geographic Feature Pronunciation
Oct 18, 2022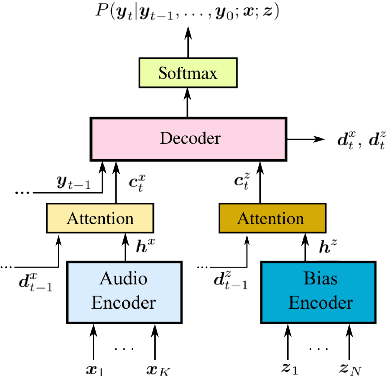

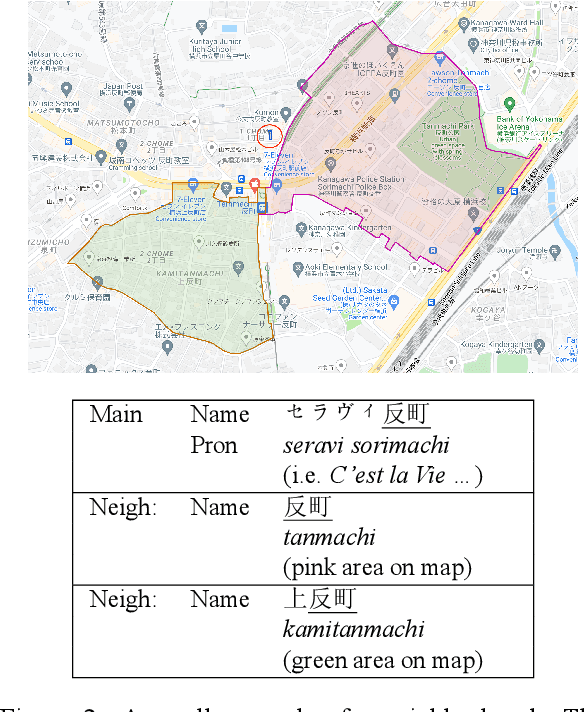
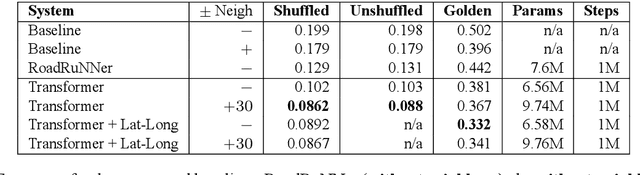
If one sees the place name Houston Mercer Dog Run in New York, how does one know how to pronounce it? Assuming one knows that Houston in New York is pronounced "how-ston" and not like the Texas city, then one can probably guess that "how-ston" is also used in the name of the dog park. We present a novel architecture that learns to use the pronunciations of neighboring names in order to guess the pronunciation of a given target feature. Applied to Japanese place names, we demonstrate the utility of the model to finding and proposing corrections for errors in Google Maps. To demonstrate the utility of this approach to structurally similar problems, we also report on an application to a totally different task: Cognate reflex prediction in comparative historical linguistics. A version of the code has been open-sourced (https://github.com/google-research/google-research/tree/master/cognate_inpaint_neighbors).
Structured abbreviation expansion in context
Oct 04, 2021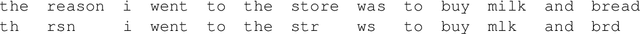
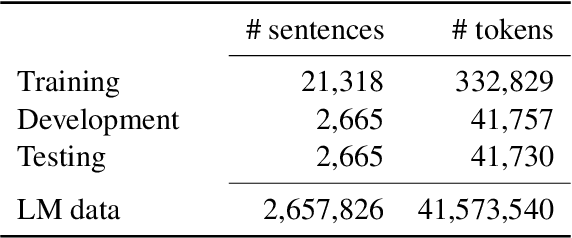
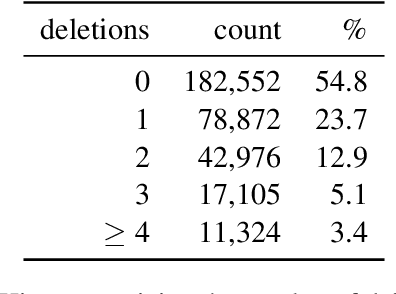
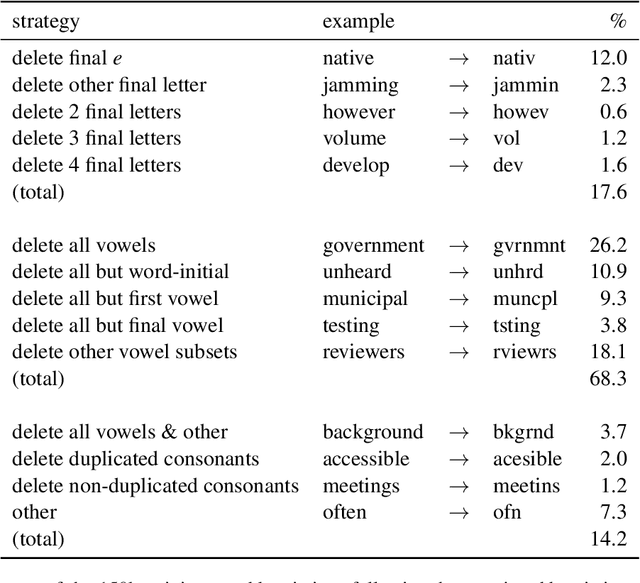
Ad hoc abbreviations are commonly found in informal communication channels that favor shorter messages. We consider the task of reversing these abbreviations in context to recover normalized, expanded versions of abbreviated messages. The problem is related to, but distinct from, spelling correction, in that ad hoc abbreviations are intentional and may involve substantial differences from the original words. Ad hoc abbreviations are productively generated on-the-fly, so they cannot be resolved solely by dictionary lookup. We generate a large, open-source data set of ad hoc abbreviations. This data is used to study abbreviation strategies and to develop two strong baselines for abbreviation expansion
Semi-supervised URL Segmentation with Recurrent Neural NetworksPre-trained on Knowledge Graph Entities
Nov 05, 2020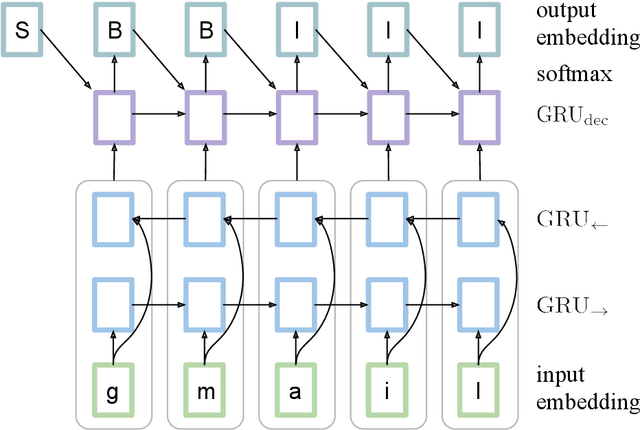



Breaking domain names such as openresearch into component words open and research is important for applications like Text-to-Speech synthesis and web search. We link this problem to the classic problem of Chinese word segmentation and show the effectiveness of a tagging model based on Recurrent Neural Networks (RNNs) using characters as input. To compensate for the lack of training data, we propose a pre-training method on concatenated entity names in a large knowledge database. Pre-training improves the model by 33% and brings the sequence accuracy to 85%.
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.
NEMO: Frequentist Inference Approach to Constrained Linguistic Typology Feature Prediction in SIGTYP 2020 Shared Task
Oct 12, 2020
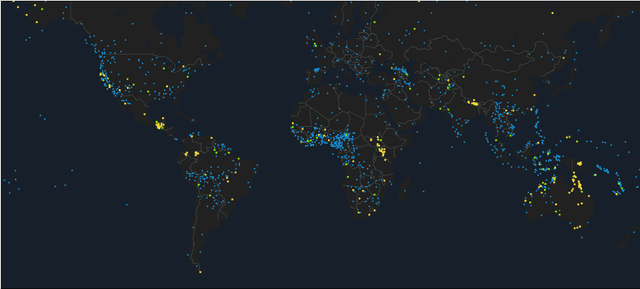
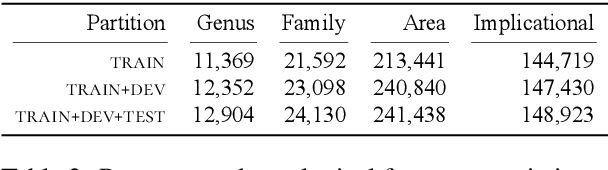
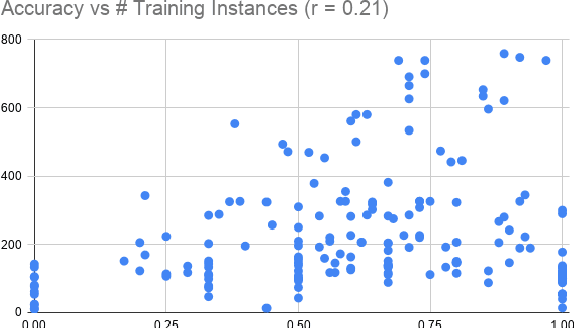
This paper describes the NEMO submission to SIGTYP 2020 shared task which deals with prediction of linguistic typological features for multiple languages using the data derived from World Atlas of Language Structures (WALS). We employ frequentist inference to represent correlations between typological features and use this representation to train simple multi-class estimators that predict individual features. We describe two submitted ridge regression-based configurations which ranked second and third overall in the constrained task. Our best configuration achieved the micro-averaged accuracy score of 0.66 on 149 test languages.