Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEMO: Frequentist Inference Approach to Constrained Linguistic Typology Feature Prediction in SIGTYP 2020 Shared Task
Paper and Code

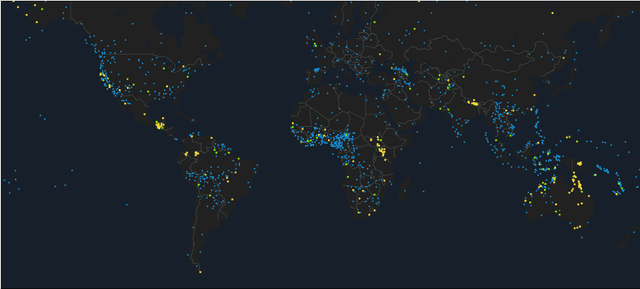
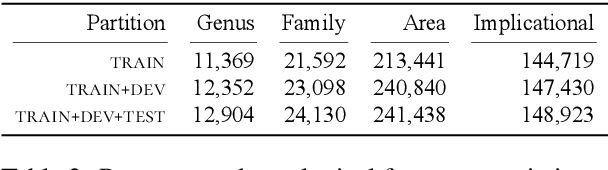
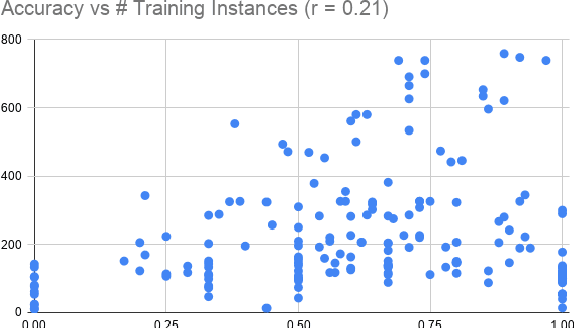
This paper describes the NEMO submission to SIGTYP 2020 shared task which deals with prediction of linguistic typological features for multiple languages using the data derived from World Atlas of Language Structures (WALS). We employ frequentist inference to represent correlations between typological features and use this representation to train simple multi-class estimators that predict individual features. We describe two submitted ridge regression-based configurations which ranked second and third overall in the constrained task. Our best configuration achieved the micro-averaged accuracy score of 0.66 on 149 test languages.
* To appear in Second Workshop on Computational Research in Linguistic
Typology (SIGTYP 2020) at 2020 Conference on Empirical Methods in Natural
Language Processing (EMNLP)
View paper on