Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised URL Segmentation with Recurrent Neural NetworksPre-trained on Knowledge Graph Entities
Paper and Code
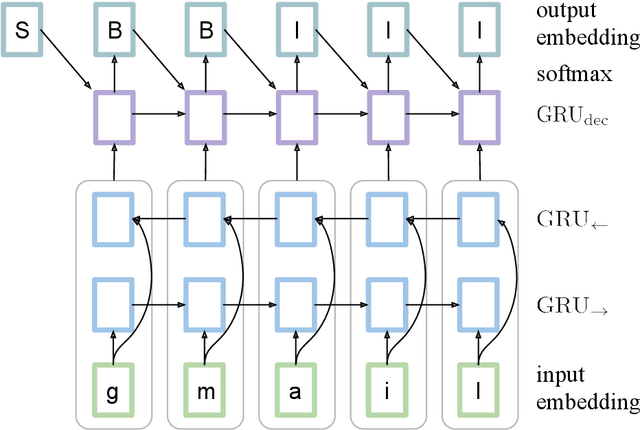



Breaking domain names such as openresearch into component words open and research is important for applications like Text-to-Speech synthesis and web search. We link this problem to the classic problem of Chinese word segmentation and show the effectiveness of a tagging model based on Recurrent Neural Networks (RNNs) using characters as input. To compensate for the lack of training data, we propose a pre-training method on concatenated entity names in a large knowledge database. Pre-training improves the model by 33% and brings the sequence accuracy to 85%.
View paper on