 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Agnostic Federated Averaging
Apr 06, 2021


In distributed learning settings such as federated learning, the training algorithm can be potentially biased towards different clients. Mohri et al. (2019) proposed a domain-agnostic learning algorithm, where the model is optimized for any target distribution formed by a mixture of the client distributions in order to overcome this bias. They further proposed an algorithm for the cross-silo federated learning setting, where the number of clients is small. We consider this problem in the cross-device setting, where the number of clients is much larger. We propose a communication-efficient distributed algorithm called Agnostic Federated Averaging (or AgnosticFedAvg) to minimize the domain-agnostic objective proposed in Mohri et al. (2019), which is amenable to other private mechanisms such as secure aggregation. We highlight two types of naturally occurring domains in federated learning and argue that AgnosticFedAvg performs well on both. To demonstrate the practical effectiveness of AgnosticFedAvg, we report positive results for large-scale language modeling tasks in both simulation and live experiments, where the latter involves training language models for Spanish virtual keyboard for millions of user devices.
Semi-supervised URL Segmentation with Recurrent Neural NetworksPre-trained on Knowledge Graph Entities
Nov 05, 2020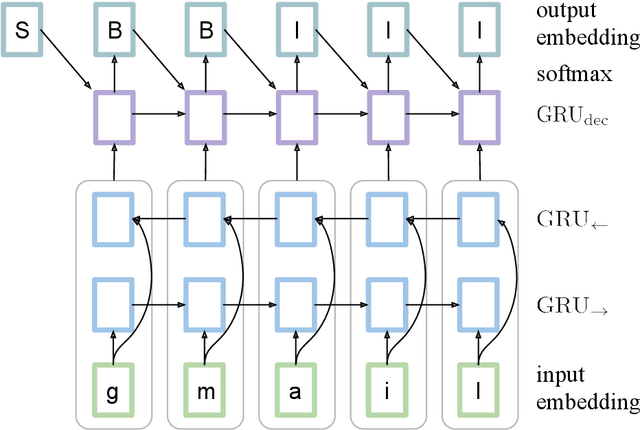



Breaking domain names such as openresearch into component words open and research is important for applications like Text-to-Speech synthesis and web search. We link this problem to the classic problem of Chinese word segmentation and show the effectiveness of a tagging model based on Recurrent Neural Networks (RNNs) using characters as input. To compensate for the lack of training data, we propose a pre-training method on concatenated entity names in a large knowledge database. Pre-training improves the model by 33% and brings the sequence accuracy to 85%.
Three Approaches for Personalization with Applications to Federated Learning
Feb 25, 2020



The standard objective in machine learning is to train a single model for all users. However, in many learning scenarios, such as cloud computing and federated learning, it is possible to learn one personalized model per user. In this work, we present a systematic learning-theoretic study of personalization. We propose and analyze three approaches: user clustering, data interpolation, and model interpolation. For all three approaches, we provide learning-theoretic guarantees and efficient algorithms for which we also demonstrate the performance empirically. All of our algorithms are model agnostic and work for any hypothesis class.