 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Cards: Purposeful and Transparent Dataset Documentation for Responsible AI
Apr 03, 2022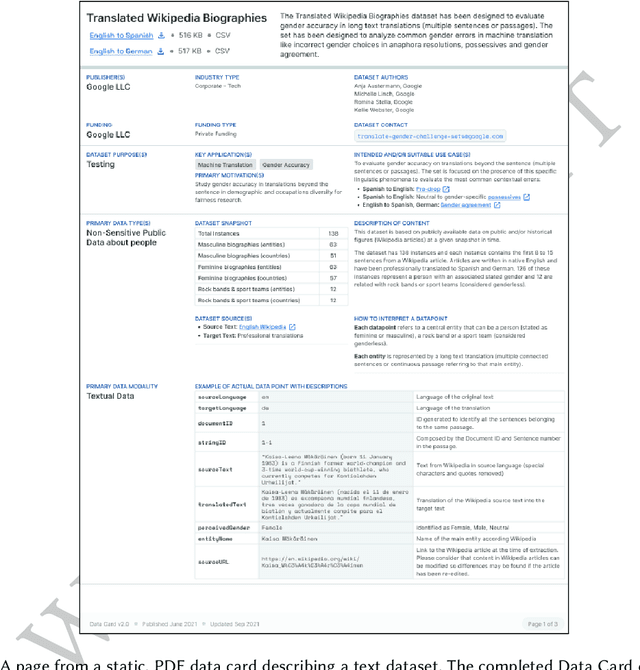
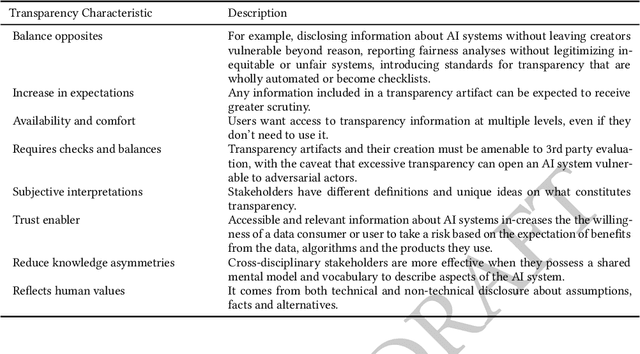
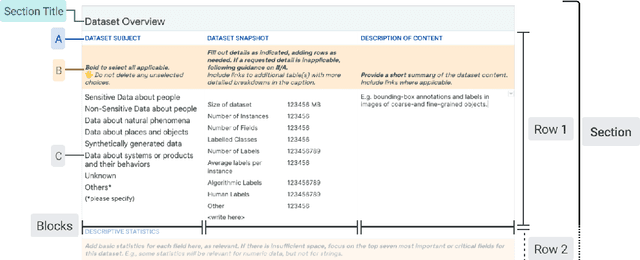

As research and industry moves towards large-scale models capable of numerous downstream tasks, the complexity of understanding multi-modal datasets that give nuance to models rapidly increases. A clear and thorough understanding of a dataset's origins, development, intent, ethical considerations and evolution becomes a necessary step for the responsible and informed deployment of models, especially those in people-facing contexts and high-risk domains. However, the burden of this understanding often falls on the intelligibility, conciseness, and comprehensiveness of the documentation. It requires consistency and comparability across the documentation of all datasets involved, and as such documentation must be treated as a user-centric product in and of itself. In this paper, we propose Data Cards for fostering transparent, purposeful and human-centered documentation of datasets within the practical contexts of industry and research. Data Cards are structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a dataset's lifecycle for responsible AI development. These summaries provide explanations of processes and rationales that shape the data and consequently the models, such as upstream sources, data collection and annotation methods; training and evaluation methods, intended use; or decisions affecting model performance. We also present frameworks that ground Data Cards in real-world utility and human-centricity. Using two case studies, we report on desirable characteristics that support adoption across domains, organizational structures, and audience groups. Finally, we present lessons learned from deploying over 20 Data Cards.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020

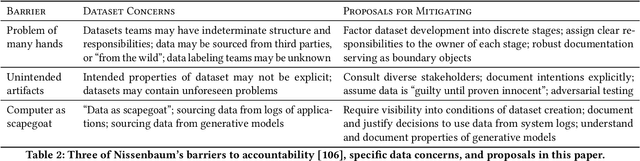
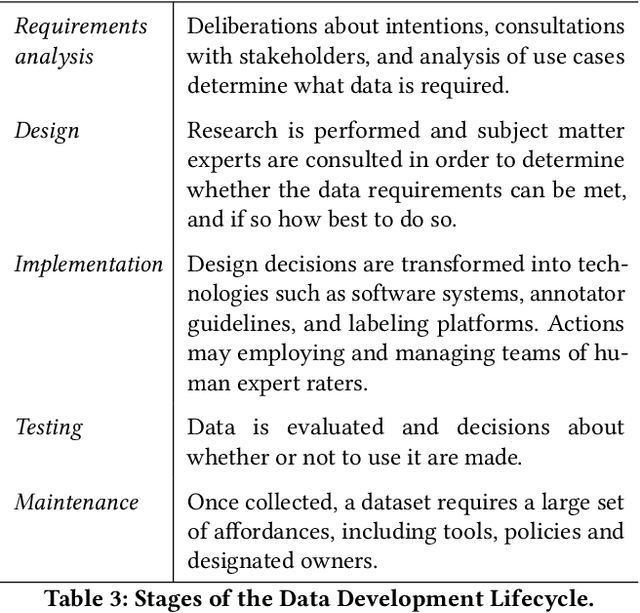
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.