 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Evaluation Gaps in Machine Learning Practice
May 11, 2022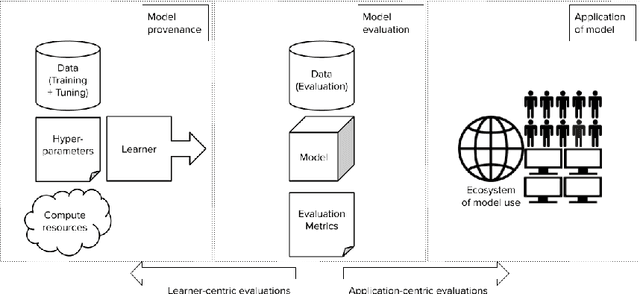

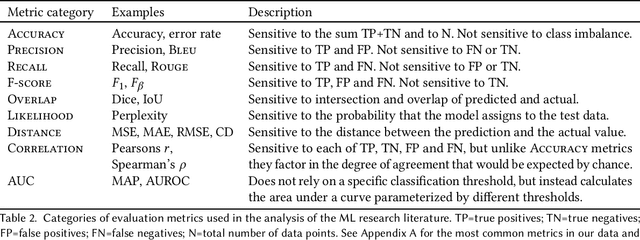
Forming a reliable judgement of a machine learning (ML) model's appropriateness for an application ecosystem is critical for its responsible use, and requires considering a broad range of factors including harms, benefits, and responsibilities. In practice, however, evaluations of ML models frequently focus on only a narrow range of decontextualized predictive behaviours. We examine the evaluation gaps between the idealized breadth of evaluation concerns and the observed narrow focus of actual evaluations. Through an empirical study of papers from recent high-profile conferences in the Computer Vision and Natural Language Processing communities, we demonstrate a general focus on a handful of evaluation methods. By considering the metrics and test data distributions used in these methods, we draw attention to which properties of models are centered in the field, revealing the properties that are frequently neglected or sidelined during evaluation. By studying these properties, we demonstrate the machine learning discipline's implicit assumption of a range of commitments which have normative impacts; these include commitments to consequentialism, abstractability from context, the quantifiability of impacts, the limited role of model inputs in evaluation, and the equivalence of different failure modes. Shedding light on these assumptions enables us to question their appropriateness for ML system contexts, pointing the way towards more contextualized evaluation methodologies for robustly examining the trustworthiness of ML models
Visual Identification of Problematic Bias in Large Label Spaces
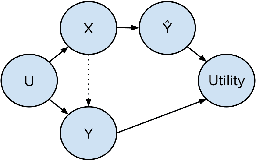
Jan 17, 2022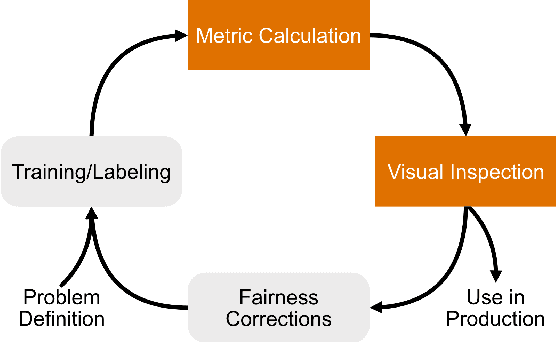

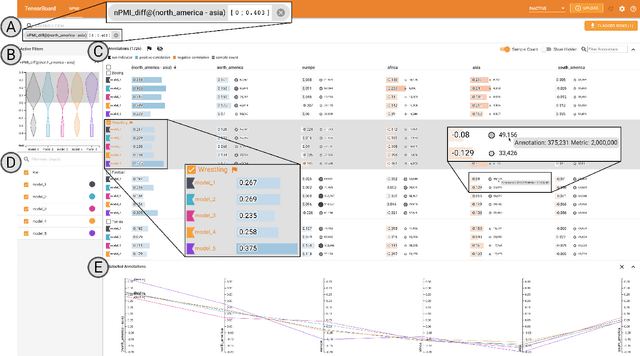
While the need for well-trained, fair ML systems is increasing ever more, measuring fairness for modern models and datasets is becoming increasingly difficult as they grow at an unprecedented pace. One key challenge in scaling common fairness metrics to such models and datasets is the requirement of exhaustive ground truth labeling, which cannot always be done. Indeed, this often rules out the application of traditional analysis metrics and systems. At the same time, ML-fairness assessments cannot be made algorithmically, as fairness is a highly subjective matter. Thus, domain experts need to be able to extract and reason about bias throughout models and datasets to make informed decisions. While visual analysis tools are of great help when investigating potential bias in DL models, none of the existing approaches have been designed for the specific tasks and challenges that arise in large label spaces. Addressing the lack of visualization work in this area, we propose guidelines for designing visualizations for such large label spaces, considering both technical and ethical issues. Our proposed visualization approach can be integrated into classical model and data pipelines, and we provide an implementation of our techniques open-sourced as a TensorBoard plug-in. With our approach, different models and datasets for large label spaces can be systematically and visually analyzed and compared to make informed fairness assessments tackling problematic bias.
Thinking Beyond Distributions in Testing Machine Learned Models
Dec 06, 2021Testing practices within the machine learning (ML) community have centered around assessing a learned model's predictive performance measured against a test dataset, often drawn from the same distribution as the training dataset. While recent work on robustness and fairness testing within the ML community has pointed to the importance of testing against distributional shifts, these efforts also focus on estimating the likelihood of the model making an error against a reference dataset/distribution. We argue that this view of testing actively discourages researchers and developers from looking into other sources of robustness failures, for instance corner cases which may have severe undesirable impacts. We draw parallels with decades of work within software engineering testing focused on assessing a software system against various stress conditions, including corner cases, as opposed to solely focusing on average-case behaviour. Finally, we put forth a set of recommendations to broaden the view of machine learning testing to a rigorous practice.
* Neural Information Processing System, NeurIPS 2021 workshop on Distribution Shifts
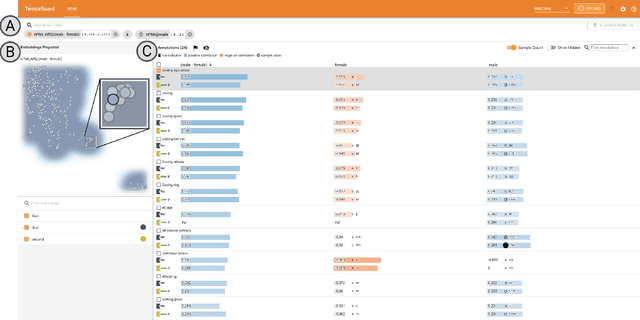
Measuring Model Biases in the Absence of Ground Truth
Mar 05, 2021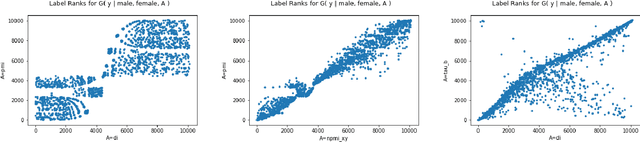
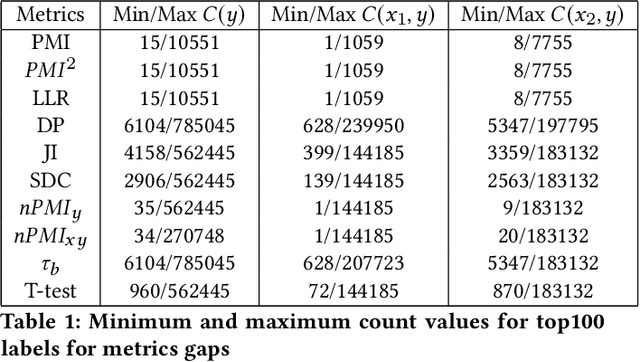

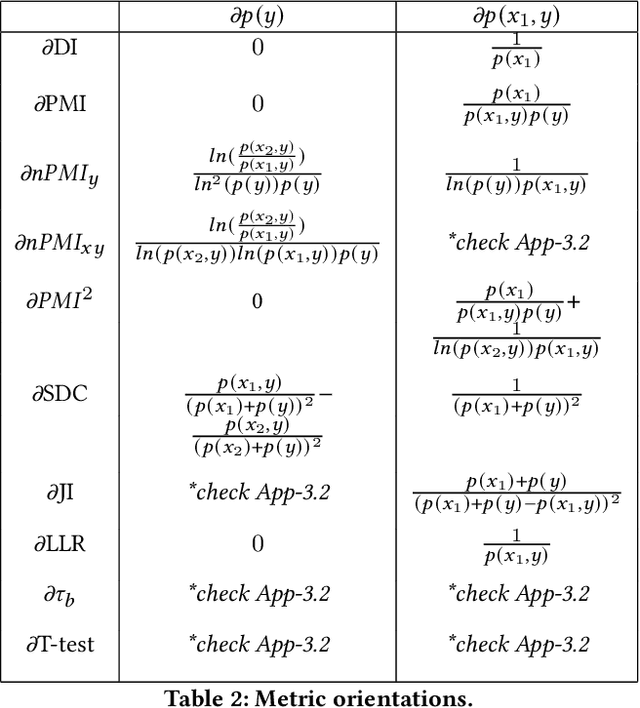
Recent advances in computer vision have led to the development of image classification models that can predict tens of thousands of object classes. Training these models can require millions of examples, leading to a demand of potentially billions of annotations. In practice, however, images are typically sparsely annotated, which can lead to problematic biases in the distribution of ground truth labels that are collected. This potential for annotation bias may then limit the utility of ground truth-dependent fairness metrics (e.g., Equalized Odds). To address this problem, in this work we introduce a new framing to the measurement of fairness and bias that does not rely on ground truth labels. Instead, we treat the model predictions for a given image as a set of labels, analogous to a 'bag of words' approach used in Natural Language Processing (NLP). This allows us to explore different association metrics between prediction sets in order to detect patterns of bias. We apply this approach to examine the relationship between identity labels, and all other labels in the dataset, using labels associated with 'male' and 'female') as a concrete example. We demonstrate how the statistical properties (especially normalization) of the different association metrics can lead to different sets of labels detected as having "gender bias". We conclude by demonstrating that pointwise mutual information normalized by joint probability (nPMI) is able to detect many labels with significant gender bias despite differences in the labels' marginal frequencies. Finally, we announce an open-sourced nPMI visualization tool using TensorBoard.
Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure
Oct 23, 2020

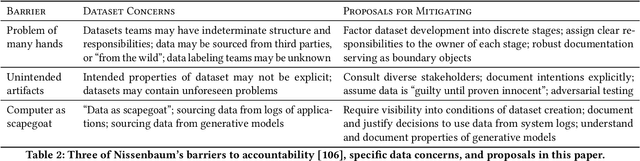
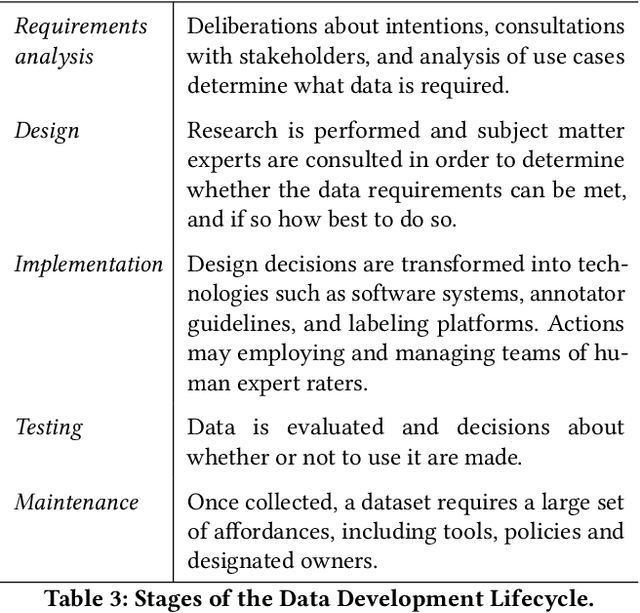
Rising concern for the societal implications of artificial intelligence systems has inspired demands for greater transparency and accountability. However the datasets which empower machine learning are often used, shared and re-used with little visibility into the processes of deliberation which led to their creation. Which stakeholder groups had their perspectives included when the dataset was conceived? Which domain experts were consulted regarding how to model subgroups and other phenomena? How were questions of representational biases measured and addressed? Who labeled the data? In this paper, we introduce a rigorous framework for dataset development transparency which supports decision-making and accountability. The framework uses the cyclical, infrastructural and engineering nature of dataset development to draw on best practices from the software development lifecycle. Each stage of the data development lifecycle yields a set of documents that facilitate improved communication and decision-making, as well as drawing attention the value and necessity of careful data work. The proposed framework is intended to contribute to closing the accountability gap in artificial intelligence systems, by making visible the often overlooked work that goes into dataset creation.